一种基于路径推理的开放视觉问答的系统
本发明涉及神经网络,具体来说涉及视觉问答,更具体地说,涉及一种基于路径推理的开放视觉问答的系统。
背景技术:
1、随着计算机视觉和自然语言处理技术的发展,基于外部知识的视觉问答(knowledge-based visual question answering,简称kb-vqa)任务成为一个研究热点。kb-vqa任务需要对给定的问题和图像进行推理,并从知识库中获取相关信息来得到答案。
2、解决该问题的模型通常是基于知识检索器-回答器框架进行的两阶段操作,即,先通过知识检索器从知识库中获取相关信息,然后将获取的相关信息与问题和图像一起输入回答器以预测答案。
3、知识检索阶段通常使用手工规则进行操作,并且不会与回答器进行端到端的训练。对于文本形式的知识,密集段落检索模型(dpr)已经证明可以有效地检索相关知识片段。而视觉知识则可以通过在输入图像上应用视觉模型(如目标分割模型、图像描述模型等)获取。
4、回答器的框架可以分为两类:答案生成器和答案分类器。预训练的答案生成器主要基于给定的图像、问题和知识生成答案。然而,它们通常依赖大规模预训练语料库,因此计算成本较高。因此,目前多数kb-vqa方法采用答案分类器。答案分类器通过在预定义的答案空间(相当于有预定义答案候选集)中进行分类来预测最终答案。大多数研究采用预训练的视觉-语言模型来整合输入的问题与检索到的知识中的视觉和语言信息。为了提高视觉问答(vqa)模型的可解释性,研究人员提出了不同的解决方案。如基于图神经网络(gnn)的模型通过在问题-图像相关图上进行传播和聚合来推理答案。这些模型的推理过程可以通过解码图神经网络的注意力权重来进行解释。然而,所有这些模型都受到预设答案候选集的限制,不能充分挖掘整个知识库蕴含的知识。另外,直接根据输入的问题和图像进行推理时是通过隐藏的无法直观理解的参数完成,属于黑箱操作,推理过程无法解释。
5、开放的kb-vqa任务则旨在脱离出预定义答案候选集的限制。为了解决开放kb-vqa问题,可以利用抽取式阅读器与答案生成器。其中,抽取式阅读器是采用先根据问题从现有语料库中的文本检索相关知识片段,然后在检索到的知识片段中通过预测答案在检索到的知识段落中的开始和结束位置,以提取答案。然而,因为缺乏答案位置标注,而在大量文本中标注答案的开始和结束位置的标注成本非常高,导致这种方法不适合直接应用于vqa任务。另一种实现开放式vqa的方法是从头生成答案。一些大规模的预训练模型(如gpt-3)已经可以生成合理的答案。这些模型的成功很大程度上依赖于模型训练过程中存储的隐式知识,例如大规模语言模型中的知识,以及为每个问题检索的显式知识和联合推理网络。这两种方法都面临一个共同的问题:过于依赖获取到包含真实答案的知识片段的召回率。模型性能对检索到的知识的质量和数量非常敏感,例如,为了获得足够的知识命中率,提取式阅读器需要大量的知识段落,其同时也会引入大量的干扰,这可能会降低阅读器的准确性。
6、因此,现有技术存在以下待解决问题:
7、1、答案分类器通过在预定义的答案空间(相当于有预定义答案候选集,其蕴含的知识远远小于知识库的知识)中进行分类来预测最终答案,不能充分挖掘整个知识库蕴含的知识;
8、2、推理过程属于黑箱操作,推理过程无法解释。
技术实现思路
1、因此,本发明的目的在于克服上述现有技术的缺陷,提供一种基于路径推理的开放视觉问答的系统。
2、本发明的目的是通过以下技术方案实现的:
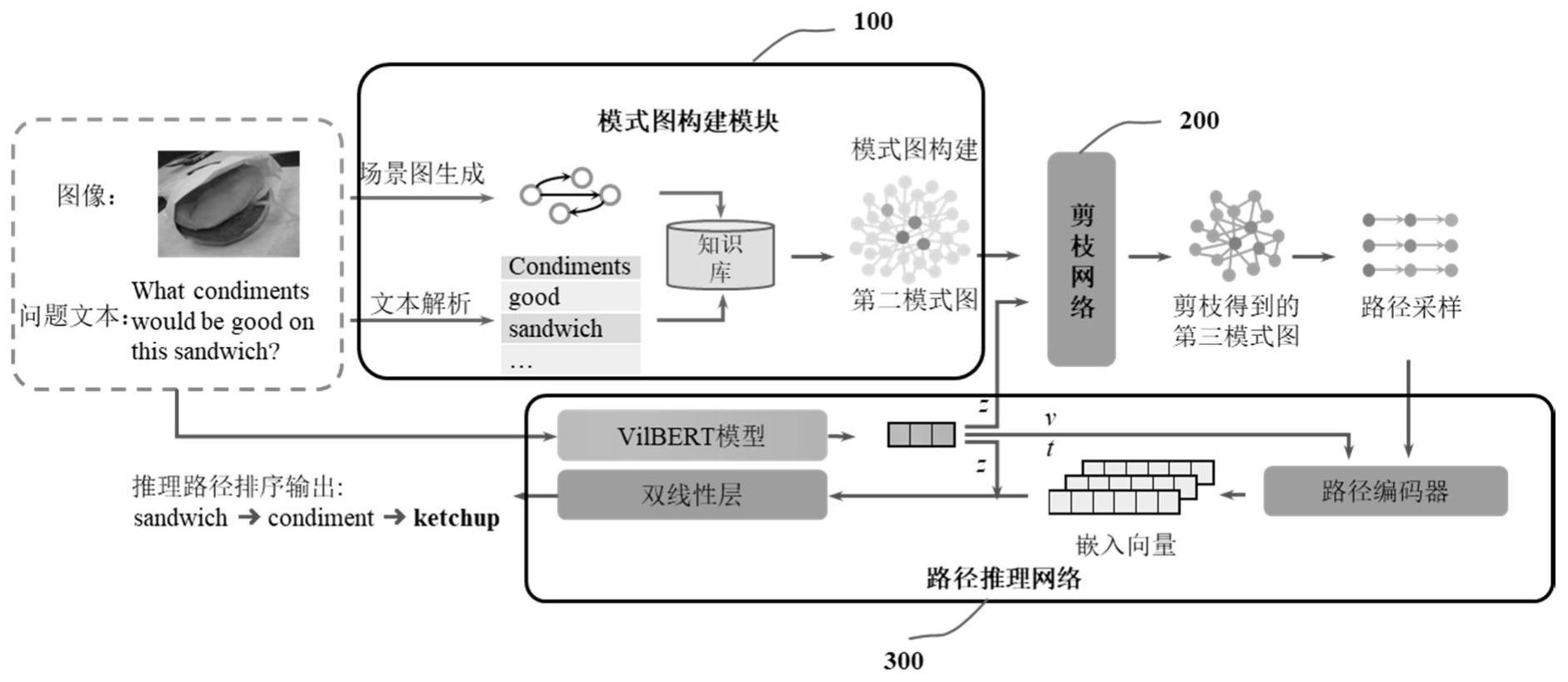
3、根据本发明的第一方面,提供一种基于路径推理的开放视觉问答的系统,所述系统包括:模式图构建模块,用于获取输入的图像和针对该图像提出的问题文本,从所述图像和问题文本中提取节点和关系来构建第一模式图,从预设的知识库检索第一模式图中节点的预设跳数内的邻居节点以对所述第一模式图进行扩展,得到融合外部知识信息的第二模式图;剪枝网络,包括节点编码器和剪枝层,其中,所述节点编码器,用于根据所述图像、所述问题文本以及各个节点的类型提取节点的嵌入向量;所述剪枝层,用于根据每个节点的嵌入向量与多模态上下文特征的相似性和每个节点与关键节点的距离的加权和对第二模式图进行剪枝,得到第三模式图,其中,所述多模态上下文特征是交叉对图像和文本提取特征所得到的融合特征,所述关键节点为从所述图像和问题文本中提取的节点;路径推理网络,包括路径编码器、双线性层和输出层,其中,路径编码器,用于基于从第三模式图提取的多条候选推理路径,根据问题文本的文本特征、图像的图像特征和每条候选推理路径上各节点的嵌入向量的拼接向量确定该条候选推理路径的嵌入向量,双线性层,用于确定各候选推理路径的嵌入向量与多模态上下文特征的匹配概率,输出层,用于根据各候选推理路径对应的匹配概率确定推理结果。
4、可选的,模式图构建模块被配置为:从所述问题文本中提取多个关键词及其关系,所述关键词为名词、动词、形容词、副词和短语中的任意一种;将多个关键词及其关系与所述知识库中的实体和关系进行第一次匹配,根据第一次匹配到的实体和关系创建含有文本节点及其关系的初始的模式图;对所述图像中的对象和关系进行识别,将识别到的对象和关系与所述知识库中的实体和关系进行第二次匹配,将第二次匹配到的实体和关系添加到初始的模式图中,得到所述第一模式图,所述第一模式图含有文本节点、图像节点及其关系;从所述知识库中,检索第一模式图中节点的两跳内的邻居节点;将检索到的邻居节点及其关系添加到所述第一模式图上,得到所述第二模式图。
5、可选的,知识库是conceptnet知识图谱或者freebase知识图谱。
6、可选的,所述节点编码器被配置为:获取第一嵌入模型从问题文本提取文本特征、从图像提取图像特征以及从文本和图像提取多模态上下文特征;获取第二嵌入模型对融合文本提取的融合文本特征,所述融合文本是对所述问题文本和从节点扩展的邻居节点对应的文本拼接得到的;针对每个节点,利用至少一层感知机根据所述多模态上下文特征、该节点对应的实体特征、该节点的类型和第二嵌入模型对融合文本提取的融合文本特征,确定节点的嵌入向量。
7、可选的,所述第一嵌入模型为vilbert模型、vlbert模型、uniter模型或者vilt模型。
8、可选的,所述第二嵌入模型为bert模型、tinybert模型、gpt2模型或者gpt3模型。
9、可选的,所述剪枝层被配置为按照以下方式确定加权和:
10、sprune=(1-θp)scos+θpsbfs
11、其中,scos表示一个节点的嵌入向量与所述图像和问题文本对应的多模态上下文特征的相似性,sbfs表示该节点与关键节点的距离分数,θp表示sbfs对应的权重。
12、可选的,所述多条候选推理路径中的每条候选推理路径按照以下方式得到:从第三模式图中的起始节点开始,基于关系构建的路径随机游走k步,当游走到结束节点时得到一条候选推理路径,其中,每次的起始节点为从所有关键节点中随机选择的节点;每次的结束节点为答案节点。
13、可选的,所述k大于等于3。
14、可选的,所述系统按照以下方式训练得到:获取训练数据,其包括多个样本和标签,其中,每个样本包括样本图像和样本问题文本,标签指示样本对应答案真值;将训练数据中的样本输入系统,得到样本对应第二模式图及其每个节点的嵌入向量,以及每个样本对应的多个候选推理路径的匹配概率;根据训练数据中样本的三元组损失和二分类交叉熵损失确定总损失,根据所述总损失更新节点编码器、路径编码器和双线性层的可训练参数,其中,每个样本的三元组损失为根据该样本的第二模式图所能构建的所有三元组的子损失的均值,每个三元组中,锚样本为该样本的多模态上下文特征,正样本为一个答案真值对应的节点的嵌入向量,负样本为非答案真值对应的节点的嵌入向量;每个样本的二元交叉熵损失为该样本对应的所有候选推理路径的匹配概率与标签计算的二元交叉熵子损失的均值。
- 还没有人留言评论。精彩留言会获得点赞!