一种3D目标检测方法、装置和电子设备
本发明涉及自动驾驶方法,具体涉及一种3d目标检测方法、装置和电子设备。
背景技术:
1、目前基于二维图像的目标检测技术已经非常成熟,已经在现实生活中拥有了广泛的应用,例如人脸识别、工业产品缺陷检测、安全监控等领域。但是二维的图像并不能检测出物体的深度信息,因此二维的目标检测并不能适应一些三维场景,尤其是在自动驾驶领域,目标的三维信息十分的重要。
2、近年来,随着硬件和深度学习的发展,基于深度学习的3d目标检测已经拥有高准确率和检测速度快的优点,已经在各个领域起到了作用,尤其是在自动驾驶领域。目前的汽车已经搭载了高精度激光雷达等传感器,即使是面对恶劣天气,激光雷达仍然能够采集到具有丰富空间信息的点云,因此利用激光雷达点云来进行3d目标检测成为了近年来研究队的热点。对于激光雷达传感器采集到的点云数据,为了能够用于深度学习模型,主要有基于原始点云的方法,基于体素的方法、基于视图的方法以及基于特征融合的方法。
3、其中《bevformer:learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers》是eccv 2022的一篇论文。该篇论文提出了一个采用纯视觉(camera)做感知任务的算法模型bevformer。bevformer通过提取环视相机采集到的图像特征,融合了时间与空间信息特征,从而实现3d目标检测任务,并取得了sota的效果。
4、但是本发明认为,作为自动驾驶车辆传感器依靠雷达获得的信息应该比图像更加准确,如果对点云体素化后进行时间与空间信息的特征融合可以取得比bevformer依靠纯视觉方案更加精准的检测结果。但是目前受限点云的稀疏性和算力的瓶颈,无法直接对点云特征快速的时空特征融合。
技术实现思路
1、因此本发明提出了一种方法,能在有限的算力的情况下实现对体素化后点云的特征时空融合方法。
2、本发明提出一种基于点云体素化的时空融合特征提取方法和流程,来实现对自动驾驶场景下3d目标检测的方法。
3、本发明认为,在面对被遮挡的物体时,如果能够获取该时刻之前的特征,以及该时刻上下文空间信息,那么模型可以很好的判断出遮挡的物体。利用时序信息和空间信息能够实现更可靠的检测性能,尤其是对移动的小目标或是远处的物体,这能够为安全的自动驾驶提供更可靠的保证。
4、同时因为算力限制,本发明提出了一种基于hash函数快速体素查询方案,实现如何快速的从非空体素列表中找到上面筛选出来的非空体素,以实现基于体素的时空特征快速融合。
5、针对上诉问题和目的,本发明提供了一种3d目标检测方法、装置和电子设备,用于构建3d目标检测模型,以实现对自动驾驶场景下目标更准确且鲁棒的定位和识别。
6、为了实现上述目的,现提出的方案如下:
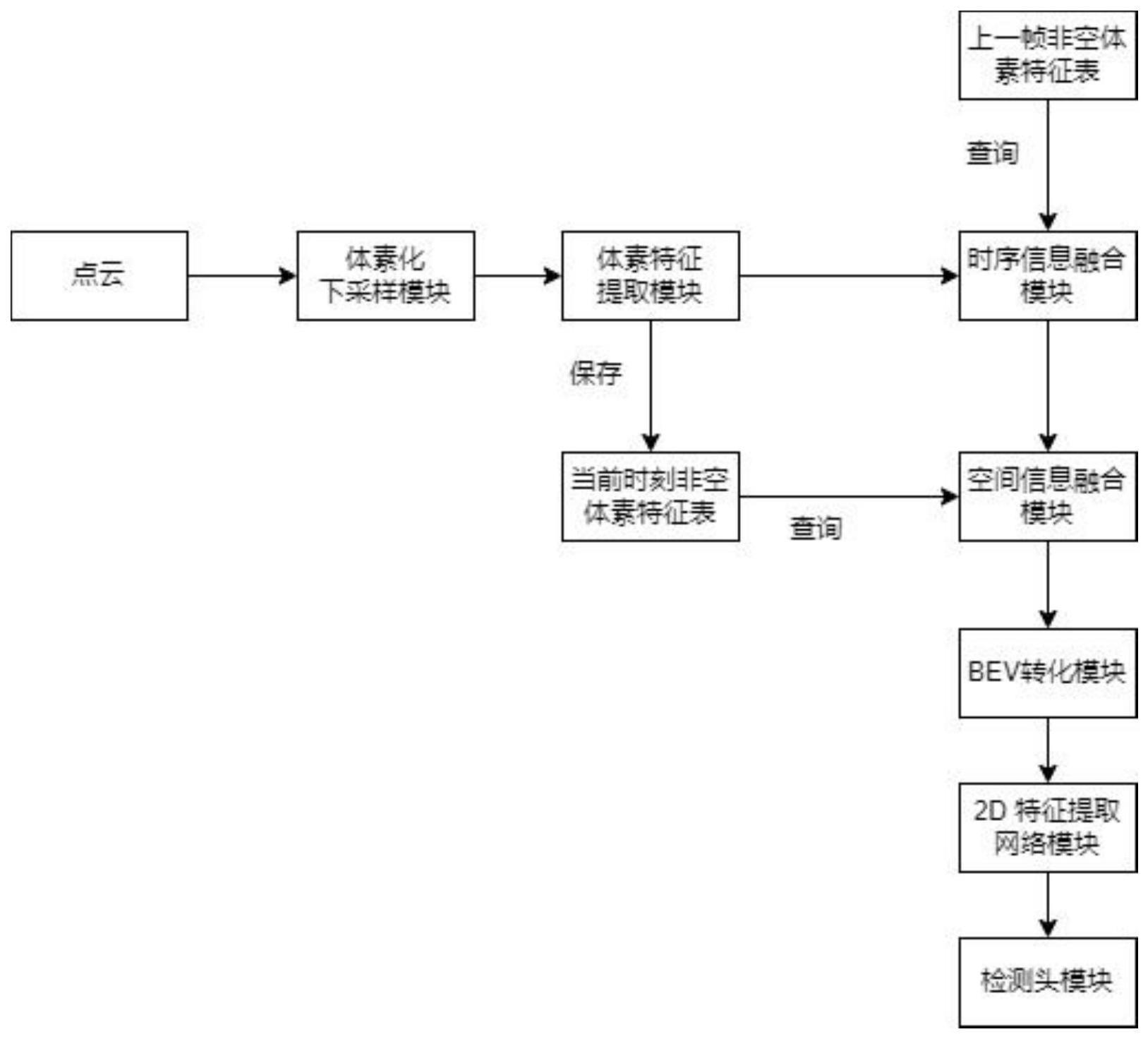
7、一种3d目标检测方法,所述方法包括步骤:
8、(1)加载点云数据,对加载的点云数据预处理,使用向量表示每一个点云,划分场景为多个体素,同时对每一个体素编号,对每一个体素内进行随机点云下采样;
9、(2)对每个体素进行特征提取,获取每一个体素的特征,对于每一个非空体素,将提取后的体素特征保存在当前时刻的非空体素表中,以便后续查找;
10、(3)将当前时刻每一位置的非空体素特征送入时序信息融合模块,通过timehash函数找到上一时刻相对应位置的体素特征进行特征融合,此时当前时刻每一个体素特征便融合了时序信息;
11、(4)将融合时序信息后的体素特征送入空间信息融合模块,每一个体素分别与其周边局部非空体素特征融合,得到总的融合了时空信息的4维特征图;
12、(5)将融合了时空信息的4维特征图送入bev转化模块,转化为bev特征图,便于加速后续检测推理;
13、(6)将上一步bev特征图接入2d特征提取网络和检测头网络进行目标检测,获得最终的预测结果。
14、进一步的步骤(1)中,读取原始雷达点云数据,在场景中按照点云数据所在的x,y轴和z轴方向,将点云数据划分为一个个的方体网格,凡是落入到一个网格的点云数据被视为其处在一个体素里,或者理解为它们构成了一个体素,同时对每一个体素根据坐标位置进行编号设为(xv,yv,zv);
15、读取体素中每一个点云的数据信息,其中包括点云坐标(x,y,z)和点云的反射强度r,假设每一个体素中点云的数量为nsum,那么每个点云的信息可以用维度d=8的向量来表示,分别为d=(x,y,z,r,l,xv,yv,zv),其中x,y,z,r为送入的点云数据信息,l为点云与体素几何中心的相对位置;
16、
17、其中,xv,yv,zv分别表示体素的中心点的坐标位置。
18、那么,单个体素可以用(n,d)的张量来表示,整个场景可以用一个(n,d,l,h,w)的张量表示,其中d为点云的维度,l*h*w为体素的数量,n为每个体素内保存点云的数量。
19、进一步的步骤(2)中,体素特征提取,采用简化后的pointnet网络对点云进行数据处理和特征提取,将体素内每一个点云的信息,经过全连接网络层,将原张量中的d维度生成c维度,n个点一共获得的特征为(n,c),随后进行最大值池化操作,获得该体素的池化特征(1,c),最后将池化特征复制n份,拼接到特征(n,c)中,获得特征每个点的特征与池化特征的拼接(n,2c),最后再进行一次最大值池化操作,获得该体素特征为表示(1,2c);
20、最后判断该体素是否为空体素,即特征全为0的补零体素,如果不是空体素,则将该体素特征保存在该体素位置所对应的当前帧的非空体素特征表中,反之不做任何处理;
21、进一步的对于步骤(3),遍历当前时刻场景中每一个体素,首先判断当前体素是否是空体素,如果是空体素则直接不做任何处理,如果不为空体素,则将该体素的坐标位置传入timehash函数,获得对应的上一帧相同位置非空体素特征表所在的索引,然后获取上一帧的特征。
22、假设当前时刻t中的非空体素特征为ft=(1,2c),上一时刻t-1中位置i的体素特征为ft-1=(1,2c),将两个体素特征平均分为四份,每一份的大小为(1,c/2),每份的向量再加上位置编码得到最后要传入注意力编码器的特征向量,获取最终要传入注意力编码器的特征向量8*(1,c/2)。
23、在注意力编码器中,首先对传入的每一份向量进行计算,将每一个向量的组成一个矩阵用x表示,即x=(8,c/2),获取q,k,v,其中:
24、q=x*wq,
25、k=x*wk,
26、v=x*wv。
27、wq,wk和wv是可学习到的线性变换矩阵;
28、将q,k,v通过自注意力公式计算后,便可以获得融合了上下特征的特征向量。总的自注意力的计算公式为:
29、
30、其中,dk是q,k矩阵的列数,即向量维度;
31、通过上一步注意力编码器后可以得到与输入维度相同的向量,即8个(c/2)向量,通过将前四个向量按顺序拼接,可以获得最终的当前体素融合了时序信息的特征向量ftime=(1,2c),随后对每个体素进行相同操作,一共需要操作l*h*w次。
32、进一步的对于步骤(4),遍历每一个体素,首先判断当前体素是否是空体素,如果是空体素则直接不做任何处理,如果不为空体素,则计算得出该体素的周边体素坐标,分别将周边体素坐标传入zonehash函数计算出对应的非空体素特征,获取当前位置非空体素的特征和查询到的周边非空体素特征,送入注意力编码器进行注意力特征提取,具体操作与上一步类似,保留输出向量的第一个作为最终该位置体素的特征向量,随后对每个体素进行相同的操作,一共需要操作l*h*w次。
33、进一步的对于步骤(5),将最终融合了时空信息的特征图f4d=(2c,l,h,w)送入检查网络完成预测,根据l*h*w的值,对f4d进行分解重塑,降为3dbev特征图fbev=(2c,m,m),其中m=(l*h*w)/2。
34、进一步的对于步骤(6),当fbev通过2d特征提取网络模块和检测头模块后,输出检测结果为检测目标检测框的类别信息,即x,y,z,w,h,l,θ,通过损失函数来训练网络,使网络收敛,网络的总的损失函数定义为:
35、
36、
37、
38、lcls=-αa(1-pα)γlogpα
39、其中,l为总的损失函数,lcls为分类的损失函数,lioc为位置的损失函数,ldir为方向分类损失函数;βioc,βcls,βdir分别为位置损失函数的系数,分类损失函数的系数以及方向分类损失函数的系数;p为预测框,g为真实框,iou表示预测框与真实框重叠的比例。ρ2(p,g)表示预测框与真实框中心点距离的平方,c2指的是两个矩形框的闭包区域的对角线的距离的平方。参数p为样本为正值的概率;aa为权重系数,α,γ为系统的超参数,npos为有效预测框数量。
40、本发明提供一种3d目标检测装置,所述检测装置功能模块包括:体素下采样模块、体素特征提取模块、时序信息融合模块、空间信息融合模块、2d特征提取网络模块、检测头模块。
41、本发明还提供一种电子设备,其特征在于,设置有如上所述的3d目标检测装置。该设备至少一个处理器和与所述处理器连接的存储器,其中:所述存储器用于存储计算机程序或指令;所述处理器用于执行所述计算机程序或指令,以使所述电子设备实现如上所述的3d目标检测方法。
42、本发明的有益效果在于,与现有技术相比,本发明基于深度学习的3d目标检测办法优点如下:
43、(1)在算力限制的情况下,提出了一种基于hash函数快速查找非空体素特征的方法。
44、(2)对基于体素提取到的点云进一步融合了时序特征,模型可以充分理解当前时刻与之前时刻的场景关系,这样可以更好的应对物体遮挡的情况。
45、(3)因为融入了空间特征,这样针对小物体的特征信息会被加强,小物体会被更容易检测到。
46、(4)对提取到的四维体素特征图进行转化,在不造成特征损失的情况下转化为三维特征图,后续将三维特征图传入检测网络,可以提高检测速度。
- 还没有人留言评论。精彩留言会获得点赞!