一种基于神经辐射场的三维重建方法与流程
本发明属于图像处理领域,涉及一种基于图像的三维重建技术,具体涉及一种基于神经辐射场的三维重建方法。
背景技术:
1、三维重建是指通过计算机技术将现实世界中的物体或场景转换为数字化的三维模型。它在许多领域具有广泛的应用,包括虚拟现实、增强现实、计算机视觉、机器人技术等。三维重建可以通过不同的方法和技术实现,其中人体重建是三维重建领域的一个重要方向。
2、目前,有许多方法用于人体三维重建,包括基于深度相机的方法和基于多视角图像的方法。以下是一些现有技术方案的简要描述:
3、结构光方法:使用结构光相机或投影仪以及深度传感器,通过投射结构化光源并测量其反射来获取人体表面的三维形状信息。这种方法常用于静态场景下的人体重建。但对光照条件敏感,可能受到环境光的干扰,在户外或光线不均匀的场景下表现较差,对透明或反射表面的处理较困难。由于需要购买三维传感器等硬件设备,该技术成本远高于多视图方法。
4、多视角重建方法:利用多个摄像机或摄像机阵列以不同视角拍摄人体,然后通过图像匹配和三维重建算法恢复人体的三维形状和姿势。这种方法适用于静态场景下的人体重建。该方法仅需使用多视图影像即可完成高真实感的三维模型,本专利内容也属于此类方法。
5、在多视角重建方案中,较为具体的实现方案包括,可以将其分为基于特征匹配类的方法和基于神经辐射场类的方法。下面将对它们进行具体介绍:
6、基于特征匹配的方法:
7、基于特征匹配的多视角重建方法依赖于在多个视角下提取和匹配图像特征点,以恢复三维场景的几何结构和相机姿态。以下是该方法的一般流程:
8、特征提取和匹配:从每个视角的图像中提取关键点和其对应的描述符,通常使用一些特征检测和描述算法(如sift、surf、orb等)。通过比较不同视角下的特征描述符,进行特征匹配,建立不同图像之间的对应关系。
9、多视图立体匹配:指在稀疏特征点匹配的基础上,进一步在图像的每个像素位置上进行匹配,以获取更密集的深度或视差信息。密集匹配方法的步骤包括:匹配成本计算:计算每个像素位置上的匹配成本,用于衡量两幅图像中对应像素之间的相似度。常用的成本计算方法包括灰度差异、视差一致性等。匹配能量优化:基于计算得到的匹配成本,使用能量优化算法(如动态规划、图割等)来推断每个像素位置的最佳匹配,即确定每个像素的深度或视差值。插值和滤波:对于得到的密集深度或视差图,可以进行插值和滤波操作,以提高结果的平滑性和准确性。
10、网格重建:对生成的点云进行构网,输出mesh模型即通过将点云中的点连接起来形成三角面片,表示场景的几何结构,以去除噪声、填补空洞,并生成光滑的表面。常用的方法包括poisson重建和marching cubes等方法。
11、基于神经辐射场的方法:
12、神经辐射场是近年来3d视觉领域的研究热点,通过离散的多视图影像训练,它能够输出新视角非常高真实感的影像,它带来的技术突破同样可以应用于三维模型重建,有望解决现有技术方案难以处理的弱纹理,高反光问题。神经辐射场是一种基于神经网络的表示方法,用于对场景进行建模和重建。它通过训练神经网络来学习场景的隐式表示,可以捕捉几何形状和外观等信息。在神经辐射场方法中,场景被视为一个函数,该函数将输入的射线参数映射到场景的属性,如颜色、透明度等。通过训练神经网络,可以学习到这个映射关系,从而实现对场景的重建和渲染,其计算过程如附图3所示。神经辐射场方法能够对复杂的几何形状和细节进行建模,包括曲面、边缘和纹理等。其次,神经辐射场是连续的表示形式,可以实现高空间分辨率,从而提供更真实的视觉效果。此外,由于神经网络的强大学习能力,神经辐射场方法可以从有限的观测数据中推断出缺失的信息,实现对不完整数据的补全和重建。
13、然而,神经辐射场方法学习的是场景的隐式表示,众多神经辐射场方法以空间中所有位置的体密度来表达场景,而非关注于物体表面,因此它们提取的几何结构精度较低,噪声较大,而本专利提出一种更善于表面重建的符号距离函数(sdf)的体渲染方法,并且使用多视图几何图像一致性约束来提升表面重建质量。
14、现有神经辐射场技术能够实现高真实感影像的渲染,它基于体渲染方程从多视图颜色中学习空间的体密度和颜色。通过marching cube算法,可将其生成的体密度转化为mesh模型,但现有神经辐射场输出的mesh模型存在噪声大、精度低的问题,难以应用于实际中。
15、专利cn114972632a_基于神经辐射场的图像处理方法及装置,其中所述基于神经辐射场的图像处理方法包括:响应于图像处理指令确定采样位置信息、采样视角信息和目标对象图像;将所述采样位置信息、所述采样视角信息和所述目标对象图像输入至预先训练的神经辐射场模型处理,获得所述神经辐射场模型输出的每个取样点对应的密度信息、颜色特征值和符号距离函数值,其中,所述神经辐射场模型为机器学习模型;基于每个取样点对应的符号距离函数值确定至少两个取样点子集合;根据每个取样点子集合中取样点的密度信息和颜色特征值渲染生成每个取样点子集合对应的目标子对象,并基于每个目标子对象生成目标对象。其仍然是基于体密度进行三维重建,还是隐式表达,因此上述噪声大、精度低的问题任然没有很好解决,同时,一组数据通常需训练8个小时,网络收敛需要消耗大量的gpu算力。
技术实现思路
1、本发明的目的是针对现有技术中问题,提供一种基于神经辐射场的三维重建方法,是一种基于sdf的体渲染方法,约束体密度无偏的分布在物体表面,将神经辐射场中的体密度转化为sdf,并使用体渲染方程回归空间sdf和颜色。同时,本发明还提出使用多视图几何一致性来约束sdf为0的物体表面,通过优化物体表面的位置和朝向,使得表面纹理在多视图上是一致的,从而进一步提升生成mesh模型的质量。以解决现有技术神经辐射场隐式表达带来的几何结构精度较低,噪声较大问题。
2、为了解决上述技术问题,本发明采用的技术方案如下:
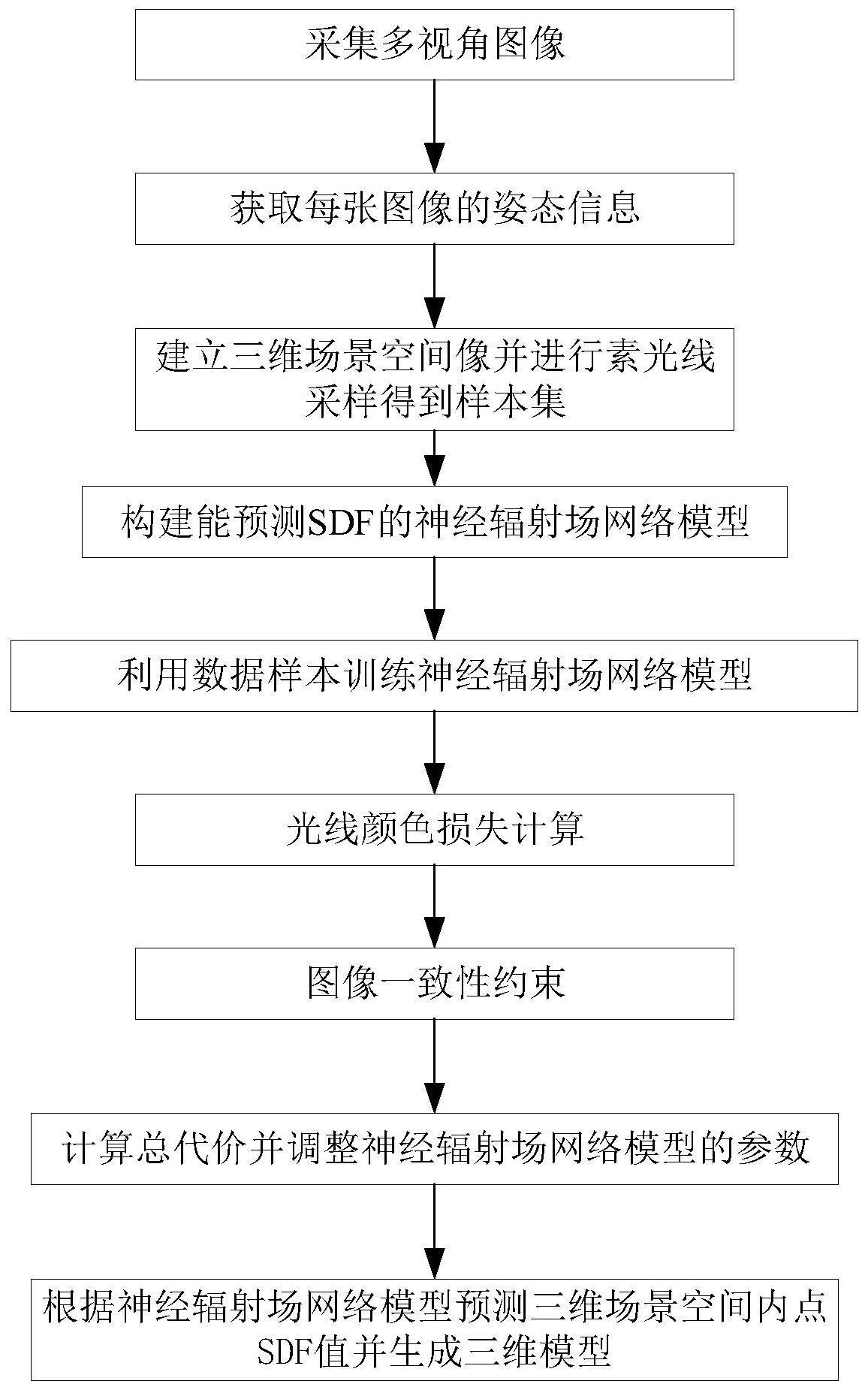
3、一方面,本发明提供一种基于神经辐射场的三维重建方法,包括以下步骤:
4、采集多视角图像;
5、获取每张图像的姿态信息;
6、建立将建模对象包裹在内的三维场景空间,利用体渲染在所有图像中随机建立m条像素光线,在每条像素光线上随机采样n个点,得到mⅹn个采样点位置集合{xi},并记录每个采样点视角vi,组成一个数据样本,多次建立m条像素光线并采样,得到样本集;
7、构建能预测sdf的神经辐射场网络模型;
8、将训练样本中每个采样点位置和采样点视角作为输入,对神经辐射场网络模型进行训练,输出采样点sdf值和采样点颜色;
9、光线颜色损失计算:根据预测采样点sdf值和采样点颜色计算像素光线的光线颜色,并计算光线颜色与多视角图像中像素光线真实颜色差,得到颜色损失lcolor;
10、图像一致性约束,在预测像素光线颜色的同时,获取或者计算每条像素光线上sdf值为0的点,即表面点,计算多视角图像的相似性,得到影像一致性代价lphoto;
11、根据颜色损失lcolor和影像一致性代价lphoto计算总代价,利用总代价调整神经辐射场网络模型的参数;
12、从样本集中选取新训练样本再次对调整参数后的神经辐射场网络模型进行训练,直至颜色损失lcolor和影像一致性代价lphoto收敛;
13、在三维场景空间进行均匀采样,根据收敛后的神经辐射场网络模型预测所有采样点的sdf值,利用所有采样点的sdf值生成网格模型。
14、进一步地,获取每张图像的姿态信息包括以下步骤:
15、利用运动恢复方法计算每个图像拍摄时相机的姿态信息,相机的姿态信息包括相机位置和相机朝向。
16、进一步地,所述神经辐射场网络模型包括sdf预测模块、颜色预测模块两个子模块,每个子模块均包括输入层、若干隐藏层和输出层;
17、sdf预测模块的输入层的输入参数为采样点位置,输出层的输出参数包括输出特征向量和sdf值;
18、颜色预测模的输入层有四个输入参数,分别是采样点视角、输入特征向量、法向量和采样点位置;
19、sdf预测模块的输出特征向量直接作为颜色预测模的输入特征向量,sdf预测模块输出的sdf值通过法向量计算模块计算得到法向量后作为颜色预测模的输入,颜色预测模的输出为采样点颜色。
20、进一步地,所述sdf预测模块的隐藏层有8层,颜色预测模的隐藏层有4层,所有隐藏层神经元数量相同,并且采用跳跃连接将输入层与中间的隐藏层向量。
21、进一步地,所述sdf预测模块的采样点位置和颜色预测模的采样点视角均采用位置编码进行维数扩展。
22、进一步地,光线颜色预测的具体方法如下:
23、遍历像素光线上的采样点,获取采样点的sdf值d(xi);
24、根据采样点的sdf值d(xi)计算不透明度;
25、根据采样点的不透明度计算透射率ti;
26、根据像素光线上所有采样点的透射率ti和采样点颜色ci计算光线颜色c(r);
27、遍历所有像素光线,并计算与原始图像中像素光线颜色差异,得到训练样本的颜色损失lcolor。
28、进一步地,计算多视角图像的相似性方法如下:
29、选取一个像素光线,计算表面点处的法向量,通过法向量得到表面点的切平面;
30、以像素光线上表面点为中心,在切平面上选取比较框作为源影像的影像块;
31、将在三维场景空间内选取多个参考影像,并且选择相同大小的比较框作为参考影像的影像块;
32、分别计算源影像和每个参考影像之间的ncc值;
33、选取若干ncc值最大的作为源影像的一致性代价lj;
34、计算所有像素光线上一致性代价lj的平均值,作为一致性代价lphoto。
35、进一步地,总代价计算方式如下:
36、l=lcolor+αlphoto+βlreg
37、l为总代价,α为影像一致性代价权重,lreg为在采样点上的eikonal项,β为eikonal项的权重。
38、另一方面,本发明提供一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述三维重建方法。
39、另一方面,本发明提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述三维重建方法。
40、与现有技术相比,本发明优势如下:
41、本方法在神经辐射场技术框架的基础上引入sdf,建立sdf与体密度的函数关系,将体渲染的优化目标从体密度转移至sdf,sdf在空间中具有均匀分布的特点,从而约束颜色权重集中分布在物体表面,避免了隐式表达带来精度不高、细节不细腻问题,另外,本发明在优化sdf的基础上提出使用多视图几何图像一致性约束,该约束利用多视图影像纹理的相似性,来进一步提升表面细节和精度。
- 还没有人留言评论。精彩留言会获得点赞!