一种大数据批处理任务运行时间的预测方法和装置与流程
本发明涉及电数字数据处理,具体涉及一种大数据批处理任务运行时间的预测方法和装置。
背景技术:
1、目前,大数据批处理在实际的软件项目开发中变得越来越常见。并且大数据的批处理任务数量呈现急剧增加的状态,在实际的生产中,受硬件资源和业务需求的限制,需要对这些大量的大数据任务进行有效管理,以达到最大限度的利用硬件资源,最块生产出业务数据的目标。但是大数据批处理任务受多种外部环境的影响,如何合理分配资源,有效的编排这些任务变得十分重要。当在已知的资源的情况下,需要管理这些任务,能够预测这些任务的运行时间就变得十分重要,可以在充分利用资源的情况下,选择时间最短的编排方法。
2、传统对应大数据批处理时间预测的方法主要有两种:1.通过相似度的方法来进行预测。即通过已经在环境上运行的已有的相似的任务,来评估目标任务的运行时间;2.通过因果关系的方法来进行预测。即充分评估影响任务运行的因素,例如硬件资源,带宽等,利用已经运行任务的执行结果,来进行任务运行时间的评估。
3、这两种方法都有一定的合理性,但是实际任务的运行时间,既要考虑任务相似度,又要考虑因果关系;另外这两种方法,都依赖于生产环境已经有运行日志的情况下,如果为初始化的环境,是无法对任务的运行时间进行预测的;并且相似度的方法,颗粒度比较粗,在实际的环境中,可能任务中的一个操作不同,就会造成实际运行时间差异较大;因果关系的方法主要考虑任务的外部因素,但是任务的本身,例如任务的操作个数,操作类型,每个操作的数据量,都会对运行时间有影响。
4、因此,需要能更加准确的进行大数据批处理时间预测的方法。
技术实现思路
1、本发明是为了解决大数据批处理时间预测的精度和效率问题,提供一种大数据批处理任务运行时间的预测方法和装置,结合相似度和因果关系两种方法,提出一套基准程序和基准数据对大数据批处理任务的运行时间进行预测,将批处理任务拆分为各个操作并分类,自定义基准数据,再将操作类型结合程序运行资源、服务器资源、数据集合信息通过基准程序在目标环境上使用基准数据运行以获得基准程序运行时间样本,使用基准程序运行时间样本训练模型,通过训练结果模型对拆分的待预测大数据批处理任务进行预测得到预测的批处理任务时间。本发明将批处理任务操作细分并结合时间影响因素,大大提高了预测的精度,且将通过自定义基准程序生成的各个操作运行日志数据作为模型训练样本,具有不依赖于历史日志数据,全面准确地预测大数据批处理任务运行时间的能力,保证了整体调度资源分配的合理性和运行时间的最小化。
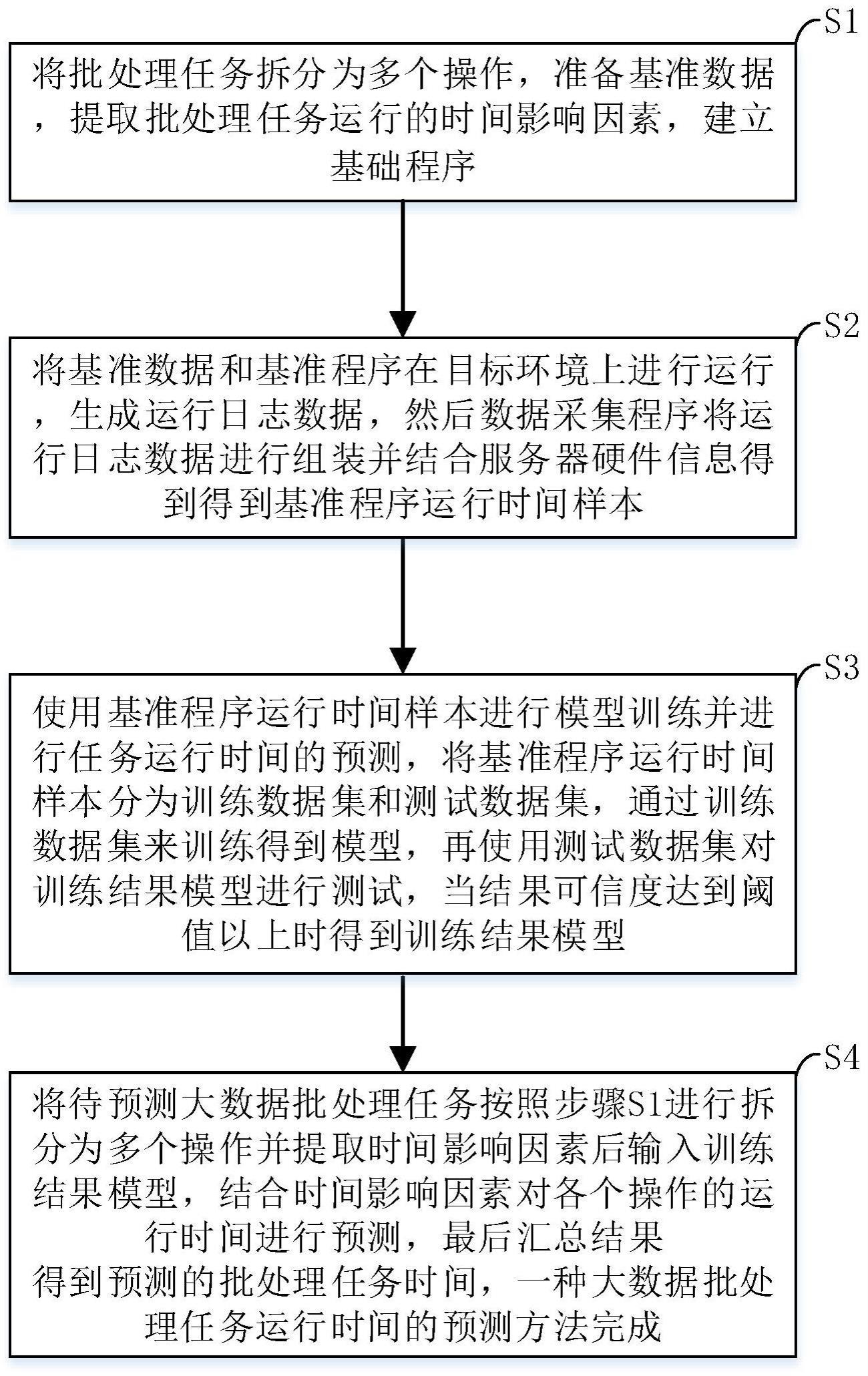
2、本发明提供一种大数据批处理任务运行时间的预测方法,包括以下步骤:
3、s1、将批处理任务拆分为多个操作,准备基准数据,提取批处理任务运行的时间影响因素并建立基础程序;
4、s2、将基准数据和基准程序在目标环境上进行运行,生成运行日志数据,然后数据采集程序将运行日志数据进行组装并结合服务器硬件信息得到得到基准程序运行时间样本;
5、s3、使用基准程序运行时间样本进行模型训练并进行大数据批处理任务运行时间的预测,将基准程序运行时间样本分为训练数据集和测试数据集,通过训练数据集来训练得到模型,再使用测试数据集对模型进行测试,当结果可信度达到阈值以上时得到训练结果模型;
6、模型根据操作类型结合程序运行资源字段影响因素的运行时间样本、操作类型结合服务器资源字段影响因素的运行时间样本、操作类型结合数据集合信息字段影响因素的运行时间样本进行学习并预测运行时间;
7、s4、将待预测大数据批处理任务按照步骤s1进行拆分为多个操作并提取时间影响因素后输入训练结果模型,结合时间影响因素对各个操作的运行时间进行预测,最后汇总结果得到预测的批处理任务时间,一种大数据批处理任务运行时间的预测方法完成。
8、本发明所述的一种大数据批处理任务运行时间的预测方法,作为优选方式,步骤s1包括:
9、s11、将批处理任务依据任务的子节点拆分为多个操作并进行分类得到操作类型,操作类型包括:输入操作、行处理操作、列处理操作、输出操作、流程控制操作和扩展节点操作;
10、s12、准备至少两份基准数据,基准数据的信息包括:数据量、存储介质、字段数量、数据容量、数据编码;
11、s13、提取批处理任务的时间影响因素,时间影响因素包括:程序运行资源字段影响因素、服务器资源字段影响因素和数据集合信息字段影响因素;
12、s14、针对每一个操作类型结合基准数据的信息、时间影响因素形成一个基准程序流程,再将全部的基准程序流程合成得到基准程序。
13、本发明所述的一种大数据批处理任务运行时间的预测方法,作为优选方式,步骤s11、s3中,输入操作包括:读数据库表、读文件系统和读中间件,行处理操作为对数据记录的行进行处理的操作,列处理操作为对数据记录的列进行处理的操作,输出操作为数据写操作,输出操作包括:写数据库表、写文件系统和写中间件;
14、批处理任务按操作类型拆分为6大类、153小类并进行编号。
15、本发明所述的一种大数据批处理任务运行时间的预测方法,作为优选方式,基准数据的数量为3个、数据量和数据容量均递增,且数据不重复、各字段取值随机分布、提供表结构。
16、本发明所述的一种大数据批处理任务运行时间的预测方法,作为优选方式,步骤s12中,程序运行资源字段影响因素包括:驱动程序使用内存的大小、每个执行器内存的大小、每个执行器使用的核数和启动的执行器总数量;
17、服务器资源字段影响因素包括:硬盘读速率、硬盘写速率和网络带宽;
18、数据集合信息字段影响因素包括:数据集合1数据量-数据条数、数据集合1数据量-数据容量、数据集合1数据字段个数、数据集合2数据量-数据条数、数据集合2数据量-数据容量和数据集合2数据字段个数。
19、本发明所述的一种大数据批处理任务运行时间的预测方法,作为优选方式,步骤s11中,根据拆分的操作得到运行文件;步骤s12中,根据基准数据信息得到数据文件;
20、步骤s14中,根据步骤s11中拆分的操作类型对基准数据进行初始化得到配置文件,实现各个操作类型的大数据批任务,结束后调用日志输出工具类,输出操作日志;
21、基准程序流程为:获取程序运行范围配置,找出启用为1的操作类型,形成待处理操作类型集合;利用枚举工具类,由待处理操作类型集合关联出待处理实现类;求出运行参数,运行参数包括运行内存上限、运行核数上限、驱动程序使用内存大小范围、执行器数量上限;通过遍历驱动程序使用内存、遍历执行器、遍历执行器内存大小、遍历每个执行器使用的核数、遍历基准数据编码集合得到运行参数集合;根据运行参数集合逐个调用待处理实现类,实现类根据数据编码枚举,获取对应组件的连接方式,从对应组件中获取数据,操作后将输出处理结果数据到大数据仓库输出表中,调用日志输出工具类并将操作日志输出至大数据的数据仓库中;程序输出,输出基准程序执行日志结果表,基准程序执行日志结果表的表字段包括:程序运行资源字段影响因素、数据集合信息字段影响因素、操作类型和处理时间。
22、本发明所述的一种大数据批处理任务运行时间的预测方法,作为优选方式,步骤s2中,数据采集程序的输入为大数据的数据仓库中的基准程序执行日志结果表,数据采集程序通过脚本得到目标环境上服务器的硬件资源情况并与基准程序执行日志结果表合并后写入csv文件中,基准程序运行时间样本包括:操作类型结合程序运行资源字段影响因素的运行时间样本、操作类型结合服务器资源字段影响因素的运行时间样本和操作类型结合数据集合信息字段影响因素的运行时间样本。
23、本发明所述的一种大数据批处理任务运行时间的预测方法,作为优选方式,步骤s3中,模型训练的方法为:随机森林算法或朴素贝叶斯算法。
24、本发明所述的一种大数据批处理任务运行时间的预测方法,作为优选方式,步骤s3中,阈值为90%。
25、本发明提供一种大数据批处理任务运行时间的预测方法的装置,包括基准程序生成模块、样本数据采集模块、模型训练模块、时间预测模块和数据调度模块;
26、基准程序生成模块建立基础程序,样本数据采集模块采集基准数据和基准程序在目标环境上运行的日志数据并结合服务器硬件信息得到得到基准程序运行时间样本,模型训练模块使用基准程序运行时间样本进行模型训练得到训练结果模型,时间预测模块将待预测大数据批处理任务拆分为多个操作、提取时间影响因素并使用训练结果模型对每个操作进行时间预测后进行汇总得到预测的批处理任务时间,数据调度模块按顺序调用样本数据采集模块、模型训练模块和时间预测模块进行工作。
27、本发明提供一种大数据批处理任务运行时间的预测方法和装置的方案:
28、基准程序生成模块:本模块为整体方案的前置工作,为核心模块。主要流程为将所有的批处理任务进行拆分为各个操作,并分类,同时自定义三份基准数据,再结合程序运行资源,服务器资源,数据集合信息这些参数,进行组合,针对三份基准数据进行初始化,将参数和初始化的基准数据作为输入参数,为每个操作定义为一个大数据批处理任务,并按照标准格式记录运行时间日志进行入库。
29、样本数据采集模块:本模块的主要功能是利用基准程序和基准数据,在目标环境上进行运行,形成基准程序运行日志数据,然后通过样本数据采集程序,将基准程序运行数据和服务器硬件资源信息组装,形成大数据批处理的操作样本数据。输入为基准程序的运行输入,包括程序运行操作类型范围配置,程序运行参数配置,程序运行基准数据范围配置,以及基准数据。
30、本模块会先选定需要评估的目标集群环境,在环境上部署基准程序,初始化程序运行操作类型范围配置,程序运行参数配置,程序运行基准数据范围配置。根据操作范围,将基准数据初始化到对应的环境中。然后运行基准程序,直至基准程序全部运行完成,这样基准程序执行日志全部入库到大数据的数据仓库中。
31、最后运行数据采集程序,从大数据仓库中获取基准程序运行日志,并且利用脚本得到服务器的硬件资源情况,将这两块的数据进行合并,形成基准程序运行时间样本的csv文件。
32、模型训练模块:本模块的主要功能是用基准程序运行样本数据,利用人工智能算法,形成训练模型,并持久化。
33、输入参数为基准程序运行时间样本的csv文件,模块会加载样本数据,然后将样本按照8:2的方式,形成训练数据集和测试数据集。利用机器学习算法,将训练数据集来训练得到模型,再利用测试数据集对训练结果模型进行测试,当结果可信度达到阈值(例如90%)以上,则将模型持久化到本地。
34、时间预测模块:本模块主要功能是拆分目标任务,细分到操作粒度,用训练好的模型,对各个任务的操作进行时间预测,最后汇总结果,形成目标任务的预测时间。先要对目标任务进行拆解,形成任务和操作类型的对应关系。然后针对每个操作类型,明确清楚运行参数,资源参数,这样,操作类型,运行参数,资源参数形成每个操作的参数数据集。本部分需要分析运行任务的相关源代码,人工形成参数数据集。
35、然后读取训练后的持久化模型,对所有的操作数据集进行遍历,就能预测出每个操作的运行时间,形成任务操作预测结果表。最后读取任务和操作类型的对应关系后,再读取任务操作预测结果表,对任务的操作,根据操作类型编码,找到预测的操作处理时间,对该任务下的所有任务操作处理时间进行累加,形成任务的预测时间结果。
36、数据调度模块:将上述整体模块串联起来,本模块对外是一个大的脚本任务。内部分为三个部分:
37、1)样本数据采集模块
38、2)模型训练模块
39、3)时间预测模块。
40、本发明具体简化的操作方式如下:
41、1.基准程序生成模块
42、1.1将批处理任务根据子操作拆分成若干个操作,并对操作分类
43、1.2自定义一套基准数据,满足多种数据量和数据容量要求
44、1.3提取影响批处理任务的因素,包括程序运行资源,服务器资源
45、1.4综合上述内容,将1.1中的操作类型也作为一种影响因素,即可以将影响因素和相似度结合,形成了全部的影响因素,包括程序运行资源,服务器资源,数据集合情况(1.2中定义),操作类型
46、1.5针对每一个操作类型,形成一个基准程序流程,然后将全部的操作一起,最终形成一整套基准程序
47、2.样本数据采集模块
48、2.1基础程序日志数据生成
49、2.1.1在实际的运行集群上,对每一个操作,按照影响因素进行不同维度组合,形成输入参数,对基准程序进行运行,形成程序运行资源,服务器资源,数据集合情况,操作类型,程序运行时间的数据;
50、2.1.2所有的操作运行完,则形成了集群对于各个操作的运行日志数据;
51、2.2样本数据采集
52、2.2.1利用脚本获取服务器硬件情况
53、2.2.2对2.1.2中的各个操作的运行日志数据进行组装,结合2.2.1的数据,形成批处理操作样本数据;
54、2.2.3将批处理操作样本数据保存为csv,方便后续模型使用;
55、2.模型训练模块
56、2.1将上述数据,利用人工智能算法,进行模型训练;
57、3.时间预测模块
58、3.1针对具体的待预测的批任务,根据子操作拆分成若干个操作,并收集好其他的影响因素,包括程序运行资源,服务器资源,数据集合情况,则会有若干个操作类型的影响因素,包括程序运行资源,服务器资源,数据集合情况,操作类型;
59、3.2将2.1中训练的模型,对3.1中的每个操作类型进行预测,得到预测的各个操作的运行时间,最后累加,形成具体的待预测的批任务的预测时间。
60、本发明具有以下优点:
61、(1)本发明相较于传统方式,将任务细化到操作的颗粒度,利用自定义的基准程序进行各个操作的运行日志数据生成,具有不依赖于历史日志数据,全面准确地预测大数据批处理任务运行时间的能力,保证了整体调度资源分配的合理性和运行时间的最小化;
62、(2)经过对具体的批处理,包括读大数据仓库表,行过滤,写大数据仓库表的流程进行预测,大大提高了预测的精度,本发明在程序实际运行时间为79秒时,预测的时间在78.14秒到81.21秒之间,预测准确度达到95%以上。
- 还没有人留言评论。精彩留言会获得点赞!