一种基于数据融合的关务数据处理系统、方法及介质与流程
本发明涉及人工智能,尤其涉及一种基于数据融合的关务数据处理系统、方法及介质。
背景技术:
1、国际贸易是经济发展的重要推动力之一,关务数据可以提供对进出口货物的详细信息,包括数量、价值、品牌等,从而帮助企业了解贸易流动情况,分析市场需求和趋势,为制定经济政策和商业决策提供依据。通过对关务数据的处理和分析,可以促进贸易畅通,优化供应链,提高市场竞争力,从而推动经济的稳定和增长。
2、由于关务数据涉及多个环节和多个部门,包括进出口商、海关、运输公司等,这些各方之间的数据收集和整理方式可能不统一,数据格式和标准存在差异,导致数据的收集和整理工作相对繁琐和复杂,同时,处理过程中可能需要跨部门或跨机构协同工作,由于沟通和协作的问题导致处理流程冗长,从而导致关务数据处理时的效率较低。
技术实现思路
1、本发明提供一种基于数据融合的关务数据处理系统、方法及介质,其主要目的在于解决自助收银时的效率较低的问题。
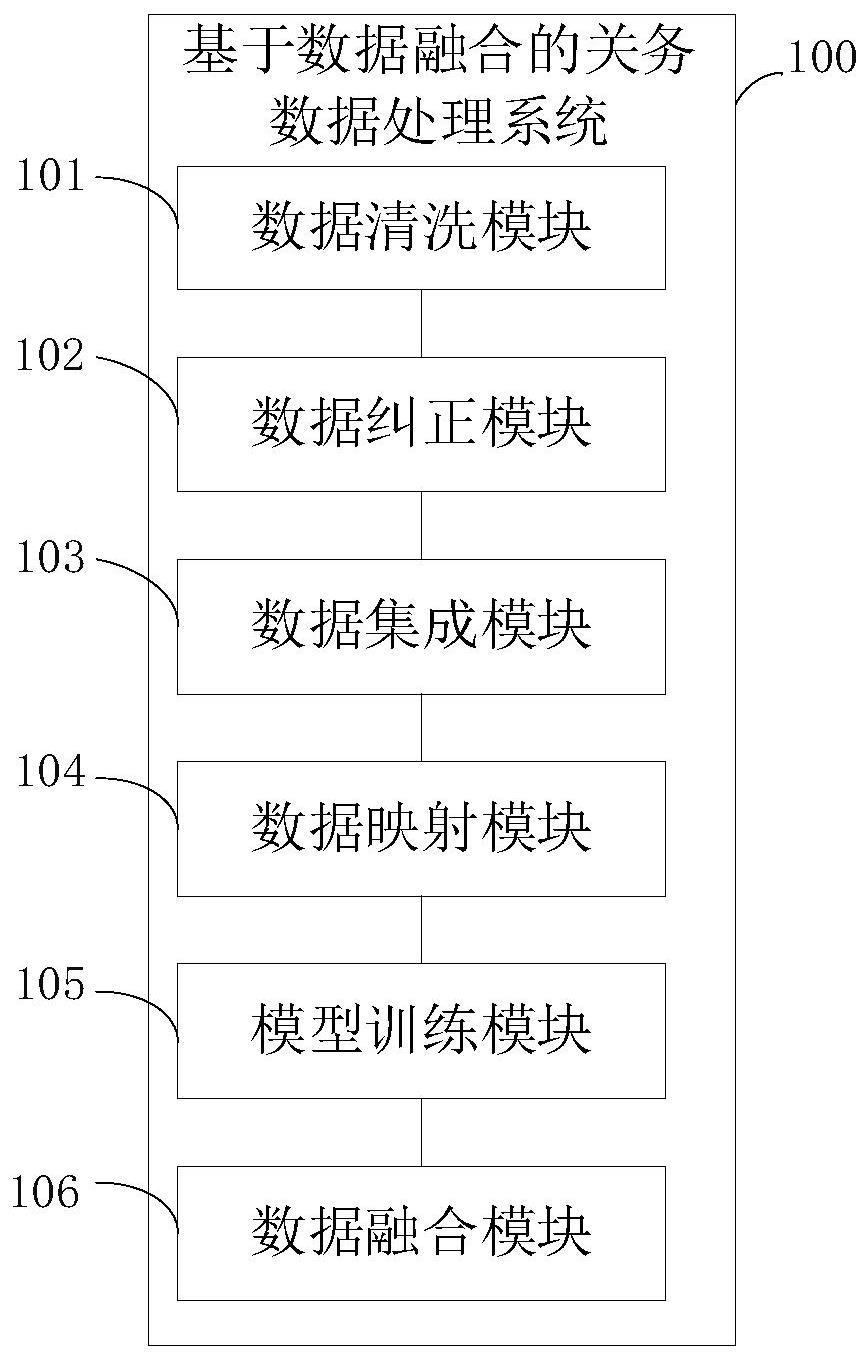
2、为实现上述目的,本发明提供的一种基于数据融合的关务数据处理系统,其特征在于,所述系统包括数据清洗模块、数据纠正模块、数据集成模块、数据映射模块、模型训练模块及数据融合模块,其中:
3、所述数据清洗模块,用于生成预先采集的多源关务数据的清洗数据;
4、所述数据纠正模块,用于生成所述清洗数据的数据冲突值,根据所述数据冲突值对所述清洗数据进行数据纠正,得到所述清洗数据的纠正数据;
5、所述数据集成模块,用于根据所述纠正数据的关键字段生成所述纠正数据的集成数据;
6、所述数据映射模块,用于对所述集成数据进行数据映射,得到所述集成数据的映射数据;
7、所述模型训练模块,用于利用所述映射数据和预设的目标函数对预先构建的数据融合模型进行模型训练,得到训练完成的数据融合模型,其中,所述预设的目标函数为:
8、
9、其中,y是目标函数值,min(*)是最小化函数,w是所述数据融合模型需要训练的权重向量,wt是所述权重向量的转置,b是所述数据融合模型需要训练的偏置项,ξi是第i个训练数据所对应的松弛变量,c是正则化参数,i是所述训练数据的数据标识,l是所述训练数据的数据总数;
10、所述数据融合模块,用于利用所述训练完成的数据融合模型对实时关务数据进行数据融合,得到所述实时关务数据的融合数据。
11、可选地,所述数据清洗模块在生成预先采集的多源关务数据的清洗数据时,具体用于:
12、根据预先采集的多源关务数据的数据来源对所述多源关务数据进行数据去重,得到所述多源关务数据的去重数据;
13、对所述去重数据进行缺失值填充,得到所述去重数据的填充数据;
14、对所述填充数据进行异常值处理,得到异常值处理后的填充数据,确定所述异常值处理后的填充数据为所述多源关务数据的清洗数据。
15、可选地,所述数据纠正模块在生成所述清洗数据的数据冲突值时,具体用于:
16、对所述清洗数据进行特征提取,得到所述清洗数据的数据特征;
17、对所述数据特征进行哈希映射,得到所述数据特征的哈希值;
18、利用所述哈希值生成所述数据特征的标识符;
19、根据所述标识符和所述标识符所对应的数据来源生成所述清洗数据的数据冲突值。
20、可选地,所述数据纠正模块在根据所述数据冲突值对所述清洗数据进行数据纠正,得到所述清洗数据的纠正数据时,具体用于:
21、s11、当所述数据冲突值大于预设的冲突阈值,确定所述数据冲突值所对应的清洗数据为待纠正数据;
22、s12、逐个生成所述待纠正数据的候选选项;
23、s13、根据所述候选选项和所述待纠正数据的投票顺序对所述待纠正数据中的第一个待纠正数据进行投票决策,得到所述第一个待纠正数据的第一个投票结果;
24、s14、根据所述第一个投票结果对所述待纠正数据进行数据更新,得到所述待纠正数据的更新数据;
25、s15、逐个生成所述更新数据的候选选项,返回步骤s13,直至所述待纠正数据中的全部纠正数据都完成投票决策,根据投票决策的决策结果对所述待纠正数据进行数据纠正,得到所述清洗数据的纠正数据。
26、可选地,所述数据集成模块在根据所述纠正数据的关键字段生成所述纠正数据的集成数据时,具体用于:
27、提取所述纠正数据的关键字段,计算所述关键字段的字段相似度;
28、根据所述字段相似度对所述纠正数据进行数据匹配,得到所述纠正数据的匹配数据;
29、对所述匹配数据进行数据集成,得到所述匹配数据得分集成数据。
30、可选地,所述数据集成模块在计算所述关键字段的字段相似度时,具体用于:
31、利用如下相似度算法计算所述关键字段的字段相似度:
32、
33、其中,s是所述关键字段的字段相似度,a是所述关键字段中第一个字段的字段向量,b是所述关键字段中第二个字段的字段向量,w是所述字段向量所对应的权重向量,w⊙b表示所述关键字段中第二个字段的字段向量b与所述字段向量所对应的权重向量w的元素逐一相乘得到的加权向量,a·(w⊙b)表示将所述关键字段中第一个字段的字段向量a与所述加权向量w⊙b的内积运算。
34、可选地,所述数据映射模块在对所述集成数据进行数据映射,得到所述集成数据的映射数据时,具体用于:
35、对所述集成数据进行数据归一化,得到所述集成数据的归一化数据;
36、根据所述集成数据的排列顺序生成所述归一化数据的数据序列;
37、构建所述归一化数据的数据词典,利用所述数据词典对所述数据序列中的归一化数据逐个进行数据映射,得到所述数据序列的映射序列,根据所述映射序列确定所述集成数据的映射数据。
38、可选地,所述模型训练模块在利用所述映射数据和预设的目标函数对预先构建的数据融合模型进行模型训练,得到训练完成的数据融合模型时,具体用于:
39、根据所述映射数据生成所述数据融合模型的训练数据;
40、确定所述数据融合模型的模型参数空间,在所述模型参数空间中遍历所述数据融合模型的参数组合;
41、逐个根据所述参数组合对所述数据融合模型进行参数配置,得到配置完成的数据融合模型;
42、利用所述训练数据和预设的目标函数对所述配置完成的数据融合模型进行交叉验证,根据交叉验证的验证结果生成所述数据融合模型的最优参数;
43、利用所述最优参数对所述数据融合模型进行最优配置,得到训练完成的数据融合模型。
44、为了解决上述问题,本发明还提供一种基于数据融合的关务数据处理方法,所述方法包括:
45、s1、生成预先采集的多源关务数据的清洗数据;
46、s2、生成所述清洗数据的数据冲突值,根据所述数据冲突值对所述清洗数据进行数据纠正,得到所述清洗数据的纠正数据;
47、s3、根据所述纠正数据的关键字段生成所述纠正数据的集成数据;
48、s4、对所述集成数据进行数据映射,得到所述集成数据的映射数据;
49、s5、利用所述映射数据和预设的目标函数对预先构建的数据融合模型进行模型训练,得到训练完成的数据融合模型,其中,所述预设的目标函数为:
50、
51、其中,y是目标函数值,min(*)是最小化函数,w是所述数据融合模型需要训练的权重向量,wt是所述权重向量的转置,b是所述数据融合模型需要训练的偏置项,ξi是第i个训练数据所对应的松弛变量,c是正则化参数,i是所述训练数据的数据标识,l是所述训练数据的数据总数;
52、s6、利用所述训练完成的数据融合模型对实时关务数据进行数据融合,得到所述实时关务数据的融合数据。
53、为了解决上述问题,本发明还提供一种存储介质,所述存储介质中存储有至少一个计算机程序,所述至少一个计算机程序被电子设备中的处理器执行以实现上述所述的基于数据融合的关务数据处理方法。
54、本发明实施例通过生成预先采集的多源关务数据的清洗数据,并根据数据冲突值对清洗数据进行纠正,可以自动化地清理和修复数据,同时,基于纠正数据的关键字段生成集成数据,并对集成数据进行数据映射,可以将来自不同源头的数据整合为一体,并建立映射关系,这样可以简化数据的查询和分析,节省了人工查找和整合数据的时间,对预先构建的数据融合模型进行训练,得到一个优化的权重向量和偏置项。这种基于模型的数据融合方法可以更加准确地将各个数据源的信息进行融合,提高数据融合的精度和效率,这些步骤充分利用了计算机技术和数据科学的方法,减少了人工操作的需求,并通过优化算法和模型来提高数据处理的速度,因此本发明提出的基于数据融合的关务数据处理系统及方法,可以提高关务数据处理时的效率。
- 还没有人留言评论。精彩留言会获得点赞!