一种基于无监督叠加集成的供水管网爆管检测与识别方法与流程
本发明属于城市供水管网爆管检测领域,尤其涉及一种基于无监督叠加集成的供水管网爆管检测与识别方法。
背景技术:
1、爆管是供水系统的一种主要失水形式,尽管持续时间短但失水量大。爆管不仅会造成大量水资源浪费,也会导致管网压力下降影响正常供水。此外,管道破裂后也容易发生污染物入侵从而影响饮用水水质。爆管检测方法能够帮助供水公司及时发现爆管,从而对爆管进行修复减少爆管的危害。
2、研究人员提出了各种爆管检测方法,由于数据采集和监控(scada)系统的大量使用,基于数据驱动的方法得到了广泛使用。根据检测原理可以分为基于分类的方法、基于预测的方法和基于统计的方法。基于分类的方法利用历史爆管数据对模型进行训练,然后对爆管进行检测,但是这种方法需要大量的历史爆管数据。基于预测的方法则是利用正常的监测数据对模型进行训练,然后利用模型预测值来检测实时监测数据是否出现异常。基于统计的方法则是将历史监测数据与实时监测数据进行比较,如果实时监测数据超过阈值则进行报警。考虑到基于预测的方法受预测精度的影响,可能会出现虚假报警的情况。而基于统计的方法只利用现有数据特征对爆管进行检测,省略了预测过程从而显著提高了爆管检测精度。各种基于统计的方法得到了广泛应用,例如利用供水管网中多个传感器流量监测数据之间的相似性(或不相似性)对爆管进行检测。该方法将不同传感器的流量监测数据转换为向量,利用爆管诱导的向量与其他正常向量的较低的相似度来识别爆管。此外,基于相似性的方法消除了非平稳情况(例如天气、节日和季节变化)对检测性能的影响。与流量传感器昂贵的价格相比,压力传感器在供水管网中得到了广泛应用。当管网发生爆管时通常会引起管网各个节点压力的突然下降,因此大多数研究基于压力监测值中的异常值对爆管进行监测。一旦发现压力传感器的监测值与同时期历史数据相比显著下降时,则发出爆管预警。例如使用干扰提取和独立森林集成技术,从现有的压力监测数据中提取出爆管特征。
3、这些方法都将爆管检测看作异常检测,尽管取得了良好的检测性能,但是并没有考虑异常监测数据的影响。上述方法在监测数据质量较差时其爆管检测的准确性可能会受到怀疑。此外,这些方法不能区分坏数据和爆管事件数据,也不能识别各种类型的scada故障。在实际中除了爆管会导致异常值出现外,scada系统本身的故障也会导致异常值的出现。scada系统从多个传感器收集数据,然后传输到控制中心或应用程序。通常,传感器会采集得到正确的数据,但是当传感器发生故障或者出现通信故障时,则会导致监测数据出现错误。此外,网络攻击也可能导致监测数据出现异常。显然,如果爆管检测方法没有考虑异常值的影响,一旦scada系统监测数据出现异常则会对爆管检测结果造成误导,出现大量虚假报警的情况。长此以往,则会使供水公司对爆管检测系统的准确性产生怀疑,从而限制了该方法在实际中的应用。一方面,当监测数据出现异常时会对爆管检测精度造成影响。另一方面,如果不能对异常的监测数据进行识别与清洗,这些数据导入数据库后会对后续的爆管检测造成影响。考虑到天气和季节变化对用水需求的影响,历史监测值需要不定期更新,将最新的监测数据添加到历史数据库中来替换比较老的历史监测数据。在添加最新监测数据时需要对其中的异常值进行清洗,确保历史监测数据能够准确反映管网的正常运行工况。考虑到对供水管网的监测是一个一直持续的过程,对历史数据库的更新以及对最新监测数据的清洗也应是在线过程。同时,应使数据更新和清洗过程效率较高。
技术实现思路
1、针对上述问题,本发明的目的在于提出一种基于无监督叠加集成的供水管网爆管检测与识别方法,该方法在对爆管进行检测时考虑了异常监测数据的影响,当实时监测数据出现异常值时根据异常识别模块的报警情况对爆管和监测系统故障进行区分,确定异常值的类型和持续时间,同时对异常监测数据进行清洗。
2、为了实现上述的技术特征,本发明的目的是这样实现的:一种基于无监督叠加集成的供水管网爆管检测与识别方法,其特征在于,包括如下步骤:
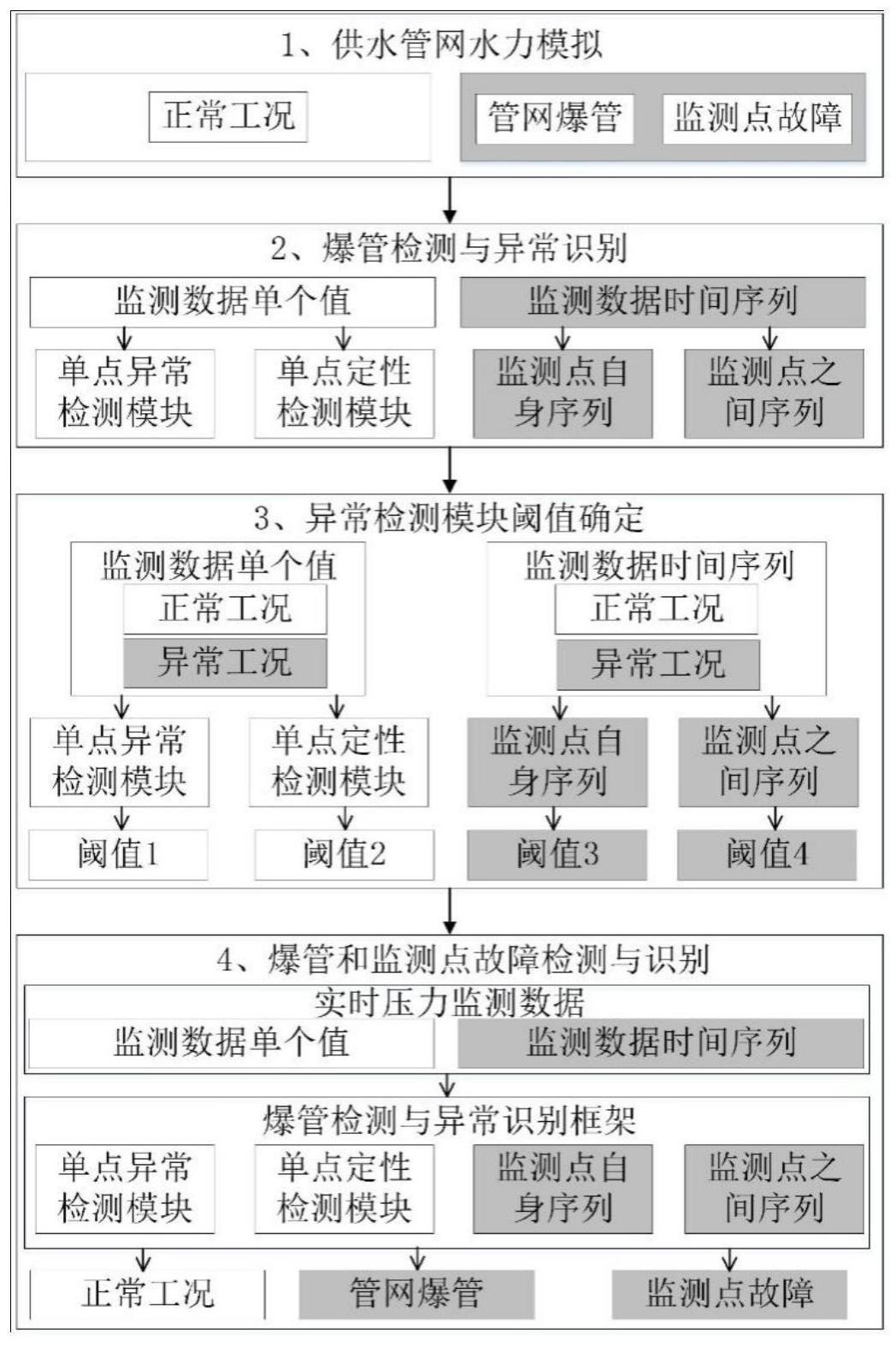
3、步骤(1):利用epanet对管网模型进行水力模拟,得到供水管网正常工况和异常工况下各个压力监测点的压力监测数据;
4、步骤(2):构建供水管网爆管检测与异常识别框架,该框架包含4个异常检测模块:(a)单点异常检测模块;(b)单点定性检测模块;(c)监测点自身序列模块;(d)监测点之间序列模块;
5、步骤(3):准备训练数据,对各个异常检测模块进行训练,确定各个模块的阈值;
6、步骤(4):利用异常检测框架对各种异常情景进行检测,得到管网爆管和监测点发生故障的情况。
7、优选的,步骤(1)具体包括如下步骤:
8、步骤(1.1),利用epanet对管网进行水力模拟,得到管网正常工况下各个压力监测点的压力监测数据,如下式所示:
9、
10、式中,表示管网正常工况下压力监测点k1在第0天t时刻的压力监测数据,
11、表示管网正常工况下压力监测点kn在第nd天t时刻的压力监测数据;
12、步骤(1.2),利用epanet对管网各个管道发生爆管的情况进行水力模拟,得到管网发生爆管时各个压力监测点的压力监测数据,如下式所示:
13、
14、式中,表示管网管道pipe1发生爆管后压力监测点k1在t时刻的压力监测数据;表示管网管道pipep发生爆管后压力监测点kn在t时刻的压力监测数据;
15、步骤(1.3),考虑监测点发生故障的情况,向供水管网正常工况下的压力监测数据中添加部分错误数据,得到监测点发生故障情况下的压力监测数据,考虑了以下几种情况:(a)异常监测值;(b)数据延迟;(c)监测点编号错误。
16、优选的,步骤(2)具体包括如下步骤:
17、步骤(2.1),构建四个异常检测模块,对各个压力监测点压力监测数据中的单点异常和时间序列异常进行检测,检测到供水管网实时监测数据中的异常值,实现异常检测;
18、步骤(2.2),如果检测到供水管网的实时监测数据存在异常值,则根据四个异常检测模块的报警情况对各种供水管网各种异常情景进行区分,对供水管网发生爆管和监测系统出现故障的情况进行准确区分。
19、优选的,所述步骤(2.1)具体包括:
20、步骤(2.1.1),单点异常检测模块研发:
21、单点异常检测模块主要是对单个异常监测数据进行检测,为了提高单点异常检测的精度,对多种机器学习算法进行了集成,单点异常检测模块分为三层:(a)第一层为独立森林算法;(b)第二层为k-均值聚类和局部异常值概率算法;(c)第三层为k-均值聚类和局部异常值概率算法输出结果的集成;
22、对于监测点ki,单点异常识别模块的输入数据为:
23、
24、式中:为监测点ki在第nd天t时刻的监测值;
25、首先,将p(ki)输入到独立森林算法中,得到各个pt(ki)的异常得分:
26、
27、
28、式中,表示p(ki)中第i个观测值pit(ki)的异常得分,i=0,1,…,nd,c(nd+1)=为二进制搜索树中搜索不成功的平均路径长度,tr为树的总数,是观测值的路径长度,是的平均值;
29、在得到各个监测点的各个实时监测数据的异常得分后,将各个实时监测数据的异常得分作为输入,进入单点异常检测模块的第二层,分别在k-均值聚类和局部异常值概率算法中得到各个异常得分的异常检测结果;
30、在k-均值聚类中,对st(ki)中的各个异常得分进行聚类,得到二进制数据,如果正常则为0,如果异常则为1;在k-均值聚类中,初始聚类列表为每个被分到与其平方欧式距离最近的聚类中:
31、
32、式中:为第i个聚类;sp为各个异常得分的数据集;为第i个监测点在t数时刻的监测值;为第j个监测点在t数时刻的监测值;k为监测点总的数量;j为监测点的编号;t为各个监测点采集数据的时刻;
33、然后,采用下式对每个聚类进行更新:
34、
35、式中:sj为该聚类内的各个异常得分分数;为t时刻的第i个聚类;为第i个聚类在t+1时刻的聚类中心;xj为聚类ci内第j个异常得分的值;
36、从形式上讲,目标是得到下式所示的关系:
37、
38、式中,ρ为各个聚类的中心,varci为聚类ci内各个异常得分的方差,s为聚类ci内各个监测数据的异常得分,ci为第i个聚类,ξi是ci中各点的平均值,即最小化相同聚类中各个监测值的成对平方偏差:
39、
40、设c为k-均值聚类算法的输出,c为一组大小为nd+1的聚类标签,ci=1或x和y均为聚类内的监测值,k为监测值点总的数量;
41、在局部异常值概率算法中,得到各个监测值异常得分的概率,各个的概率由从到参考点r的标准距离得到:
42、
43、式中,表示和r之间的距离度量,采用欧几里得距离;
44、点si到参考点r的概率集距离具有“显著性”λ,定义为:
45、
46、然后,使用最近邻作为参考集,最近邻是由独立森林算法得到的观测值之间最近的欧式距离,对于给定的领域大小k和显著性λ,监测值的概率局部异常因子plof定义为:
47、
48、最后,计算得到成为局部异常值的概率:
49、
50、设l为局部异常值概率算法的输出,为一组长度为nd+1的概率;li表示第i个成为异常值的概率,0≤li≤1;
51、在得到各个异常得分的聚类结果和成为异常值的概率后,进入单点异常检测模块的第三层,根据k-均值聚类和局部异常值概率算法的输出结果,最终得到各个实时监测数据st(ki)成为异常值的概率,第i个观测值st(ki)成为异常值的概率为:
52、pi=ci·li;
53、在k-均值聚类中,聚类的个数k=2,k-均值聚类将所有监测值分为正常和异常两组,由于它最小化了平方和,从而避免给不同于正常数据的监测值增加更多的权重,将正常数据分到同一个聚类中,然而,在第二个分组中,可能将正常数据或者小的变化看作是离群值,正常数据标记为0,异常数据标记为1,因此,ci=0表示正常数据,ci=1表示异常值,另外,接近0的li表示正常数据,通过将k-均值聚类结果与局部异常值概率算法结果相乘,避免了将正态数据分配给异常值,并且掩盖了k-均值聚类检测到的正常数据,通过不同方法集成提高了精度。
54、优选的,所述步骤(2.1)中还包括:
55、步骤(2.1.2),单点定性检测模块研发:
56、单点定性模块主要是对各个时刻的监测值进行判断,对于单个监测点k,首先根据历史监测值i=1,2,…,nd,得到定性阈值[ξ-(k),ξ+(k)]:
57、
58、
59、将与ξ-(k)和ξ+(k)进行比较,共分为三种情况:若则输出-1;若则输出0;若则输出1。
60、6、根据权利要求4所述一种基于无监督叠加集成的供水管网爆管检测与识别方法,其特征在于,所述步骤(2.1)中还包括:
61、步骤(2.1.3),监测点自身序列模块研发:
62、监测点自身序列模块用于检测监测点不同天监测数据的时间序列相异性,在供水管网正常工况下,单个监测点不同天同一时间段之间的时间序列曲线彼此相似,当供水管网工况发生变化或者监测数据出现异常时,监测点监测数据自身时间序列的相异性会发生变化;
63、对于单个监测点ki,计算得到第i天和第j天t时刻监测数据时间序列与之间的序列距离
64、
65、式中,mi,j(ki)为与的点积,和σi(ki)分别为监测点ki第i天t时刻时间序列的平均值和标准偏差;
66、监测点ki当前时刻与前nd天对应时刻的时间序列距离表示为并得到最小值
67、
68、根据前nd天t时刻监测数据时间序列距离计算得到决策阈值ξ2(ki):
69、
70、式中,和分别为时间序列距离(i≠j,i,j=1,2,…,nd)的平均值和方差;
71、在得到决策阈值ξ2(ki)后,将其与最小阈值进行比较,如果则表示监测点ki当前时刻的监测数据时间序列无异常,输出检测结果0,否则,输出检测结果1。
72、优选的,所述步骤(2.1)中还包括:
73、步骤(2.1.4),监测点之间序列模块研发:
74、监测点之间序列模块主要用于检测不同监测点监测数据时间序列相异性是否发生变化,在供水管网正常工况下,监测点之间不同天监测数据时间序列的相异性相似,当供水管网工况发生变化或者监测数据出现异常时,监测点之间的监测数据时间序列的相异性会发生变化;
75、不同监测点之间的时间序列相异性表示监测点与监测点之间同一天同一时刻的时间序列之间的距离,对于两个监测点k1和k2的时间序列和其相异性用di(k1,k2)表示:
76、
77、式中,mi(k1,k2)为和的点积,μi(k1)和σi(k1)分别为的平均值和标准偏差,σi(k1)和σi(k2)分别为和的标准偏差;
78、计算得到监测点与监测点当前时刻与前nd天对应时刻的时间序列距离dt(k1,k2):
79、
80、式中,表示当前t时刻监测点k1和k2时间序列之间的距离,表示前nd天t时刻监测点k1和k2时间序列之间的距离;
81、根据前nd天t时刻的时间序列距离计算得到决策阈值ξ1,ξ1由的平均值和方差得到:
82、
83、式中,μ(dt(k1,k2))和σ(dt(k1,k2))分别表示时间序列距离(i=1,2,…,nd)的平均值和方差;
84、在得到决策阈值ξ1(k1,k2)后,将其与时间序列距离进行比较,若则表示监测点k1和k2当前时刻的监测数据无异常,输出检测结果0,否则,输出检测结果1。
85、优选的,所述步骤(2.2)具体如下:
86、步骤(2.2.1),异常事件区分主要是区分爆管scada系统发生故障的情况,通过各个监测点的定性阈值和各个监测点自身序列报警情况进行区分;管网发生爆管后,由于管网内流量需求增大造成管网节点压力下降;因此,各个监测点各个时刻的定性阈值均为-1或0,即一旦出现定性阈值为1的情况则为监测点发生故障的情况;根据各个异常检测模块的异常检测结果,对各种异常进行分类;
87、步骤(2.2.2),根据定性阈值判断异常报警与假报警的情况,如果所有监测点各个时刻的定性阈值均为0,则异常检测结果为假报警,scada系统监测数据无异常,不报警,反之则说明scada系统监测数据存在异常,需要对异常情况进行区分;
88、步骤(2.2.3),尽管爆管发生后会造成节点压力下降,使各个监测点监测数据值显著低于正常值,在管网发生爆管后,监测数据值的大小尽管会下降但时间序列形状通常不会发生变化,即监测点自身序列不会出现连续报警的情况,因此,如果出现监测点自身序列连续报警的情况,则认为是scada系统发生故障的情况,同时,自身序列出现报警的监测点则为发生故障的监测点。
89、优选的,所述步骤(3)具体包括:
90、步骤(3.1),准备供水管网正常工况下各个压力监测点单点历史监测数据,如下式所示:
91、
92、式中,表示监测点k1在t时刻的压力监测数据,ki(i=1,2,…n)表示管网中布设的第i个监测点,在对各个时刻监测值进行检测时,主要是将与进行比较,确认是否为异常值,即将式中每一列的值进行比较;
93、步骤(3.2),得到各个监测点的时间序列数据及其与之对应的历史时间序列数据,如下式所示:
94、
95、式中,表示监测点k1在t时刻的时间序列数据:
96、st(j)={pt-l+1(j),pt-l+2(k),…,pt(j)};
97、式中,pt-l+1(k)表示监测点k在t-l+1时刻的数据,l为时间序列的长度;
98、步骤(3.3),利用正常工况和异常工况下各种监测数据对四个异常检测模块进行训练和测试,得到各个异常检测模块的阈值。
99、优选的,所述步骤(4)具体包括:
100、步骤(4.1),将管网各种异常工况下的实时监测数据输入到爆管检测与异常识别框架中,得到各个模块的报警情况;
101、步骤(4.2),根据爆管检测与异常识别结果,对所提出方法的性能进行评估,考虑了以下三种性能评估指标:1)检测正确率(σ1);2)异常识别率(σ2);3)异常检测率(σ3);
102、
103、
104、
105、式中,ndn、nn和nin分别表示检测到的异常事件、总的异常事件和正确识别的异常事件数量;tdn和tt分别表示异常事件检测到的持续时间和实际持续时间,显然,σ1、σ2和σ3越高越好。
106、本发明有如下有益效果:
107、本发明提出了一种实现爆管检测与监测系统故障异常值识别方法。该方法在对爆管进行检测时考虑了异常监测数据的影响,当实时监测数据出现异常值时根据异常识别模块的报警情况对爆管和监测系统故障进行区分,确定异常值的类型和持续时间,同时对异常监测数据进行清洗。基于示例管网模型net3进行了案例研究,结果表明,所提出的方法能够准确识别爆管并区分各种传感器数据发生异常的情况。
- 还没有人留言评论。精彩留言会获得点赞!