一种基于深度学习的电力中文文本挖掘方法及装置与流程
本发明涉及一种基于深度学习的电力中文文本挖掘方法及装置,属于电气工程故障诊断。
背景技术:
1、电力文本挖掘应用需求场景很多,具有很高的研究价值,由于我国相关研究起步较晚,知识和技术相对匮乏,所以目前文本挖掘技术在我国电力行业应用较少,大部分研究内容还属于试验阶段,相较于自然语言处理在互联网、医学等领域成熟的应用相比,电力中文文本处理应用效益未曾显现。
2、在现有技术中,电力海量信息的结构类型繁杂,其中中文文本信息常常因重要的事情才被记录下来,即被记录的信息可认为具有高价值,因此电力信息文本挖掘是从高价值信息蓝海中搜寻重要征兆,是电力设备健康状态预警与管控重点关注的技术,然而,对于文本信息的记录,大多没有固定的逻辑与格式,往往伴有个体主观性、书写随意、逻辑不清、口语化表达、错别字等,使得在处理文本信息数据时,不能很好地结构化管理,降低了文本信息数据的价值。
3、因此,亟需提出一种文本挖掘技术帮助巡检人员结构化处理缺陷文本数据、自动化判断设备故障严重等级,其对及时发现设备缺陷及检修计划的安排具有重要意义。
技术实现思路
1、本发明的目的在于克服现有技术中的不足,提供一种基于深度学习的电力中文文本挖掘方法及装置,能够满足快速、高效的结构化管理电力设备的文本数据和挖掘文本数据之间潜在关联关系的实际需求,提高了文本信息数据的价值。
2、为达到上述目的,本发明是采用下述技术方案实现的:
3、第一方面,本发明提供了一种基于深度学习的电力中文文本挖掘方法,包括以下步骤:
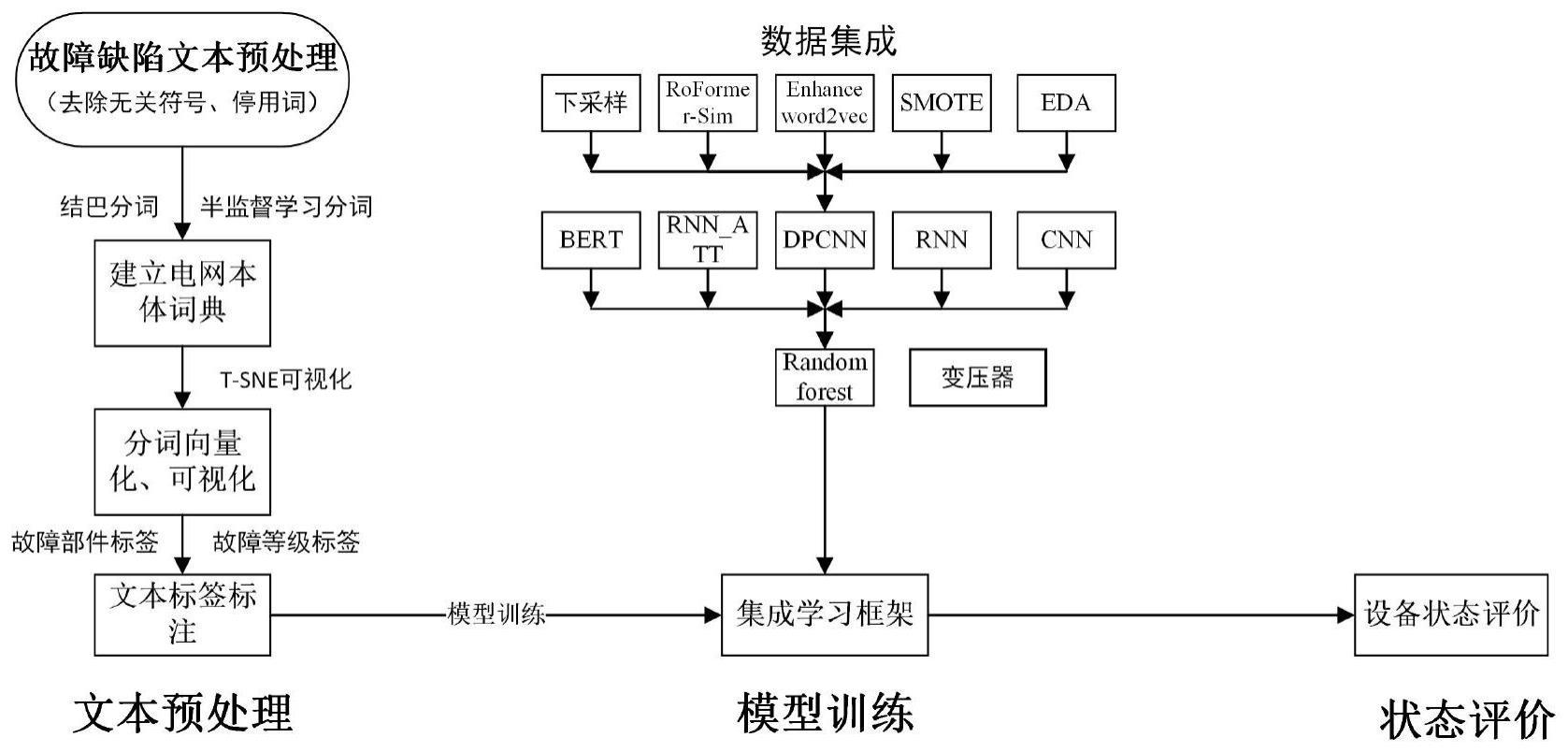
4、s1,获取电力故障缺陷文本,并对所述电力故障缺陷文本进行预处理,建立电网本体词典;
5、s2,根据所述电网本体词典,利用中文文本扩增的方法对所述电力故障缺陷文本的数据集进行类别平衡化;
6、s3,基于类别平衡化后的电力故障缺陷文本的数据集,得到数字化的故障文本;
7、s4,结合集成模型,以神经网络模型为元学习器,以随机森林模型为次级学习器,建立电力设备缺陷深度分析模型;
8、s5,基于数字化的故障文本,将非结构化缺陷描述转化为缺陷部件、缺陷属性的结构化信息,融合缺陷文本中附属结构化信息,对所述电力设备缺陷深度分析模型进行预训练,训练期间对所述电力设备缺陷深度分析模型的参数进行优化选择;
9、s6,根据所述电力设备缺陷深度分析模型,输入大批量电力设备缺陷文本,得到其中的电力实体词以及这段文本反映的电力设备可能存在的故障类型及其部位以及故障发生的季节信息,对电力设备家族性缺陷和季节性故障进行挖掘分析。
10、进一步的,所述步骤s1中,对电力故障缺陷文本进行预处理包括:去除无关用词、停用词。
11、进一步的,所述步骤s1中,对电力故障缺陷文本进行预处理,建立电网本体词典,包括以下步骤:
12、s101,采用基于通用字典的结巴分词模型对电力故障缺陷文本进行初始分词,对分词结果按照词频进行排序,专家对高频词语进行复查,形成初始词典;
13、s102,将所述初始字典作为外部词典导入;
14、s103,将人工甄选的词语加入到词典之中,重复步骤s102,直至分词效果达到满意为止。
15、进一步的,所述步骤s2中,利用中文文本扩增的方法包括:
16、利用eda、enhance_word2vec、roformer-sim对所述电力故障缺陷文本中的中文文本进行扩增。
17、eda在小文本数据集的应用表现较为良好,能很好提升文本分类的性能。主要包含以下4种方式(1)同义词替换:以一定概率p随机抽取1个词(不包括停用词),然后从词典找出抽取词的近义词表达,并将其替换。这个方法一般不会改变原句的语义以及结构。(2)随机概率插入:以一定概率p随机抽取1个词(不包括停用词),然后选择一个该词的同义词,插入原句子中的随机位置。(3)随机概率交换:以一定概率p随机交换两个词的位置。(4)随机概率删除:对于每一个单词,都有一定p的概率会被随机删除。
18、进一步的,所述步骤s3,基于类别平衡化后的电力故障缺陷文本的数据集,得到数字化的故障文本,包括:
19、根据所述电网本体词典,通过手工构建以及结合正则表达式匹配的方式,对文本中的地名、变电站名进行去除,利用word2vec模型的文本向量化表示,将所述电力故障缺陷文本中的中文文本的数据转化为计算机能处理的数字化数据。
20、进一步的,所述步骤s5中,对所述电力设备缺陷深度分析模型进行训练,具体有以下步骤:
21、s501,基于所述电网本体词典,建立训练集,将所述训练集以概率p通过eda方法、enhance_word2vec方法、roformer-sim模型进行数据扩增,在所述类别平衡化后的电力故障缺陷文本的数据集层面增强模型的泛化能力,生成第一新数据集;
22、s502,将所述第一新数据集依次进行五折交叉验证划分,对所述神经网络模型进行训练,将预测数据集进行组成,构成第二新数据集;
23、s503,将所述第二新数据集在所述随机森林模型进行训练,最终得到预测结果。
24、进一步的,所述步骤5中,将非结构化缺陷描述转化为缺陷部件、缺陷属性的结构化信息,包括:
25、统计电网中电力设备的故障类别、故障严重程度、故障时间以及故障次数。
26、进一步的,所述电网中电力设备为变压器。
27、第二方面,本发明提供一种基于深度学习的电力中文文本挖掘装置,所述装置包括:
28、词典模块:用于对电力故障缺陷文本进行预处理,建立电网本体词典;
29、扩增模块:用于根据所述电网本体词典,利用中文文本扩增的方法对所述电力故障缺陷文本的数据集进行类别平衡化;
30、数字化模块:用于基于类别平衡化后的电力故障缺陷文本的数据集,得到数字化的故障文本;
31、模型模块:用于结合集成模型,以神经网络模型为元学习器,以随机森林模型为次级学习器,建立电力设备缺陷深度分析模型;
32、训练模块:用于基于数字化的故障文本,将非结构化缺陷描述转化为缺陷部件、缺陷属性的结构化信息,融合缺陷文本中附属结构化信息,对所述电力设备缺陷深度分析模型进行训练,训练期间对所述电力设备缺陷深度分析模型的参数进行优化选择;
33、分析模块:用于根据所述电力设备缺陷深度分析模型,对电力设备家族性缺陷和季节性故障进行挖掘分析。
34、第三方面,本发明提供一种基于深度学习的电力中文文本挖掘装置,包括处理器及存储介质;
35、所述存储介质用于存储指令;
36、所述处理器用于根据所述指令进行操作以执行根据第一方面所述方法的步骤。
37、与现有技术相比,本发明所达到的有益效果:
38、(1)本发明使用半监督学习方法建立了电网本体词典,本体字典蕴含了电力领域最基本的知识单元,其质量与数量不仅决定着文本预处理中分词、词性标注等的准确性,也影响着消除歧义、构建知识图谱等工作,是电力文本挖掘中最根本的知识库;
39、(2)本发明对实际缺陷文本进行研究,分析指出了电力缺陷文本的格式、内容、特点以及常见文本质量问题,为缺陷文本的处理提供了新的思路;
40、(3)本发明以神经网络模型作为元学习器,以随机森林模型作为次级学习器构建了集成模型,在保证模型精度的同时,为了提升其泛化能力,引入了eda方法、enhance_word2vec方法、roformer-sim模型等中文文本增强技术对数据集进行扩充;神经网络模型中dropout机制抑制过拟合,实例分析证明,模型的准确率可达到91%,能解决实际工程应用中非结构化数据难处理的问题;
41、(4)本发明将非结构化缺陷描述转化为缺陷部件、缺陷属性等结构化信息后,结合缺陷文本中附带的结构化信息,建立电力设备缺陷深度分析模型,实例分析表明,所提出的方法能帮助及时发现电力设备家族性缺陷和季节性故障,辅助设备选型和运维决策都具有指导意义;
42、(5)本发明提出一种基于深度学习的电力中文文本挖掘方法及装置,能够满足快速、高效的结构化管理电力设备的文本数据和挖掘文本数据之间潜在关联关系的实际需求,提高了文本信息数据的价值。
- 还没有人留言评论。精彩留言会获得点赞!