一种基于联邦学习的时空轨迹聚类方法
本发明涉及大数据挖掘,具体涉及一种基于联邦学习的时空轨迹聚类方法。
背景技术:
1、近些年,随着大数据技术的发展,以及计算机技术的进步,机器学习越来越受到关注,在推荐算法,智能驾驶,人机交互等多个方面都起到了重要的作用。但是由于机器学习和大数据行业的生长,以及实际环境中的复杂性,形成了数据总量极多,数据可用量少,数据质量差的情况。并且,由于受到安全性因素的影响,限制了数据的交流和分享,影响了大数据和机器学习技术的研究和应用,这种现象称为“数据孤岛”。
2、谷歌在2016年另辟蹊径,提出了联邦学习(federated learning,fl)的理念。简单地说,联邦学习要求参与学习的数据集不移动,而模型训练在拥有数据集的客户端上独立完成。之后由一个可信的虚拟中心收集客户端上训练好的模型,将模型聚合后再发送给客户端继续训练,循环往复最后生成一个可用的全局模型。这种计算向数据移动的方式,极大的避免了数据移动可能产生的安全风险。从侧面解决了大数据和机器学习领域中的“数据孤岛”问题,受到了越来越多的研究和关注。但是,在现实场景中,轨迹等数据的联邦学习具有局限性,带宽消耗和隐私问题都阻碍了这种类型的处理。
技术实现思路
1、本发明所要解决的技术问题是:提出一种基于联邦学习的时空轨迹聚类方法,节约通信带宽,并提高数据处理的隐私性。
2、本发明解决上述技术问题采用的技术方案是:
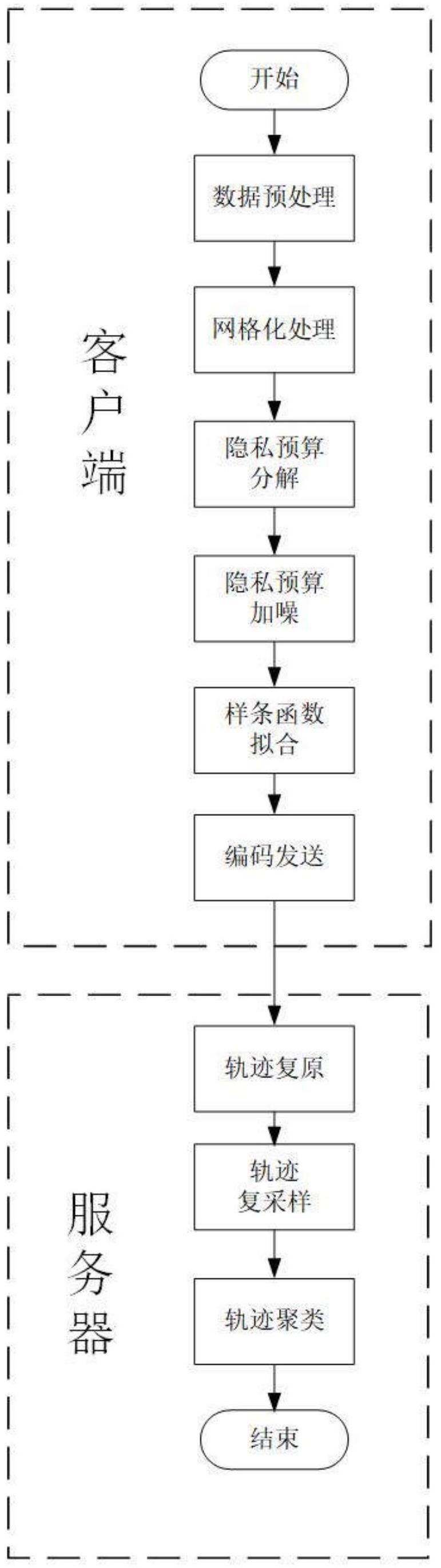
3、一种基于联邦学习的时空轨迹聚类方法,应用于采用联邦学习架构的分布式系统,所述分布式系统包括服务器和多个客户端,该方法包括:
4、a、客户端处理过程:
5、a1、对客户端的本地轨迹,进行遍历采样,获得一组具有相同起点和终点的轨迹;
6、a2、针对步骤a1采样获得的每一条轨迹,根据预设的间隔距离进行等距取点,获得其在轨迹空间中的轨迹点序列;
7、a3、针对步骤a1采样获得的每一条轨迹,并根据步骤a2获得的各轨迹的轨迹点序列,采用样条函数进行分段拟合;
8、a4、针对步骤a1采样获得的每一条轨迹,根据步骤a3的分段,将其各轨迹段的起止位置信息、起止时序信息以及对应样条函数的参数信息,按其所属轨迹和轨迹段进行编码,并发送至服务器;
9、b、服务器处理过程:
10、b1、服务器对接收到的信息进行解码,将属于相同轨迹的样条函数,根据样条函数的参数复原其所对应轨迹段,并根据对应轨迹段的起止位置信息和起止时序信息,顺序拼接获得对应轨迹的复原轨迹;
11、b2、对步骤b1获得的复原轨迹,进行聚类分析。
12、进一步的,步骤a2中,还包括:
13、根据该客户端预设的差分隐私总预算ε以及各轨迹上的轨迹点数量,为各轨迹分配与其轨迹点数量等比例的轨迹差分隐私参数εk;所述k为轨迹的序号;
14、然后,针对每一条轨迹,分别进行如下加噪处理:
15、对该轨迹的轨迹空间进行首次网格划分,判定是否满足每个网格中至多有一个轨迹点;针对不满足判定的网格进行二次网格划分,并使其满足每个网格中至多有一个轨迹点;
16、基于该轨迹各轨迹点所对应网格,分配该轨迹各轨迹点的差分隐私预算,每个轨迹点的差分隐私预算与其所在网格的边长成反比;所述i为轨迹点的序号;
17、对该轨迹上各轨迹点,分别根据其差分隐私预算进行差分加噪。
18、进一步的,步骤a2中,对该轨迹的轨迹空间进行首次网格划分,判定是否满足每个网格中至多有一个轨迹点;针对不满足判定的网格进行二次网格划分,并使其满足每个网格中至多有一个轨迹点,具体包括:
19、a21、根据设定数值n,将整个轨迹空间划分为n×n的均匀网格,每个网格的网格等级均为并获得网格集合;
20、a22、计算网格集合中每个网格的网格计数
21、
22、其中,dk表示第k条轨迹,表示第k条轨迹上的第i个轨迹点,表示第k条轨迹所对应轨迹空间经网格划分所获得的第n个网格,表示第k条轨迹中位于网格范围内的轨迹点的数量,|dk|表示第k条轨迹的全部轨迹点数量;
23、a23、遍历网格集合中每个网格的网格计数,判定其是否达到判定条件,所述判定条件为:网格的网格计数为0或者1/|dk|;并针对未满足判定条件的网格,执行步骤a24;
24、a24、按如下公式计算对应网格的二次划分参数m:
25、
26、其中,β为预定义的网格常数,为二次划分前该网格的网格计数,为上取整函数;
27、根据二次划分参数m,将对应网格二次划分为m×m的均匀子网格,并根据二次划分所获得的网格,对网格集合进行更新;子网格的网格等级设定为
28、a25、循环执行步骤a23-a24,直至完成遍历。
29、进一步的,步骤a21中,所述n设置为len(dk)/r,其中,r为步骤a2进行轨迹点采样的间隔长度,len(dk)表示第k条轨迹的长度。
30、进一步的,步骤a24中,所述β为80/εk,εk是第k条轨迹的隐私预算。
31、进一步的,步骤a2中,按如下公式,基于该轨迹各轨迹点所对应网格,分配该轨迹各轨迹点的差分隐私预算,每个轨迹点的差分隐私预算与其所在网格的边长成反比:
32、
33、其中,表示第k条轨迹上的第i个轨迹点的差分隐私参数;和分别表示第k条轨迹上的第i个和第s个轨迹点所属网格的等级,且网格等级与网格的边长成反比;|dk|表示第k条轨迹上所有轨迹点的数量。
34、进一步的,步骤a2中,按如下公式,对该轨迹上各轨迹点,分别根据其差分隐私预算进行差分加噪:
35、
36、其中,公式等号左侧表示差分加噪后第k条轨迹上的第i个轨迹点,公式等号右侧表示差分加噪前第k条轨迹上的第i个轨迹点,表示符合拉普拉斯分布的随机数,表示第k条轨迹上的第i个轨迹点所属网格的边长。
37、进一步的,步骤a3中,针对步骤a1采样获得的每一条轨迹,并根据步骤a2获得的各轨迹的轨迹点序列,采用样条函数进行分段拟合,具体包括:
38、a31、根据轨迹的曲率变化率将轨迹划分为多个轨迹段;
39、a32、采用样条函数对每个轨迹段分别进行拟合,拟合目标为如下最小化损失函数:
40、
41、其中,fl(·)为第l个轨迹段的样条函数,和分别为第l个轨迹段的第m个轨迹点的横、纵坐标;为计算值与实际值的损失,m为第l个轨迹段所包含轨迹点的数量,c是常数参数,j(fl)是样条函数fl(·)的多项式项数。
42、具体的,所述计算值fl(xm)与实际值ym的损失按如下公式进行计算:
43、
44、其中,fl(·)为第l个轨迹段的样条函数,和分别为第l个轨迹段的第m个轨迹点的横、纵坐标。
45、进一步的,步骤a31中,根据速度角判断轨迹的曲率变化率,并将轨迹划分为多个轨迹段,具体包括:
46、a311、计算轨迹上各轨迹点的速度角
47、
48、其中,表示第k条轨迹上的第i个轨迹点的速度角;和分别表示第k条轨迹上的第i个和第i+1个轨迹点的时间信息;分别表示第k条轨迹上的第i个轨迹点的横、纵坐标;分别表示第k条轨迹上的第i+1个轨迹点的横、纵坐标;
49、a312、根据如下约束条件:
50、
51、将轨迹划分为轨迹段,并确保各轨迹段满足约束条件,所述p和q分别表示轨迹段两端轨迹点的序号。
52、进一步的,步骤b2中,对步骤b1获得的复原轨迹进行复采样,分别获得各轨迹的复采样轨迹点序列,并基于各轨迹的复采样轨迹点序列进行聚类分析;所述各轨迹的复采样轨迹点序列包括该轨迹各轨迹段的起止点,以及基于该轨迹各轨迹段的样条函数按等时间间隔采样所获得的轨迹点,各轨迹段的采样数量与其时间占轨迹整体时间的比例成正比。
53、本发明的有益效果是:
54、基于本发明的方案,将轨迹通过样条函数进行拟合,将位置数据的传递变更为参数的传递,极大的节约了通信带宽;并且,通过拟合,并没有发生数据的移动,也即在保证轨迹整体准确性的前提下,又排除了位置数据的敏感性,提高数据处理的隐私性。最终,通过聚类分析,方便的得知轨迹数据集中哪些轨迹异常,哪些轨迹高重复,可以在避免安全、隐私风险的情况下进行分布式的轨迹聚类,用于排查异常轨迹和发现核心轨迹。可以用于涉密领域的异常轨迹排查、商业重要客户轨迹检索等多种场景。
55、进一步的,采用网格化方法对轨迹所在轨迹空间进行划分,从而根据轨迹上采样出的轨迹点所在网格的网格等级来为该轨迹点分配差分隐私参数,以采用差分隐私的方式对轨迹点数据进行加噪处理,提高了数据的隐私性。
- 还没有人留言评论。精彩留言会获得点赞!