一种基于图神经网络和可解释模型的源代码漏洞检测方法及装置
本发明涉及一种基于图神经网络和可解释模型的源代码漏洞检测方法及装置,属于网络安全。
背景技术:
1、在现代社会中,软件技术已经在各个领域广泛应用,涵盖金融、医疗、交通、通信等多个领域。这些软件系统通常承载着大量敏感数据和关键业务,因此软件的安全性变得尤为重要。然而,随着互联网的飞速发展,网络攻击的威胁也日益增加。黑客和恶意用户不断寻找并利用软件中的漏洞和弱点,以获取非法利益、破坏系统或窃取敏感信息。软件漏洞形态呈现出的复杂性和多样性给软件的开发和维护带来了极大的挑战。自2017年以来,软件漏洞的数量急剧上升。根据veracode于2020年10月发布的第11卷软件安全状况报告,超过四分之三(75.2%)的应用程序存在安全漏洞。这种情况给开发人员和用户带来了严重的安全风险,并导致了经济和社会方面的巨大损失。因此,如何降低软件源代码漏洞并提高软件的安全性,已成为当前亟待解决的问题。
2、在网络安全的定义中,漏洞主要是指在硬件、软件和协议等的具体实现或系统安全策略上存在的缺陷,从而使攻击者能够在未授权的情况下访问或破坏系统,造成系统瘫痪,对信息安全构成严重威胁。为了有效地应对这些潜在的攻击威胁,软件开发者和研究人员需要尽早发现并修复潜在的漏洞。漏洞检测是一项试图通过审计软件代码或分析软件的执行过程来发现软件漏洞的任务,分为静态分析和动态分析两大类。静态分析是在软件执行前对其源代码或二进制代码进行分析,通过对代码的深度审查,尝试发现潜在的漏洞。动态分析则是在软件运行时对其行为进行监控和分析,以便捕捉可能在运行过程中出现的漏洞。
3、早期的软件漏洞挖掘技术不仅效率低下而且存在高误报和高漏报等问题,无法满足日益增长的软件安全性需求。为克服上述缺点,机器学习(ml)方法被应用到漏洞检测中,ml将代码漏洞检测看作是二进制分类任务来预测代码样本是否易受攻击。然而传统的研究方法主要依赖于人类专家手工制作的特征来检测漏洞,通常很耗时,且无法直接适应随着实践的推移不断发展的众多库中的所有漏洞。深度学习(dl)由于其具有处理大量软件代码和漏洞数据的强大能力而在漏洞检测中得到引入,它能够从先前的漏洞代码中隐含地学习漏洞的模式,从而检测新的代码片段中是否存在漏洞,并已获得了初步成功。
4、基于图的dl方法将源代码转换为特定的图结构,以从图表征中捕获软件漏洞的基本代码结构,然后通过训练图神经网络(gnn)模型提取图结构信息,实现源代码的漏洞检测。尽管基于gnn的漏洞检测技术已经取得了很大进步,但仍存在一些局限性:(1)现有工作大多使用复杂的预处理为每个给定的源代码构建一个多边图,再将多边图输入dl模型对给定的代码片段进行漏洞检测,而这种复杂的预处理方式很难在许多编程语言和许多开放源代码和库中实现;(2)目前许多基于ml/dl的漏洞检测方法仅限于提供粗略的检测结果,即给定的函数或方法是否有漏洞,它们在阐明可能涉及被检测到的漏洞的具体语句的代码行的细粒度细节方面还有所欠缺。
技术实现思路
1、本发明的目的在于提供一种基于图神经网络和可解释模型的源代码漏洞检测方法及装置,基于pl预训练模型、图神经网络、残差连接算法和机器学习可解释技术的混合模型,检测源代码中的漏洞。该方法可以提升代码的质量和可信度,降低维护和修复的成本和风险。
2、为达到上述目的,本发明采用的技术方案如下:
3、本发明提供一种基于图神经网络和可解释模型的源代码漏洞检测方法,包括:
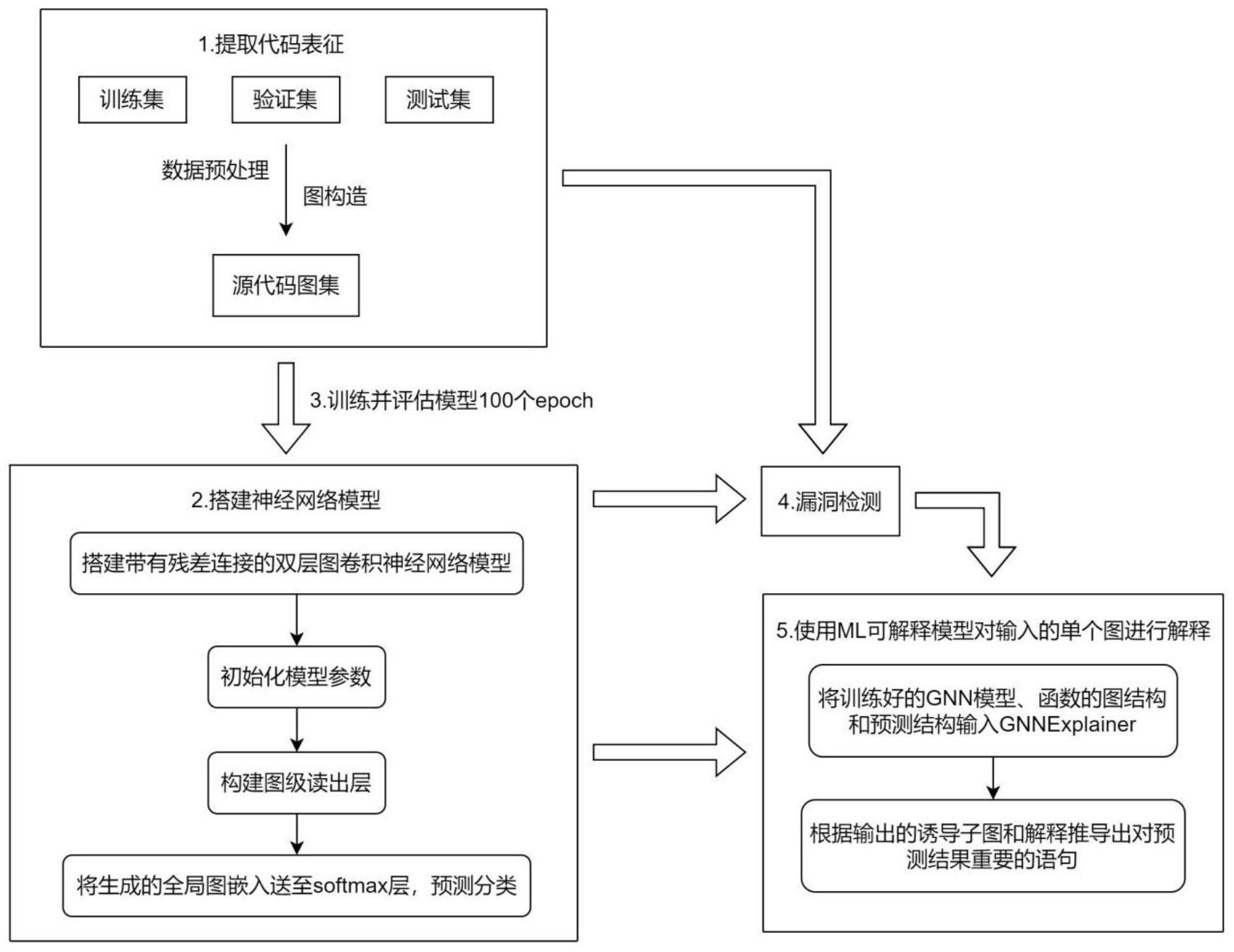
4、提取函数源代码的代码表征,并将所述代码表征转换为图结构,形成源代码图集;
5、搭建图神经网络模型,以所述源代码图集为输入,以函数源代码的漏洞分类结果为输出,训练所述图神经网络模型,得到最佳模型参数下的图神经网络模型作为漏洞检测模型;
6、基于所述漏洞检测模型对待检测的函数源代码进行检测,得到漏洞检测结果;
7、基于可解释模型对所述漏洞检测结果进行解释,得到函数源代码中导致漏洞的关键语句。
8、进一步的,所述提取源代码的代码表征,包括:
9、采用编程语言预训练模型graphcodebert提取函数源代码的代码表征。
10、进一步的,将所述代码表征转换为图结构,包括:
11、将函数体中唯一token表示为节点,并将token之间在固定大小的滑动窗口内的共现表示为边,得到图结构,所述图结构采用邻接矩阵a来表示,
12、对于邻接矩阵a中的元素,如果节点v和节点u在滑动窗口内共现且v≠u,则av,u=1,否则av,u=0。
13、进一步的,所述搭建图神经网络模型,包括:
14、构建双层图卷积神经网络提取输入图数据特征;
15、将和化池和最大池相结合构建图级读出层,对整个图结构进行全局的读取和信息聚合,将所有节点和边的信息聚合起来生成全局图嵌入;
16、将生成的全局图嵌入送至softmax层,输出预测分类。
17、进一步的,所述双层图卷积神经网络之间采用残差连接,用于将下层学习到的信息整合到高层。
18、进一步的,不同层的图卷积神经网络制定相同的隐藏大小。
19、进一步的,所述可解释模型采用图神经网络解释器gnnexplainer。
20、进一步的,所述基于可解释模型对所述漏洞检测结果进行解释,得到函数源代码中导致漏洞的关键语句,包括:
21、将所述漏洞检测模型、待检测源代码的图结构和预测结果输入到图神经网络解释器gnnexplainer中;
22、根据输出的诱导子图和解释结构推导出影响预测结果的关键语句。
23、本发明还提供一种基于图神经网络和可解释模型的源代码漏洞检测装置,用于实现前述的基于图神经网络和可解释模型的源代码漏洞检测方法,所述装置包括:
24、预处理模块,用于提取函数源代码的代码表征,并将所述代码表征转换为图结构,形成源代码图集;
25、模型构建模块,用于搭建图神经网络模型,以所述源代码图集为输入,以函数源代码的漏洞分类结果为输出,训练所述图神经网络模型,得到最佳模型参数下的图神经网络模型作为漏洞检测模型;
26、检测模块,用于基于所述漏洞检测模型对待检测的函数源代码进行检测,得到漏洞检测结果;
27、解释模块,用于基于可解释模型对所述漏洞检测结果进行解释,得到函数源代码中导致漏洞的关键语句。
28、本发明的有益效果为:
29、(1)本发明提供一种基于图神经网络和可解释模型的源代码漏洞检测方法,采用pl预训练模型提取函数源代码的代码表示,再转换成图结构,采用图卷积神经网络进行漏洞检测。pl预训练模型具有很强的泛化能力,能够适应多种编程语言和任务,同时预训练模型能够为源代码提供丰富的语义信息,从而在下游任务中达到更好的漏洞检测性能。
30、(2)本发明使得漏洞检测模型具备了可解释的能力,模型的可解释能力能够使模型更具信任度,通过可视化和解释模型发现的漏洞,能够更好地解释为什么特定的代码片段可能存在潜在的安全风险。另外可解释模型能够有效的定位漏洞风险行,可以帮助开发人员更快地识别和修复潜在的安全问题,从而提高修复效率和系统安全性。
- 还没有人留言评论。精彩留言会获得点赞!