基于智能问答关联垂直问题域于开发问题域的方法及系统与流程
本发明涉及ai nlp智能客服领域,具体地说是一种基于智能问答关联垂直问题域于开发问题域的方法及系统。
背景技术:
1、在ai nlp智能客服应用方面,多数场景下会需要特定垂直领域的知识问答,这是基础,在此之上,也需要开放问题域知识问答。如何将开放问题域和特定垂直领域知识结合是一个切实的需求。
2、开放问题域与特定领域结合的实现方式目前通用方法具体如下:
3、①将特定领域知识放到开放模型中做微调训练,然后将整合好的模型做统一部署,终端通过api的方式发起请求、推理、返回结果。该方法存在的问题为:如果使用开放问题域大模型做微调训练,那么私有化部署是一个无法完成的任务。部署资源需求大、硬件条件要求高;如果使用小规模开放问题域做开放域问题回答,由于训练集较小导致效果不理想。
4、②多领域知识模型通过分词、命名实体识别来指定由某个垂直领域模型回答问题,如果都不包含则使用开放问题与回答。该方法存在的问题为:由于需要先进性分词抽取、命名实体识别工作,再进行推理,导致响应速度慢、相关性、相似性低、需要人工标注等问题。对于小规模特定垂直领域模型来说,体验不佳。
5、故如何兼顾特定垂直领域问答和开发领域问答效果与部署可行性的需求,同时兼顾不同领域问答快速响应的需求是目前亟待解决的技术问题。
技术实现思路
1、本发明的技术任务是提供一种基于智能问答关联垂直问题域于开发问题域的方法及系统,来解决如何兼顾特定垂直领域问答和开发领域问答效果与部署可行性的需求,同时兼顾不同领域问答快速响应的需求的问题。
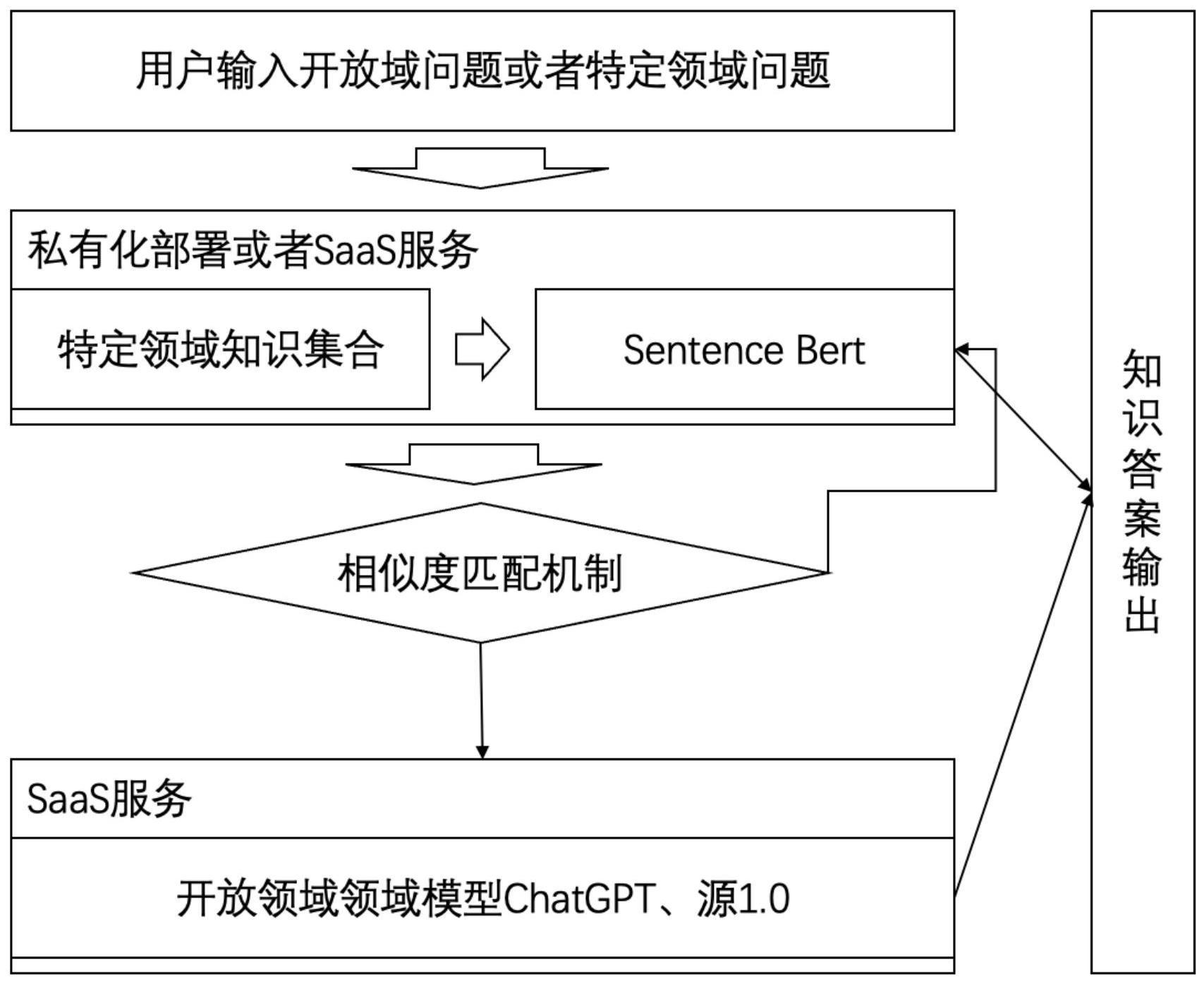
2、本发明的技术任务是按以下方式实现的,一种基于智能问答关联垂直问题域于开发问题域的方法,该方法具体如下:
3、知识归集及结构化处理:将特征领域知识进行归集及结构化处理;
4、微调训练:将归集及结构化处理的数据输入到sentence bert模型进行微调训练,得到特定垂直领域知识智能问答模型,并将特定垂直领域知识智能问答模型私有化部署或者提供saas服务;
5、获取开放问题域知识模型:通过saas服务获取得到开放问题域知识模型;
6、相似度匹配:将问题输入到特定垂直领域知识智能问答模型,并将该问题与特定垂直领域知识问答库中的相似问题进行相似度匹配,即计算相似度值,并将相似度值进行降序排序后,再与设定阈值进行比较:
7、若相似度值小于设定阈值,则该问题为非特定领域知识,进而将该问题通过开发问题域知识模型通用api或saas服务做出解答;
8、若相似度值大于等于设定阈值,则该问题为特定垂直领域,进而将该问题通过特定垂直领域知识智能问答模型做出解答。
9、作为优选,微调训练具体如下:
10、构建数据集:获取垂直领域问答数据构建数据集;
11、构建正样本和负样本:利用数据集分别构建正样本和负样本;
12、构建训练数据集:训练时,输入正样本相似性数值设置为1,即(x1,y1)=1;负样本设置为0,即(x1,y2)=0;x1为原始问题内容;y1为正样本问题内容;y2为负样本问题内容;每一个数据集中正样本为1-2份,负样本为5份;将训练数据集输入到特定垂直领域知识智能问答模型中进行相似性训练;
13、设定训练参数:learning rate=2e-5;epoch=3。
14、更优地,构建正样本和负样本具体如下:
15、从数据集中随机抽取指定份数问答对数据;
16、通过人工标注形式,将每个样本标注1-2份正样本;
17、每一个样本都从指定份数问答对数据中随机抽取5份作为负样本。
18、作为优选,相似度匹配具体如下:
19、相似度值计算公式具体如下:
20、
21、其中,a和b为两个n维向量;a1到an为向量a的其中任一维度数值,b1到bn为向量b的其中任一维度数值;a为[a1,a2,...,an];b为[b1,b2,...,bn];两个方向完全相同的向量的余弦相似度值为1,两个彼此相对的向量的余弦相似度值为-1;
22、通过softmax函数(激活函数)将余弦结果[-1,1]数据映射到[0,1]之间;其中,softmax函数公式具体如下:
23、
24、其中,z表示为一个向量;zi和zj是向量中的一个元素;exp(zi)表示指数函数求值。
25、作为优选,将相似度值进行降序排序后,再与设定阈值进行比较具体如下:
26、若第一个相似度值接近1,并且降序排序后第一个相似度值后面的相似度值与1有0.1的差距,则直接返回召回的第一个问题的答案;
27、若召回的所有问题相似度值两两相差在0.3内,并且相似度值均高于0.85,则将召回的问题一并返回给用户,由用户选择真实的问题;
28、若召回的问题相似性与设定阈值相比较都在0.1范围内,则提示用户该问题召回效果不佳,该问题为若干问题中的其中一个,请用户自行做出选择。
29、作为优选,特征领域知识包括智慧民生领域知识、智慧教育领域知识以及智慧医疗领域知识。
30、作为优选,开放问题域知识模型采用开放的源1.0或chatgpt。
31、一种于智能问答关联垂直问题域于开发问题域的系统,该系统包括:
32、知识处理模块,用于将特征领域知识进行归集及结构化处理;
33、微调训练模块,用于将归集及结构化处理的数据输入到sentence bert模型进行微调训练,得到特定垂直领域知识智能问答模型,并将特定垂直领域知识智能问答模型私有化部署或者提供saas服务;
34、获取模块,用于通过saas服务获取得到开放问题域知识模型;
35、相似度匹配模块,用于将问题输入到特定垂直领域知识智能问答模型,并将该问题与特定垂直领域知识问答库中的相似问题进行相似度匹配,即计算相似度值,并将相似度值进行降序排序后,再与设定阈值进行比较:
36、若相似度值小于设定阈值,则该问题为非特定领域知识,进而将该问题通过开发问题域知识模型通用api或saas服务做出解答;
37、若相似度值大于等于设定阈值,则该问题为特定垂直领域,进而将该问题通过特定垂直领域知识智能问答模型做出解答。
38、一种电子设备,包括:存储器和至少一个处理器;
39、其中,所述存储器上存储有计算机程序;
40、所述至少一个处理器执行所述存储器存储的计算机程序,使得所述至少一个处理器执行如上述的基于智能问答关联垂直问题域于开发问题域的方法。
41、一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序可被处理器执行以实现如上述的基于智能问答关联垂直问题域于开发问题域的方法。
42、本发明的基于智能问答关联垂直问题域于开发问题域的方法及系统具有以下优点:
43、(一)本发明通过特定垂直领域智能问答模型(sentence bert)做输入问题相似度匹配,如果检测到匹配度高于某个阈值(如0.5),则使用特定垂直领域智能问答模型做出应答,否则使用开放问题域模型进行回答,达到关联特定问题域模型与开放问题域模型的目的;
44、(二)本发明使用开放的源1.0、chatgpt等大规模预训练模型,作为开放领域知识智能问答模型,开放领域知识智能问答模型优势在于理解自然语义优秀、训练集包含了大量网络数据资源,在开放域知识问答、文本生成方面表现优秀,但是由于开放领域知识智能问答模型巨大导致无法私有化部署,只有通过saas提供服务;
45、(三)本发明将特定领域知识收集,使用sentence bert模型做微调训练,得到特定垂直领域知识智能问答模型;sentence bert模型优势在于比较两个句子的相似程度,同时推理速度更快,对于某垂直领域较小规模问题集有响应速度快、可私有化部署的优势;
46、(四)本发明兼顾了特定垂直领域问答和开放领域问答效果与部署可行性的需求,兼顾了不同领域问答快速响应的需求;
47、(五)本发明加入了通过相似度匹配关联特定领域知识模型与开放领域知识模型的方法;在用户输入一个问题之后,会先通过特定领域模型做问题相似度匹配,如果相似度匹配低于某个阈值,则需要使用saas部署方式的开放问题域进行问题的解答,然后将答案传递给用户;如果相似度等于或者大于某个阈值,则需要使用私有化部署或者saas方式的特定领域知识模型对此问题进行解答,然后将答案传递给用户。
- 还没有人留言评论。精彩留言会获得点赞!