一种基于大数据的语义信息检索方法与流程
本发明涉及大数据领域,尤其涉及一种基于大数据的语义信息检索方法。
背景技术:
1、大数据技术在语义信息检索领域的应用越来越广泛,可以帮助语义信息检索管理系统的管理者及时、高效地获取语义信息检索,实现语义信息检索管理的调整。目前,语义信息检索具有用户信息量庞大、数据种类多样、信息密度大等特点,语义信息检索方法存在较多的不确定因素,导致语义信息检索方法存在较大的不确定性。虽然已经发明了一些基于大数据的语义信息检索方法,但是仍不能有效解决语义信息检索方法的不确定问题。
技术实现思路
1、本发明的目的是要提供一种基于大数据的语义信息检索方法。
2、为达到上述目的,本发明是按照以下技术方案实施的:
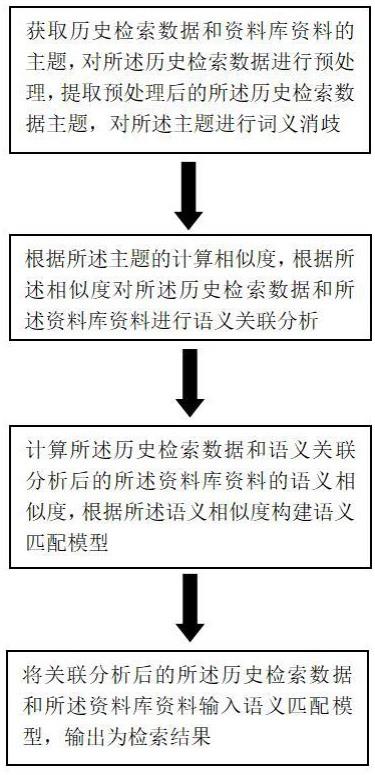
3、本发明包括以下步骤:
4、a获取历史检索数据和资料库资料的主题,对所述历史检索数据进行预处理,提取预处理后的所述历史检索数据主题,对所述主题进行词义消歧;
5、b根据所述主题的计算相似度,根据所述相似度对所述历史检索数据和所述资料库资料进行语义关联分析;
6、c计算所述历史检索数据和语义关联分析后的所述资料库资料的语义相似度,根据所述语义相似度构建语义匹配模型,所述语义匹配模型包括第一语义匹配算法和第二语义匹配算法,所述历史检索数据和语义关联分析后的所述资料库资料输入第一语义匹配算法获取初始匹配,将所述初始匹配输入第二语义匹配算法获得检索信息;
7、d将关联分析后的所述历史检索数据和所述资料库资料输入语义匹配模型,输出为检索结果。
8、进一步的,在步骤a中所述预处理的方法,包括对所述历史检索数据进行去重、去噪、分词、去停用词、词性筛选、去低频词和向量化。
9、进一步的,提取预处理后的所述历史检索数据主题的方法,包括:
10、去除预处理后的所述历史检索数据中的副词、组词和形容词,保留名词构成名词词典:
11、
12、其中名词词典为a,行表示一种所述历史检索数据对应的名词,词典的长度为m,词的个数为n;将词汇与词典进行匹配,构造高维的稀疏矩阵;将稀疏矩阵分解为基矩阵和系数矩阵的乘积:
13、
14、其中稀疏矩阵为b,基矩阵为c,系数矩阵为d,列数为r;基矩阵是主题的集合,系数矩阵是匹配的主题词集合,多次迭代,对高维矩阵进行降维,当满足如下条件时停止迭代:
15、
16、
17、其中迭代次数为t,任意小实数为;形成稳定的基矩阵、系数矩阵,输出主题词作为提取结果。
18、进一步的,对所述主题进行词义消歧的方法,包括:
19、对词典中每个义类中的所有词,收集包含词的上下文的主题作为训练集;对主题进行统计,找出能够有效标示每个义类的主题词,并计算主题词的权重:
20、
21、其中主题词i的权重为,主题词i出现在训练集中的概率为,主题词i出现在义类t中的概率为;
22、使用词向量模型获取词义相似度,根据主题词的权重对词义相似度的进行加权计算,将加权值最高的词义作为消歧结果。
23、进一步的,根据所述主题的计算相似度的方法,包括:
24、
25、其中检索数据的第i个主题为,资料库资料的第j个主题为,主题与主题的相似度为。
26、进一步的,根据所述相似度对所述历史检索数据和所述资料库资料进行语义关联分析的方法,包括:
27、将资料库资料的资料作为节点,历史检索数据和资料库资料属性的关联度视为边,构造特征图表示,隐藏属性激活映射单元捕捉隐藏属性响应矩阵,将隐藏属性响应向量根据余弦相似度法修正主题的相似度,将隐藏属性响应向量和修正的相似度输入语义关联模型,获取主题之间的语义关联程度,将语义关联程度大于0.5的历史检索数据和资料库资料输出为语义关联,计算所述隐藏属性响应向量:
28、
29、其中样本第q帧的特征图表示为,样本第q帧的隐藏属性激活图为,帧数为n。
30、进一步的,计算所述语义相似度的公式为:
31、
32、其中关联分析后的第i个资料库资料的语言表征向量为,语言表征的系数为a,主题表征的系数为b,第i个历史检索数据的语言表征向量为,关联分析后的第i个资料库资料的主题表征向量为,第i个历史检索数据的主题表征向量为,资料库资料的个数为n。
33、进一步的,所述语义匹配模型基于深度神经网络构建,将所述历史检索数据按照4:1随机划分成训练集和测试集,将训练集和语义关联分析后的资料库资料输入语义匹配模型进行训练,不断迭代直到遍历完所有的语义关联分析后的资料库资料,输出语义相似度最小的数据库资料作为检索信息输出,将测试集和语义关联分析后的资料库资料输入语义匹配模型进行测试。
34、进一步的,所述第一语义匹配算法获取初始匹配的方法,包括:
35、从词粒度对所述历史检索数据和所述资料库资料的句子进行编码,捕捉词语在历史检索数据和资料库资料中隐藏的语义信息;描述了全局-局部交叉融合层,进行句间词语交互,从全局和局部的交叉特征中,提取不同语义空间内词语的依赖关系;使用池化提取句子的全局信息和关键信息,预测历史检索数据和资料库资料主题的初始匹配分数:
36、
37、其中检索数据的第a段句子为,资料库资料的第a段句子为,数据进行词向量表征的函数为,计算两个数据匹配分数值的匹配方法为;
38、并对初始匹配分数从大到小排序,将初始匹配分数对应的资料库资料输出匹配。
39、进一步的,将所述初始匹配输入第二语义匹配算法获得检索信息的方法,包括:
40、将初始匹配对应的历史检索数据主题输入第二语义匹配算法向量化,根据词频关系将向量化的初始匹配加权得到主题向量:
41、
42、其中主题词的词向量为,主题数为t,主题词的权重为,权重为主题词的频次与该主题下所有主题词的总频次比;通过余弦相似度计算初始匹配的相似程度:
43、
44、其中初始匹配的资料库资料主题向量化后为,若资料库资料对于任意主题的相似程度大于等于阈值,则此资料库资料与主题匹配,反之则不匹配,输出匹配的资料库资料为检索信息。
45、本发明的有益效果是:
46、本发明是一种基于大数据的语义信息检索方法,与现有技术相比,本发明具有以下技术效果:
47、本发明通过预处理、提取主题、词义消歧、计算相似度、关联分析和检索匹配步骤,可以提高语义信息检索的准确性,从而提高语义信息检索的精度,将语义信息检索量化,可以大大节省资源和人力成本,提高工作效率,可以实现基于大数据的语义信息检索,实时对基于大数据的语义信息检索进行语义信息检索改进,对基于大数据的语义信息检索具有重要意义,可以适应不同基于大数据的语义信息检索管理系统、不同用户的基于大数据的语义信息检索系统的语义信息检索需求,具有一定的普适性。
- 还没有人留言评论。精彩留言会获得点赞!