一种结合了软件制品共识词对抽取与信息检索技术的自动化需求到代码追踪线索生成方法与流程
本发明涉及计算机软件,具体涉及一种结合了软件制品共识词对抽取与信息检索技术的自动化需求到代码追踪线索生成方法。
背景技术:
1、软件可追踪性是指一种将软件系统内各类软件制品(如需求、设计、代码与测试用例等)相互关联,并随系统变化对这些追踪线索进行维护的特性。长期的研究与实践表明,软件可追踪性能够极大地提升软件开发的正确性与效率,并为多种软件工程活动提供支持,例如安全保障、变更影响分析、缺陷定位和软件维护等。但软件可追踪性的实现却是困难的,因此一直是软件工程领域内研究和实践的热点。
2、目前,软件可追踪性研究主要关注需求和代码这两类最关键的软件制品之间的追踪关系。具体而言,代码是当前软件系统运行状态的唯一真实反映,而需求则代表人们对于软件系统的理解与期望,因此这两类软件制品之间的追踪线索对于软件开发的效率和质量至关重要。目前,基于信息检索的自动化软件可追踪技术是该研究领域内主流技术。该类技术通过计算不同软件制品之间的文本相似度,根据相似度从大到小建立候选追踪列表,进一步判定是否建立制品之间的追踪关系。但受软件制品文本质量的限制与不同类型的软件制品处于不同的抽象层次(存在语义鸿沟),导致该类方法精度有限,不能完全真实反应制品之间的追踪关系,难以支撑日常生产实践活动中的应用。
3、基于以上问题,本发明提出一种结合了软件制品共识词对抽取与信息检索技术的自动化需求到代码追踪线索生成方法,该方法通过利用自然语言处理工具和代码解析工具抽取需求与代码文本中包含特定语义的共识词对,并进一步结合需求与代码的结构信息利用共识词对对候选追踪列表的排序进行优化,显著提升了现有可追踪技术的精度。
技术实现思路
1、本发明的目的在于提供一种结合了软件制品共识词对抽取与信息检索技术的自动化需求到代码追踪线索生成方法,以提升现有工具在软工文本上的表现。
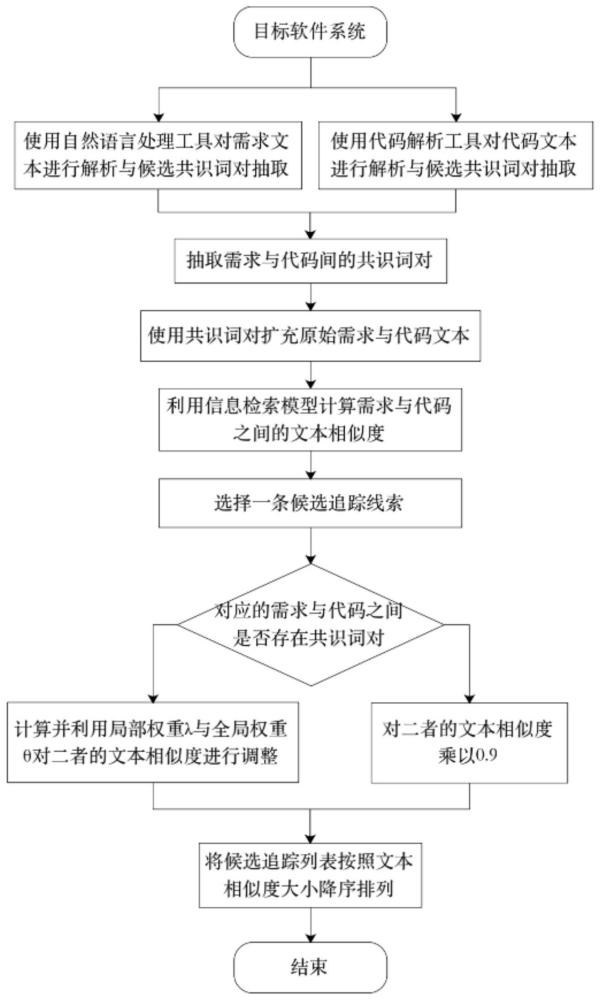
2、为了实现上述目的,本发明公开了一种结合了软件制品共识词对抽取与信息检索技术的自动化需求到代码追踪线索生成方法,具体步骤如下:
3、s100:对输入的需求文本进行预处理,将需求文本按照文本结构进行拆分后使用自然语言处理工具对输入的文本进行分句,分词,词性标注与词项依赖分析抽取候选词对,并根据组成词对的两个词项的词性对候选词对进行过滤;
4、s200:对输入的代码进行预处理,使用代码解析工具抽取代码中的注释和标识符名称,进一步从注释和标识符名称中抽取候选词对;
5、s300:基于步骤s100与s200中抽取的候选词对,识别需求与代码间的共识词对;
6、s400:将步骤s300中的共识词对分别扩充到需求与代码文本中;
7、s500:利用信息检索模型计算需求和代码之间的文本相似度,并按照文本相似度值自大到小排序得到候选追踪列表;
8、s600:结合步骤s300中的共识词对与需求文本结构信息计算共识词对在需求和代码中的全局和局部权重;
9、s700:结合步骤s600中的共识词对全局与局部权重对步骤s500中的候选追踪列表进行优化。
10、其中,所述s100包括以下步骤:
11、s101:根据需求文本的结构对其进行拆分,对usecase类型的需求按其结构拆分成标题、前置条件、主流程、子流程和可选流程五个部分,对issue类型的需求按其结构拆分成概要(summary)和描述(description)两个部分。
12、s102:使用自然语言处理工具对s101中已拆分的需求文本进行分句,再对每个句子进行分词并标注每个词项的词性(如“形容词”、“名词”、“动词”等),接着分析每个句子中的词项依赖关系。存在依赖关系的两个词项构成一个候选词对。
13、s103:根据词项词性对s102中的候选词对进行过滤,要求构成词对的两个词项的词性必须是“名词”、“动词”或“形容词”。
14、其中,所述s200包括以下步骤:
15、s201:使用代码解析工具抽取代码中的标识符和注释,其中标识符包括类名、方法名、常量类型、常量名称、形参类型、形参名称和调用方法名。
16、s202:对标识符进行分词,如方法名“getfakeemail”拆分成“get”、“fake”和“email”三个词项。对拆分后的词项进行两两组合构成候选词对,如“getfake”、“getemail”和“fakeemail”。
17、s203:对注释采用步骤s102和s103中的方式抽取候选词对。
18、其中,所述s300包括以下步骤:
19、s301:对需求和代码中抽取的两个候选词对集合求交集,二者共同拥有的词对即共识词对。
20、其中,所述s400包括以下步骤:
21、s401:使用共识词对扩充需求文本,统计每个共识词对在该需求中出现的次数,并按照出现次数将每个共识词对补充到原需求文本中。
22、s402:使用共识词对扩充代码文本,统计每个共识词对在该代码中出现的次数。对于出现在类名和方法名中的共识词对出现次数乘以二。然后按照出现次数将每个共识词对补充到原代码文本中。
23、其中,所述s500包括以下步骤:
24、s501:对需求文本进行文本预处理,包括移除停用词、词形还原和词干提取;对于代码文本,首先根据标识符命名规则进行分词,然后采用与需求文本相同的预处理方式进行预处理。
25、s502:基于信息检索模型,计算需求文本与代码文本之间的文本相似度;将需求文本和代码文本用向量r、c表示,向量中每个维度w对应一个词项在该文本中的权重,对于r、c两个向量采用余弦距离计算向量间的余弦相似度。
26、s503:根据文本相似度大小由高到低排列,得到候选追踪列表。
27、其中所述s600包括以下步骤:
28、s601:对于需求req和代码cls,计算二者共同拥有的共识词对的全局权重λ,其计算公式如下:
29、
30、其中,btcons表示需求req和代码cls共识词对的交集,分别计算二者共同拥有的共识词对分别占各自拥有共识词对的比重,两个比重相加后乘以二分之一作为btcons的全局权重λ。
31、s602:对于需求req和代码cls,计算二者共同拥有的共识词对的局部权重θ,其计算公式如下:
32、
33、其中,ω(req_part,cls)用于计算需求req每个部分出现的与cls共有的共识词对占该部分所有共识词对的逆向文本频率(idf)之和的比重,计算公式如下:
34、
35、对于usecase类型的需求文本,根据共识词出现在其文本的不同结构部分拥有不同权重:标题(title)部分的权重为0.4,主流程(main-flow,mf)部分的权重为0.3,子流程(sub-flow,sf)部分的权重为0.2,可选流程(alternative-flow,af)部分的权重为0.1。对于issue类型的需求文本,根据共识词出现在其文本的不同结构部分拥有不同权重:概要(summary)部分的权重为0.6,描述(description)部分的权重为0.4。
36、其中,所述s700包括以下步骤:
37、s701:基于步骤s600计算的全局权重λ和局部权重θ对初始的文本相似度值进行调,计算公式如下:
38、
39、若需求和代码文本之间没有共有的共识词对,则对二者的文本相似度值乘以0.9作为惩罚。将调整后的候选追踪列表按照文本相似度值由高到低重新排序,生成最终的候选追踪列表。
40、上述过程可以有效的提高软件可追踪技术的精度。与现有技术相比,本发明所达到的有益效果是:本方法分别对自然语言描述的软工文本和编程语言描述的代码提出了共识词对的抽取方法,并进一步利用共识词对提出了对初始文本相似度的调整策略,并且能够与现有的软件可追踪技术相结合,有效的提升现有技术的精度和召回率。
- 还没有人留言评论。精彩留言会获得点赞!