基于语言模型的分类方法、装置、电子设备及存储介质与流程
本技术涉及语言分类模型领域,尤其涉及一种基于语言模型的分类方法、装置、电子设备及存储介质。
背景技术:
1、大规模语言模型是利用类似transformer框架的语言类分析模型,具有强大的语义理解能力,可以捕捉文本中的语义关系和上下文信息。但是,对于数据集中存在的稀疏样本或异常样本,大规模语言模型可能面临较大的挑战,其性能可能受到数据分布不均匀或数据缺失的影响,并且大规模语言模型的性能通常受限于训练数据的规模和质量,如果数据集规模较小或者不具代表性,模型的表现可能受到限制。
技术实现思路
1、本技术实施例提供一种基于语言模型的分类方法、装置、电子设备及存储介质,可以在语义理解的基础上,通过相似度计算更准确地对文本进行分类、聚类或相似度匹配。
2、第一方面,本技术实施例提供了一种基于语言模型的分类方法,所述方法包括:
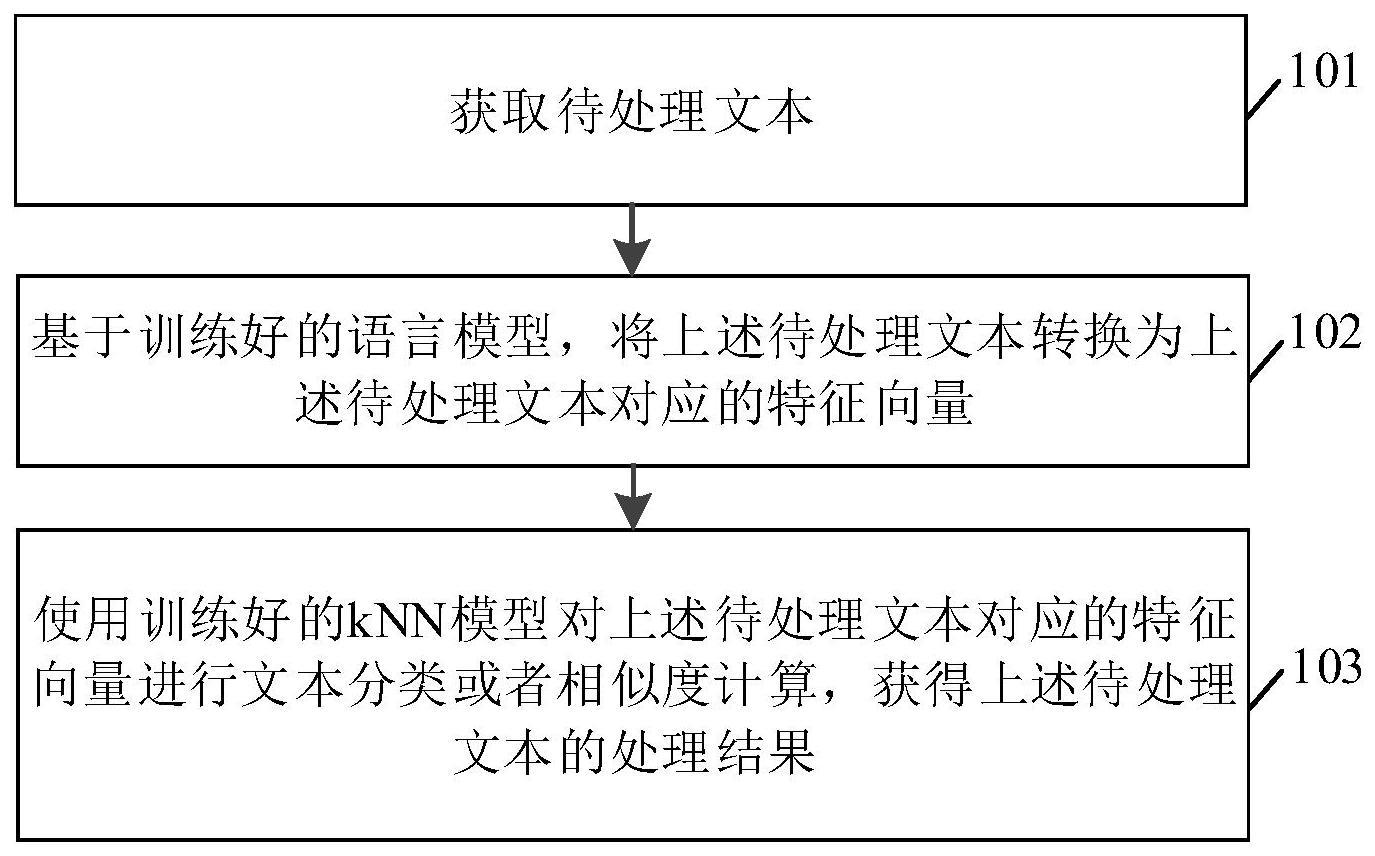
3、获取待处理文本;
4、基于训练好的语言模型,将所述待处理文本转换为所述待处理文本对应的特征向量;
5、使用训练好的knn模型对所述待处理文本对应的特征向量进行文本分类或者相似度计算,获得所述待处理文本的处理结果。
6、在一种可选的实施方式中,所述方法还包括:
7、对待处理样本数据进行预处理,获得样本数据;
8、基于所述样本数据,对语言模型进行训练,获得所述训练好的语言模型,输出文本数据集;
9、将所述文本数据集中的每个文本转换为对应的特征向量;
10、将归一化后的所述特征向量作为样本数据,训练knn模型,获得所述训练好的knn模型。
11、在一种可选的实施方式中,所述对待处理样本数据进行预处理,获得样本数据,包括:
12、将所述待处理样本数据中的原始文本进行分词处理,获得单词或字符的输入序列,并去除标点符号,转换为小写字母。
13、在一种可选的实施方式中,所述语言模型中采用自注意力机制;
14、所述自注意力机制的处理步骤包括:
15、将所述输入序列中的每个单词或字符进行嵌入表示;
16、将所述嵌入表示分别传入三个线性变换层,生成查询向量、键向量和值向量;
17、根据所述查询向量、所述键向量和所述值向量进行注意力计算。
18、在一种可选的实施方式中,所述方法还包括:
19、构建词汇表,其中,将所述样本数据中出现的所有单词或字符进行索引编号;
20、初始化嵌入矩阵,所述嵌入矩阵的维度为:所述词汇表的大小乘以嵌入维度,所述嵌入维度为将所述单词或字符嵌入到的连续向量空间的维度;
21、所述将所述输入序列中的每个单词或字符进行嵌入表示,包括:
22、对于所述输入序列中的每个单词或字符,通过查询所述词汇表中的索引找到对应的嵌入向量,从所述嵌入矩阵中获取相应索引的行向量作为嵌入表示。
23、在一种可选的实施方式中,所述根据所述查询向量、所述键向量和所述值向量进行注意力计算,包括:
24、根据所述查询向量和所述键向量计算查询-键相似度;
25、基于缩放因子缩小所述查询-键相似度,获得缩放后的查询-键相似度;
26、对所述缩放后的查询-键相似度进行softmax归一化,以得到注意力权重;
27、将所述注意力权重与所述值向量进行加权求和,得到加权值向量。
28、在一种可选的实施方式中,所述语言模型中采用前馈神经网络;
29、所述前馈神经网络的输入是经过所述自注意力机制得到的每个位置的表示,所述前馈神经网络的输出为经过线性变换和激活函数处理后的表示。
30、可选的,所述基于所述样本数据,对语言模型进行训练,包括:
31、将所述语言模型的输出与对应的样本数据的标签进行比较,计算损失函数的值;
32、通过反向传播算法计算所述损失函数对所述语言模型的参数的梯度;
33、根据所述梯度,使用优化算法对所述语言模型的参数进行更新,以使得所述损失函数逐渐减小;
34、重复以上步骤,通过多次迭代训练,直到所述损失函数收敛。
35、第二方面,本技术实施例提供了一种基于语言模型的分类装置,包括:
36、获取模块,用于获取待处理文本;
37、处理模块,用于基于训练好的语言模型,将所述待处理文本转换为所述待处理文本对应的特征向量;
38、所述处理模块,还用于使用训练好的knn模型对所述待处理文本对应的特征向量进行文本分类或者相似度计算,获得所述待处理文本的处理结果。
39、可选的,所述基于语言模型的分类装置还包括训练模块,用于:
40、对待处理样本数据进行预处理,获得样本数据;
41、基于所述样本数据,对语言模型进行训练,获得所述训练好的语言模型,输出文本数据集;
42、将所述文本数据集中的每个文本转换为对应的特征向量;
43、将归一化后的所述特征向量作为样本数据,训练knn模型,获得所述训练好的knn模型。
44、可选的,所述训练模块,具体用于:
45、将所述待处理样本数据中的原始文本进行分词处理,获得单词或字符的输入序列,并去除标点符号,转换为小写字母。
46、可选的,所述语言模型中采用自注意力机制;
47、所述处理模块,还用于:
48、将所述输入序列中的每个单词或字符进行嵌入表示;
49、将所述嵌入表示分别传入三个线性变换层,生成查询向量、键向量和值向量;
50、根据所述查询向量、所述键向量和所述值向量进行注意力计算。
51、可选的,所述训练模块还用于:
52、构建词汇表,其中,将所述样本数据中出现的所有单词或字符进行索引编号;
53、初始化嵌入矩阵,所述嵌入矩阵的维度为:所述词汇表的大小乘以嵌入维度,所述嵌入维度为将所述单词或字符嵌入到的连续向量空间的维度;
54、所述处理模块,还用于:
55、对于所述输入序列中的每个单词或字符,通过查询所述词汇表中的索引找到对应的嵌入向量,从所述嵌入矩阵中获取相应索引的行向量作为嵌入表示。
56、可选的,所述处理模块,具体用于:
57、根据所述查询向量和所述键向量计算查询-键相似度;
58、基于缩放因子缩小所述查询-键相似度,获得缩放后的查询-键相似度;
59、对所述缩放后的查询-键相似度进行softmax归一化,以得到注意力权重;
60、将所述注意力权重与所述值向量进行加权求和,得到加权值向量。
61、可选的,所述语言模型中采用前馈神经网络;
62、所述前馈神经网络的输入是经过所述自注意力机制得到的每个位置的表示,所述前馈神经网络的输出为经过线性变换和激活函数处理后的表示。
63、可选的,所述训练模块,具体用于:
64、将所述语言模型的输出与对应的样本数据的标签进行比较,计算损失函数的值;
65、通过反向传播算法计算所述损失函数对所述语言模型的参数的梯度;
66、根据所述梯度,使用优化算法对所述语言模型的参数进行更新,以使得所述损失函数逐渐减小;
67、重复以上步骤,通过多次迭代训练,直到所述损失函数收敛。
68、第三方面,本技术实施例还提供了一种电子设备,包括处理器、输入设备、输出设备和存储器,所述处理器、输入设备、输出设备和存储器相互连接,其中,所述存储器用于存储计算机程序,所述计算机程序包括程序指令,所述处理器被配置用于调用所述程序指令,执行如第一方面及其任一种可能的实施方式所述的方法。
69、第四方面,本技术实施例提供了一种计算机存储介质,所述计算机存储介质存储有计算机程序,所述计算机程序包括程序指令,所述程序指令当被处理器执行时使所述处理器执行上述第一方面及其任一种可能的实施方式的方法。
70、本技术实施例通过获取待处理文本;基于训练好的语言模型,将所述待处理文本转换为所述待处理文本对应的特征向量;使用训练好的knn模型对所述待处理文本对应的特征向量进行文本分类或者相似度计算,获得所述待处理文本的处理结果;结合了语言模型的语义理解能力和knn模型的相似度计算能力,提供更全面和精确的文本处理和分析能力,可以在语义理解的基础上,通过相似度计算更准确地对文本进行分类、聚类或相似度匹配等。
- 还没有人留言评论。精彩留言会获得点赞!