面向社交媒体内容的多目标群体分类方法与流程
本发明属于计算机,具体涉及一种面向社交媒体内容的多目标群体分类方法,用于立场检测和舆情分析。
背景技术:
1、随着信息技术的快速发展和普及,网络社交媒体已经成为当代重要舆论场,其上每天都会产生巨量的个性化内容。分析社交媒体上的文本内容对某些特定目标的立场就显得尤为重要,它可以帮助舆情管理者快速掌握当前的舆论动向,进行相应的决策应对,并有针对性地开展舆论干预和引导。针对立场检测,目前的技术大致可分为单目标立场检测、多目标立场检测和跨目标立场检测。
2、单目标立场检测旨在识别文本作者对一个目标的态度(如“支持”、“反对”、“中立”等),其核心步骤通常包括文本表示学习、目标表示学习和立场分类,也有不少工作将目标语义融入文本表示学习过程,从而获得目标特定的文本表示。同一个文本中,作者可能对多个目标对象发表立场观点,多目标立场检测即判断文本作者对多个给定目标所持有的立场,现有方法可大致分为独立目标检测和联合目标检测,前者针对每个目标,单独训练一个模型来进行分类预测,即将多目标立场检测划分为多个单目标立场检测;后者则为所有目标训练同一个模型进行预测,因此训练成本更低,应用场景更广。跨目标立场检测旨在实现对训练时未出现的目标(称作“终目标”)的立场预测,因此需要建立源目标(即训练样本中的目标)与终目标之间的关联。基于迁移学习的跨目标立场检测,利用源目标和终目标所包含的共同主题,进行知识迁移,增强表示学习。
3、上述立场检测中的目标大多是具体的实体或事件,这些方法或任务都是针对通用领域中的特定对象,能够有效检测出网络文本对于特定实体或事件的立场态度,但是若将其应用到专用领域,表现可能并不理想。
技术实现思路
1、针对现有技术的应用场景限制和改进需求,本发明提供了一种面向社交媒体内容的多目标群体分类方法,其目的在于,实现一种独立于特定实体或事件的多目标群体分类方法,进而能够从更宏观的角度分析网络用户的倾向与立场。
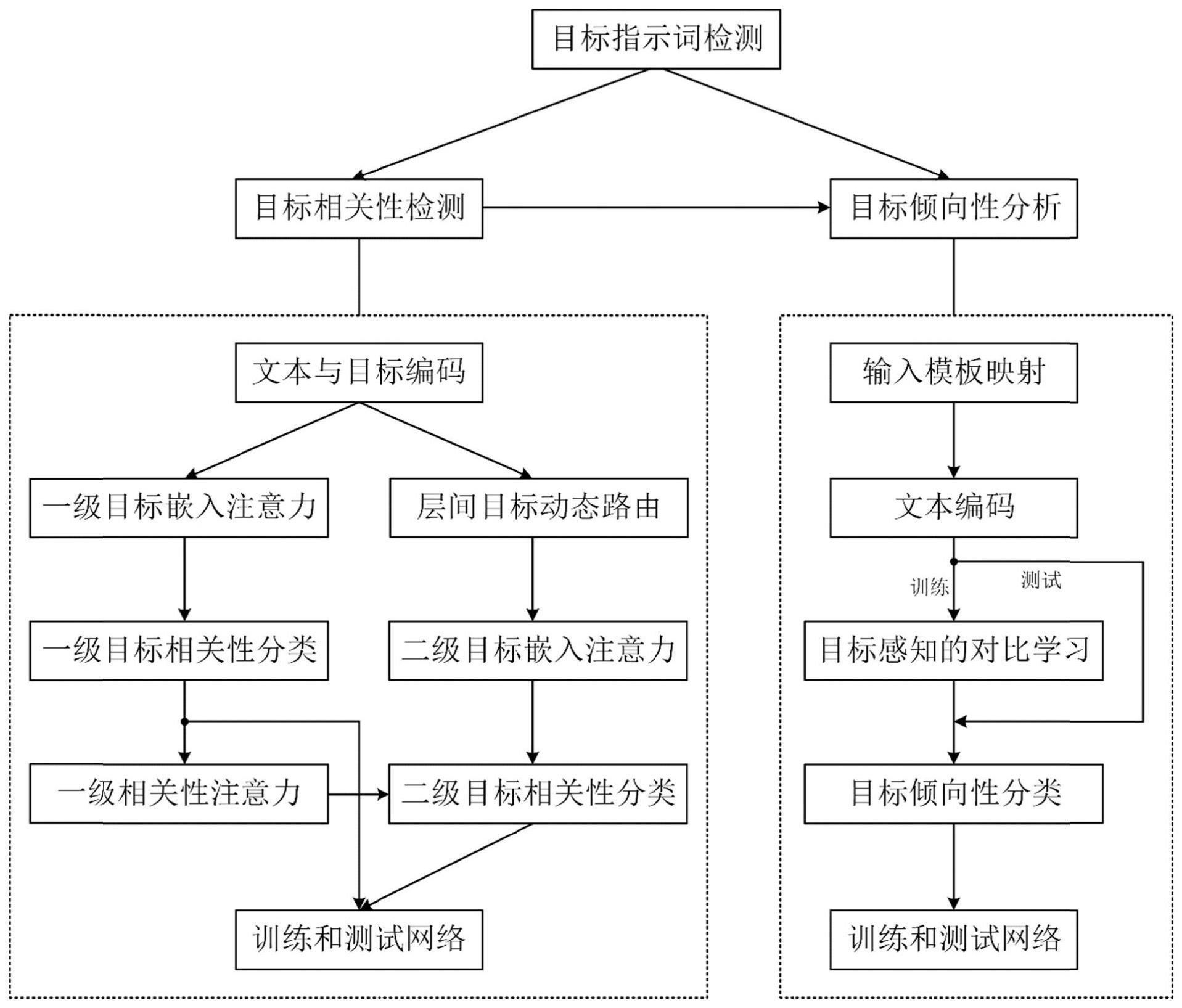
2、为实现上述目的,本发明提供了一种面向社交媒体内容的多目标群体分类方法,包括目标指示词检测步骤、目标相关性检测步骤和目标倾向性分析步骤,其中目标相关性检测步骤包括文本与目标编码、一级目标嵌入注意力、一级目标相关性分类、层间目标动态路由、二级目标嵌入注意力、一级相关性注意力、二级目标相关性分类、训练和测试网络;目标倾向性分析步骤包括输入模板映射、文本编码、目标感知的对比学习、目标倾向性分类、训练和测试网络;其中:
3、(1)目标指示词检测步骤:使用基于概率统计学的方法,从训练语料库中自动检测与各个目标最相关的一些词,从而将抽象的目标概念转换为具体的词汇描述;包括以下子步骤:
4、(1-1)对训练语料库中的所有文本进行分词;
5、(1-2)记两级目标的集合为t1,t2分别为一级、二级目标集合,n1,n2分别为一级、二级目标的个数。对l(l=1,2)级目标从训练语料库中选择与相关的文本组成语料库cr,其余与不相关的文本组成语料库cu;
6、(1-3)对cr和cu中的所有词进行排序,一个词在cr中的重要性越高、在cu中的重要性越低,则排序位置越靠前,取排名前k的词作为目标的指示词。
7、(2)目标相关性检测步骤:由于一条文本通常只会涉及t中的部分目标,因此该步骤检测文本与每个目标的相关性,得到文本在每一级的相关目标和不相关目标对于每条文本,目标相关性检测包括以下步骤:
8、(2-1)文本与目标编码:使用预训练语言模型对文本和目标进行编码,得到文本和目标的向量化表示,包括以下子步骤:
9、(2-1-1)将文本和目标转换为预训练语言模型的输入形式。对于文本,在文本的前后添加特殊词:
10、[cls]文本[sep]
11、对于目标,使用指示词的组合作为目标的文本描述,并在每个指示词之间添加特殊词:
12、[cls]指示词1[sep]指示词2[sep]…[sep]指示词k[sep]
13、(2-1-2)转换后的文本和目标分别输入两个预训练语言模型bertweet,捕获深度上下文语义特征;
14、(2-1-3)从预训练语言模型最后一层提取文本中每个词的表示(m为文本中词的个数,d为表示向量维度),取[cls]对应的向量作为目标表示此外,提取一级目标每个指示词的表示
15、(2-2)一级目标嵌入注意力:建立文本与一级目标的语义交互,得到一级目标感知的文本表示。对于每条文本,一级目标嵌入注意力包括以下子步骤:
16、(2-2-1)计算文本中词与一级目标的余弦相似度矩阵g中每个元素
17、
18、(2-2-2)在g上进行卷积,衡量长度为2r+1的文本窗口与目标的相关程度。对以位置l为中心,长为2r+1的文本窗口gl-r:l+r,计算
19、ul=relu(wfgl-r:l+r+bf)
20、其中,为神经网络可学习参数,提取ul中的最大值:
21、vl=maxpooling(ul)
22、以步长1移动文本窗口,得到
23、(2-2-3)对v进行归一化得到文本中每个词的注意力权重,根据权重对词的表示向量做加权求和,得到一级目标感知的文本表示:
24、α=softmax(v)
25、
26、(2-3)一级目标相关性分类:将一级目标感知的文本表示输入两层的前馈网络,并通过sigmoid函数得到文本与每个一级目标相关的概率:
27、
28、其中,均为可学习参数,f为激活函数,表示文本与第i个一级目标相关的概率,则
29、(2-4)层间目标动态路由:二级目标是所属一级目标的不同方面,一级目标的指示词也可看作是从不同角度描述对应的目标,因此一级目标的指示词与对应的二级目标之间存在关联,通过层间动态路由建立二者的信息传递,包括以下子步骤:
30、(2-4-1)初始化由动态路由得到的二级目标嵌入一级目标的第i个指示词与该一级目标下的第j个二级目标之间的耦合系数bij=0;
31、(2-4-2)用一级目标指示词嵌入pi与对应二级目标嵌入的向量点积更新bij:
32、
33、(2-4-3)使用softmax函数对bij进行归一化,
34、
35、(2-4-4)以βij为权重对一级目标指示词嵌入做加权和,得到二级目标嵌入的中间表示:
36、
37、(2-4-5)将ej经过非线性squashing函数得到二级目标嵌入:
38、
39、(2-4-6)重复步骤(2-4-2)~(2-4-5)z次,最终的即为由动态路由得到的二级目标嵌入。
40、(2-5)二级目标嵌入注意力:现在有两种二级目标嵌入,一种是步骤(2-1)中指示词经过编码得到的一种是步骤(2-4)中由层间目标动态路由得到的对这两种二级目标嵌入,分别执行与步骤(2-2)类似的操作,建立文本与二级目标之间的语义交互,得到两种二级目标感知的文本表示和
41、(2-6)一级相关性注意力:由于一级目标数量较少,相关性预测更容易,准确率较高,因此可以将一级相关性预测结果引入二级相关性预测的过程,帮助提升二级相关性预测的准确率。使用一级相关性注意力实现上述动机,包括以下子步骤:
42、(2-6-1)以步骤(2-3)得到的一级目标相关概率为权重,对一级目标嵌入做加权和:
43、
44、(2-6-2)计算d与文本中每个词嵌入的余弦相似度,并使用softmax函数做归一化,得到每个词的注意力权重αi:
45、
46、(2-6-3)根据每个词的注意力权重对文本词嵌入做加权求和操作,得到一级相关性预测结果感知的文本表示:
47、
48、(2-7)二级目标相关性分类:融合两种二级目标感知的文本表示以及一级相关性预测结果感知的文本表示使用前馈神经网络,预测二级目标相关性,包括以下子步骤:
49、(2-7-1)使用门控机制计算三种文本表示对最终预测的贡献程度:
50、
51、
52、
53、其中,为可学习参数;
54、(2-7-2)基于三种文本表示的门控系数计算最终的文本表示:
55、
56、其中,⊙表示向量元素对位相乘;
57、(2-7-3)以文本表示为输入,使用前馈神经网络预测文本与每个二级目标相关的概率:
58、
59、其中,均为可学习参数,σ为激活函数,表示文本与第i个二级目标相关的概率,则
60、(2-8)训练和测试网络:基于预测的目标相关概率和真实的目标相关概率y1,y2构建损失函数,然后使用bp算法训练网络以最小化损失函数。训练完成后,输入测试集中的文本从而得到各个测试样本的相关目标。
61、(3)目标倾向性分析步骤:使用基于提示(prompt)模板的文本编码方式,预测文本对中每个二级相关目标的倾向性。对于每条文本,目标倾向性分析包括以下子步骤:
62、(3-1)输入模板映射:给定一个模板和一个相关目标,将输入文本xinp和相关目标指示词xind映射为提示文本xprompt:
63、
64、(3-2)文本编码:将提示文本xprompt输入预训练语言模型roberta,捕获深度上下文语义特征,从预训练语言模型最后一层提取[mask]对应的隐藏向量作为文本表示:
65、s=h[mask]
66、(3-3)目标感知的对比学习:为了使相同倾向性类别文本的向量表示尽量接近,不同倾向性类别文本的向量表示尽量远离,同时促使模型更加关注目标信息,进行目标感知的对比学习。对于一个训练batch内的每一条文本xi,目标感知的对比学习包括以下子步骤:
67、(3-3-1)给定训练batch内,与xi的倾向性类别相同且目标相同的文本作为xi的正例,与xi的倾向性类别不同或目标不同的文本作为xi的负例;
68、(3-3-2)记xi的目标为ti,向量表示为si,计算目标感知的对比学习损失:
69、
70、
71、其中,b为训练batch大小,p(i)={j|i≠j,ti=tj,yi=yj},b(i)={1,2,...,b}\{i},τ为温度系数;
72、(3-4)目标倾向性分类:基于步骤(3-2)得到的文本表示,使用前馈网络预测文本对给定目标的倾向性类别。为了利用倾向性类别的顺序性,在预测过程中使用了steak-breaking方法。对于每一条文本,目标倾向性分类包括以下子步骤:
73、(3-4-1)将文本表示输入前馈网络,并经过sigmoid函数:
74、a=σ(w2f(w1s+b1)+b2)
75、其中,w1,w2,b1,b2为可学习参数,f为激活函数,a的每一维ai是一个决策边界,表示第i类的概率在后续所有类别({j|j≥i})的概率中所占的比例;
76、(3-4-2)使用steak-breaking方法将前馈网络的输出转换为概率分布
77、
78、
79、
80、表示文本对给定目标的倾向性属于第i类的概率;
81、(3-5)训练和测试网络:基于预测的倾向性类别概率分布和真实倾向性标签构建损失函数,并联合目标感知的对比学习损失使用bp算法训练网络以最小化损失函数。训练完成后,输入测试集中的文本从而得到各个测试样本对各个相关目标的倾向性类别。
82、优选地,步骤(1-3)中,使用带有dirichlet先验的加权对数比(weighted log-odds-ratio)方法对语料库cr和cu中的词进行排序,具体步骤如下:
83、使用带有dirichlet先验的加权对数比计算词w在两个语料库中的使用频率差异:
84、
85、
86、其中,nr为语料库cr中词的数量,nu语料库cu中词的数量,分别为词w在语料库cr,cu中出现的次数;n0为背景语料库中词的数量,为词w在背景语料库中出现的次数。
87、计算对数比的方差,最后计算词w的z分数:
88、
89、
90、zw越高说明词w在语料库cr中越重要,而在语料库cu中越不重要。根据zw对语料库cr,cu中的所有词进行排序,取排名前k的词作为指示词。
91、优选地,步骤(2-1)中,预训练语言模型使用bertweet;所述步骤(3-2)中,预训练模型使用roberta。bertweet和roberta在预训练时使用的语料库不同,但使用相同的训练流程,且模型结构相同,都是基于transformer编码器的多层堆叠,每个编码层包含两个子层:多头自注意力、前馈网络,每个子层都带有残差连接和层标准化。其中,多头自注意力的公式表示如下:
92、o=[head1,...,headh]wo
93、
94、qi=xwi,q,ki=xwi,k,vi=xwi,v
95、其中,h为注意力头数,分别为输入输出,为可训练参数。
96、优选地,步骤(2-4)使用了层间目标动态路由,建立了一级目标指示词与二级目标之间的交互,从不同角度归纳一级目标指示词的语义,实现了目标语义信息从一级向二级的传递。
97、优选地,步骤(2-8)中,为应对相关性类别不平衡的问题,即各个目标下的不相关文本远多于相关文本,在训练过程中,对训练集中的与所有目标都不相关的文本进行降采样,降采样率为r。预测损失函数采用带权重的二元交叉熵损失函数。为了使二级目标表示更能代表目标语义信息,对其进行正则化。将输入分类器,期望分类器能够区分出不同的目标表示,分类器预测的交叉熵损失作为目标正则化损失。因此,目标相关性检测网络的损失可表示如下:
98、
99、
100、
101、其中,λ1,λ2为三种损失之间的平衡参数,为第i级目标相关性分类损失,为目标正则化损失,n为训练样本个数,为第i级第k个目标的正例损失权重,计算方式为:
102、
103、其中,分别为第i级第k个目标的相关文本数和不相关文本数。
104、可选地,步骤(2)能同时预测文本对两级目标的相关性,若只存在一级目标,则可不采用步骤(2-4)~(2-7),即只检测文本对各个一级目标的相关性。
105、优选地,步骤(3-1)使用模板将输入映射为含有特殊词[mask]的自然语言提示,缩小了微调与预训练阶段的差异,有利于激发预训练语言模型中的语言学知识。
106、优选地,步骤(3-3)中,在对比学习中引入了目标信息,只有倾向性类别相同且目标相同的文本才能作为正例,引导模型更加关注目标信息,从而更好地捕获针对不同目标的倾向性特征。
107、优选地,步骤(3-4)中,为了利用倾向性类别的顺序性,使用了steak-breaking方法。网络的输出向量不是直接的概率分布,其每一维是一个决策边界,表示该类别的概率在后续所有类别中所占的比重,基于此,将网络输出转换为概率分布。
108、优选地,步骤(3-5)中,损失函数采用交叉熵损失函数。目标倾向性分析网络的损失可表示如下:
109、
110、
111、其中,γ为两种损失之间的平衡参数,n为训练样本个数,yj,k,分别为第j条文本属于第k个倾向性类别的真实概率和预测概率。
112、总而言之,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
113、(1)群体分类准确率高:模型中首先通过目标相关性检测,排除文本中未涉及的目标,避免了对无关目标的倾向性检测,可以提高检测效率和准确率;目标相关性检测中的层间动态路由以及一级相关性注意力实现了目标语义和相关性预测结果从一级向二级的传递,帮助提升二级相关性检测的准确率;目标倾向性分析中,提示模板和目标感知对比学习的使用,有利于挖掘预训练语言模型中的语言学知识,促使模型关注目标信息,从而提升目标倾向性分析的性能;
114、(2)能够对抽象的目标概念进行倾向检测:本发明中提出了目标指示词检测方法,基于词频对比从训练语料库中自动提取与目标最为相关的一些词作为指示词,这对于抽象目标场景尤为有效,可以将抽象的目标概念转换为具体的文本描述。同时,与人工定义的目标解释相比,该方法检测出的指示词更符合社交媒体内容对目标概念的描述方式,更有利于模型进行语义匹配和语义理解。
- 还没有人留言评论。精彩留言会获得点赞!