针对数据中台的数据泄露追溯方法及系统与流程
本发明属于信息安全,具体涉及一种针对数据中台的数据泄露追溯方法及系统。
背景技术:
1、随着经济技术的发展和人们生活水平的提高,电能已经成为了人们生产和生活中必不可少的二次能源,给人们的生产和生活带来了无尽的便利。因此,保证电能的稳定可靠供应,就成为了电力系统最重要的任务之一。
2、目前,电力系统的信息化水平越来越高;电力系统的信息安全也越来越重要。因此,对于电力系统而言,数据泄漏追溯技术就显得尤为重要。数据泄漏追溯技术集数据水印、日志分析及泄露源识别技术于一体,具有多维分析、可扩展、综合防护等特点;数据泄漏追溯技术还结合了访问控制、数据行为审计、脱敏等技术,从而成为了数据安全防护体系的重要一环。
3、在现有的环境下,通过采用特定数据水印,可以对数据泄露进行部分追溯,满足基础的数据安全需求。然而,随着数据类型及数据组件类型逐渐增多,单一性的、机械性的数据水印在较多场景下并不能成功溯源,且风险识别不能随着既有泄露事实进行动态优化,从而无法对数据泄露风险实现灵活、动态的防护。
4、针对现有的单一数据水印方案,较好的解决方法包括逐个梳理数据源、通过数据源的数据类型及存储组件类型逐个指定附着水印类型、定期更新数据源台账并逐一进行调整等。但是,这类方法仍需要人工梳理与查找,工作十分繁琐,而且往往无法及时、动态地调整策略,易造成数据安全防护可靠性差的问题。而且,现有的数据水印方案也无法自适应的对不同安全等级要求的数据进行动态、敏捷的防护。
技术实现思路
1、本发明的目的之一在于提供一种可靠性高、准确性好且客观科学的针对数据中台的数据泄露追溯方法。
2、本发明的目的之二在于提供一种实现所述针对数据中台的数据泄露追溯方法的系统。
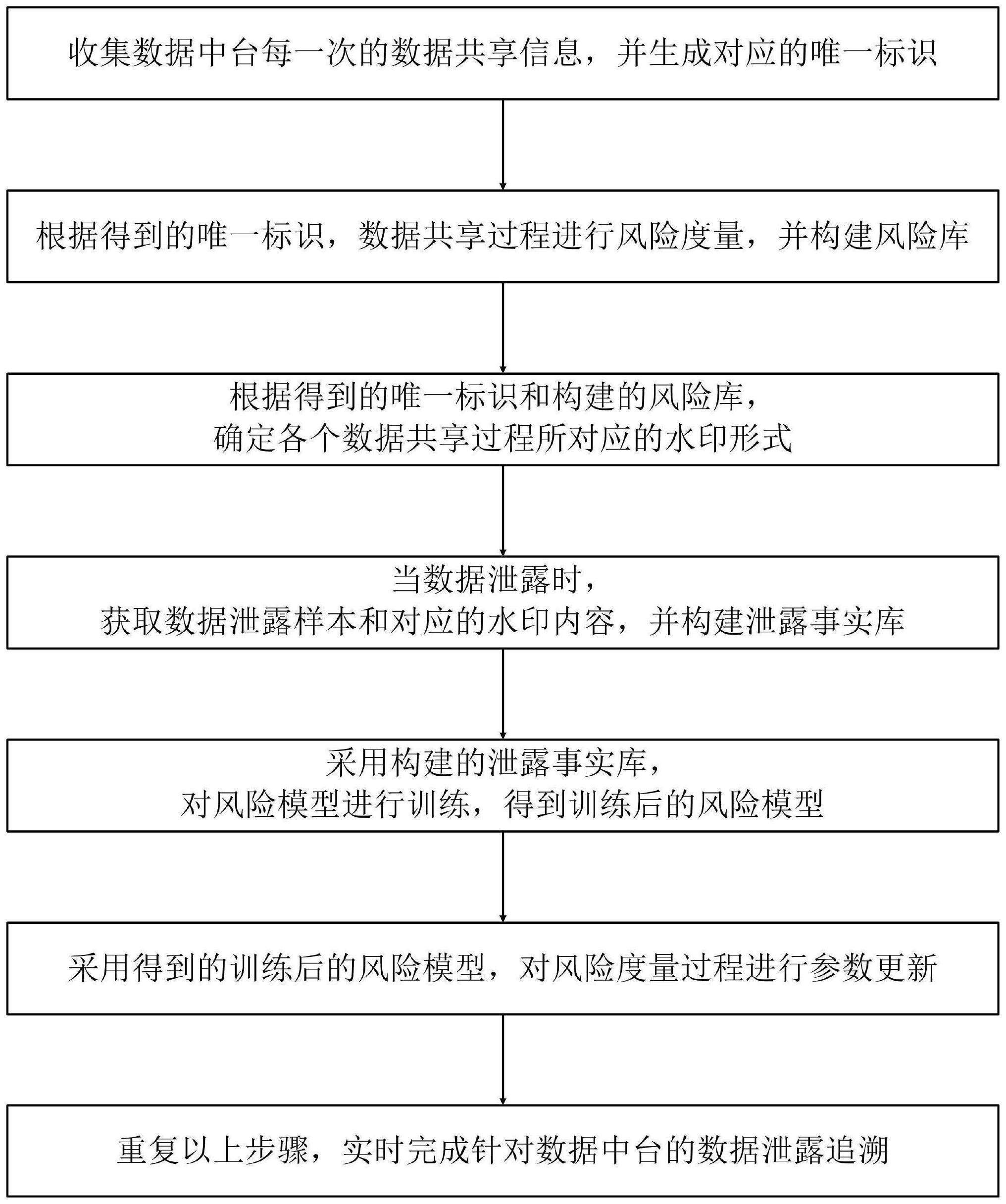
3、本发明提供的这种针对数据中台的数据泄露追溯方法,包括如下步骤:
4、s1.收集数据中台每一次的数据共享信息,并生成对应的唯一标识;
5、s2.根据步骤s1得到的唯一标识,对数据共享过程进行风险度量,并构建风险库;
6、s3.根据步骤s1得到的唯一标识和步骤s2构建的风险库,确定各个数据共享过程所对应的水印形式;
7、s4.当数据泄露时,获取数据泄露样本和对应的水印内容,并构建泄露事实库;
8、s5.采用步骤s4构建的泄露事实库,对风险模型进行训练,得到训练后的风险模型;
9、s6.采用步骤s5得到的训练后的风险模型,对步骤s2中的风险度量过程进行参数更新;
10、s7.重复步骤s1~s6,实时完成针对数据中台的数据泄露追溯。
11、步骤s1所述的收集数据中台每一次的数据共享信息,并生成对应的唯一标识,具体包括如下步骤:
12、采用python的log service服务,将数据中台的数据共享日志数据发送到日志服务中,分析得到每一次数据共享的详细要素;所述的详细要素包括数据接收方信息、共享表信息、数据接收方ip信息、数据使用用途和范围信息、数据共享形式信息和共享数据存储量信息;
13、通过正则表达式的方式,提取数据共享日志的数据信息,并形成日志筛选要素库{ej},其中ej=[idj,elej],idj为数据共享事件的id,elej为日志筛选要素且elej={rjk,tjk,ijk,ujk,mjk,sjk},rjk为数据接收方信息的正则表达式,tjk为共享表信息的正则表达式,ijk为数据接收方ip信息的正则表达式,ujk为数据使用用途和范围信息的正则表达式,mjk为数据共享形式信息的正则表达式,sjk为共享数据存储量信息的正则表达式;
14、根据日志筛选要素库{ej},形成对应关系库{rj},其中rj=[ej,uj],uj为数据共享事件的唯一id信息;
15、其中,使用python语言uuid库的uuid4方法生成唯一标识;采用python语言numpy库的vectorize方法对数据进行存储。
16、步骤s2所述的根据步骤s1得到的唯一标识,对数据共享过程进行风险度量,并构建风险库,具体包括如下步骤:
17、通过python的acsclient和commonrequest库,将每一个数据共享请求转化为唯一标识和共享事件信息的映射关系;利用ots数据库构造字典表data_sharing_events,用于存储所有产生的映射关系;
18、使用python语言numpy的multiply函数、scikit-learn库的kneighborsclassifier分类器,对各个要素赋予权重值,并计算对应的风险分数值;所述的要素包括数据暴露面、数据敏感程度和数据接收方安全合规能力完备程度;
19、采用python语言pandas库的dataframe类创建数据框,并存入ots数据库中字典表中。
20、所述的风险分数值,具体为采用如下步骤计算得到:
21、采用如下算式计算得到风险值grj:
22、
23、其中,α为隐私风险评估模型与差分隐私风险度量模型计分的权重值;elerj为风险要素;wj为对应风险要素设定的初始权值;ε为差分隐私风险度量中隐私保护的强度值,用于表示允许的隐私泄露程度;δ为共享的数据集大小,可以利用共享数据的存储量来表示;grj为利用隐私风险评估模型及差分隐私风险度量模型结合要素权值计算得到的风险值。
24、步骤s3所述的根据步骤s1得到的唯一标识和步骤s2构建的风险库,确定各个数据共享过程所对应的水印形式,具体包括如下步骤:
25、数据共享形式包括:对内以表形式共享、对内以api接口形式共享、对内以离线文件形式共享、对内以实时数据流形式共享、对外以表形式共享、对外以api接口形式共享、对外以离线文件形式共享和对外以实时数据流形式共享;
26、水印形式包括隐形水印、最低位变换水印和零宽字符水印;
27、构建水印筛选规则库{ruj},其中ruj=[foj,wj],foj为数据共享形式,wj为对应的水印形式的正则表达式;
28、在数据共享事件触发时,对当前的数据共享事件与水印筛选规则库{ruj}进行匹配:
29、首先根据当前的数据共享事件所对应的数据共享形式,与水印筛选规则库{ruj}进行匹配:
30、若直接匹配成功,则给出匹配的数据共享形式所对应的水印形式,并将当前的数据共享事件与对应的水印形式进行联合保存,并构建水印方式库{fj};
31、若未匹配成功,则进行模糊匹配:采用如下算式计算对应的模糊匹配度sij:
32、
33、式中nj为水印筛选规则库{ruj}中的数据共享形式的数量;fok为水印筛选规则库{ruj}中的数据共享形式;idj为当前的数据共享事件所对应的数据共享形式;dis(fok,idj)为计算fok和idj之间的levenshtein距离函数;max(dis(fok,idj))为dis(fok,idj)中的最大值;
34、对模糊匹配度进行判断:若sij<t,则判定当前的数据共享事件所对应的数据共享形式为idj;若sij≥t,则则认为模糊匹配失败,则将当前的数据共享事件所对应的水印形式直接设定为隐形水印;将当前的数据共享事件与对应的水印形式进行联合保存,并构建水印方式库{fj};
35、最终,得到水印方式库{fj}。
36、步骤s4所述的当数据泄露时,获取数据泄露样本和对应的水印内容,并构建泄露事实库,具体包括如下步骤:
37、通过python语言scapy库的sniff函数捕获网络数据包,并采用show函数获取数据泄露样本;
38、数据泄露样本为json或excel、csv、txt文本格式,通过python语言scapy库的summary方法获取对应数据的水印内容;
39、通过python语言sqlalchemy库的execute方法获取数据泄露样本,并通过orm模型解析数据泄露样本来获取对应数据水印内容并解析数据水印,利用ots数据库构造字典表leaking,构建泄露事实库;
40、所述的泄露事实库中的每一个元素,均包括数据接收方信息、数据共享时间信息、数据共享涉及的表或接口信息、共享数据存储量信息和数据接收方ip信息。
41、步骤s5所述的采用步骤s4构建的泄露事实库,对风险模型进行训练,得到训练后的风险模型,具体包括如下步骤:
42、将步骤s4构建的泄露事实库中的每个元素,转换成向量ql;其中,ql={rl,tl,sl,sal,il},rl为数据接收方信息,tl为数据共享时间信息,sl为数据共享涉及的表或接口信息,sal为共享数据存储量信息,il为数据接收方ip信息;
43、构建风险模型:风险模型为循环神经网络模型,包括三层;第一层为输入层,用于将输入的离散特征转换为连续向量表示;第二层为lstm层,用于对连续向量进行特征提取;第三层为输出层,用于将输入的特征信息转换为概率值并输出;第一层包括64个神经元;第二层包括64个lstm单元,并采用tanh激活函数;第三层包括1个神经元,并采用sigmoid激活函数;
44、训练时,采用kl散度损失函数作为训练的损失函数,采用radam优化器对模型进行训练;
45、训练完成后,得到最终的训练后的风险模型。
46、步骤s6所述的采用步骤s5得到的训练后的风险模型,对步骤s2中的风险度量过程进行参数更新,具体包括如下步骤:
47、采用tensorflow库的partial_fit函数对差分隐私风险度量模型权重的权值、共享数据量要素的权值、数据共享形式要素的权值(线上/线下/导出/推送)、共享表信息的权值(含表字段敏感程度)、数据接受ip的权值进行更新。
48、本发明还提供了一种实现所述针对数据中台的数据泄露追溯方法的系统,包括数据获取模块、风险库构建模块、水印确定模块、泄露事实库构建模块、模型训练模块、参数更新模块和循环模块;数据获取模块、风险库构建模块、水印确定模块、泄露事实库构建模块、模型训练模块、参数更新模块和循环模块依次串接,循环模块的输出端同时连接数据获取模块和风险库构建模块;数据获取模块用于收集数据中台每一次的数据共享信息,并生成对应的唯一标识,并将数据上传风险库构建模块;风险库构建模块用于根据接收到的数据,对数据共享过程进行风险度量,并构建风险库,并将数据上传水印确定模块;水印确定模块用于根据接收到的数据,确定各个数据共享过程所对应的水印形式,并将数据上传泄露事实库构建模块;泄露事实库构建模块用于根据接收到的数据,当数据泄露时,获取数据泄露样本和对应的水印内容,并构建泄露事实库,并将数据上传模型训练模块;模型训练模块用于根据接收到的数据,采用构建的泄露事实库,对风险模型进行训练,得到训练后的风险模型,并将数据上传参数更新模块;参数更新模块用于根据接收到的数据,采用得到的训练后的风险模型,对风险度量过程进行参数更新,并将数据上传循环模块;循环模块用于根据接收到的数据,控制上述模块重复工作,实时完成针对数据中台的数据泄露追溯。
49、本发明提供的这种针对数据中台的数据泄露追溯方法及系统,通过分析数据共享的各要素生成唯一标识,对数据共享事件分析风险大小,建立水印筛选规则库和水印方式库、并构建精确与模糊匹配模式,自动生成适应的水印形式,对数据共享事件自动形成合适的水印形式;而且本发明能够通过数据水印信息进行对应的解析判断,最后通过既定泄露事实依据深度学习模型调整风险识别参数,实现风险识别的实时优化;因此本发明的可靠性高、准确性好且客观科学。
- 还没有人留言评论。精彩留言会获得点赞!