批改方法、装置、设备及可读存储介质与流程
本技术涉及人工智能,更具体的说,是涉及一种批改方法、装置、设备及可读存储介质。
背景技术:
1、近年来,随着人工智能技术的快速发展,使用机器来代替人工已经成为各行各业的热点方向。教育领域也由传统的教师与学生一对一、一对多的教导,逐步演变为教师、机器与学生三方互动的场景。然而,在处理大规模批改工作时,老师容易受到疲劳、个人偏好等主观因素的干扰,从而影响批改,尤其是批改的准确性和客观性。因此利用机器完成或辅助完成批改,以减少人工批改的工作量,提升批改,尤其是评分的准确性和客观性,对教学过程意义重大。
2、目前,利用机器完成或辅助完成批改的方式是利用神经网络模型对作业进行智能化批改,此种批改方式一般是先对题干文本进行拍照,然后从预设题库中搜索与题干文本对应的正确答案,进一步对题干文本的作答区域的手写体部分进行拍照,再利用神经网络模型对比手写体部分和正确答案之间的相似性,以得到批改结果。但是该方式受限于题库资源的量级以及完善程度,如果题库资源量级过大,往往导致批改的效率较低,如果题库资源不足,往往导致批改的准确率较低。
3、因此,如何提供一种批改方法,以提升批改效率和准确率,成为本领域技术人员亟待解决的技术问题。
技术实现思路
1、鉴于上述问题,本技术提出了一种批改方法、装置、设备及可读存储介质。具体方案如下:
2、一种批改方法,所述方法包括:
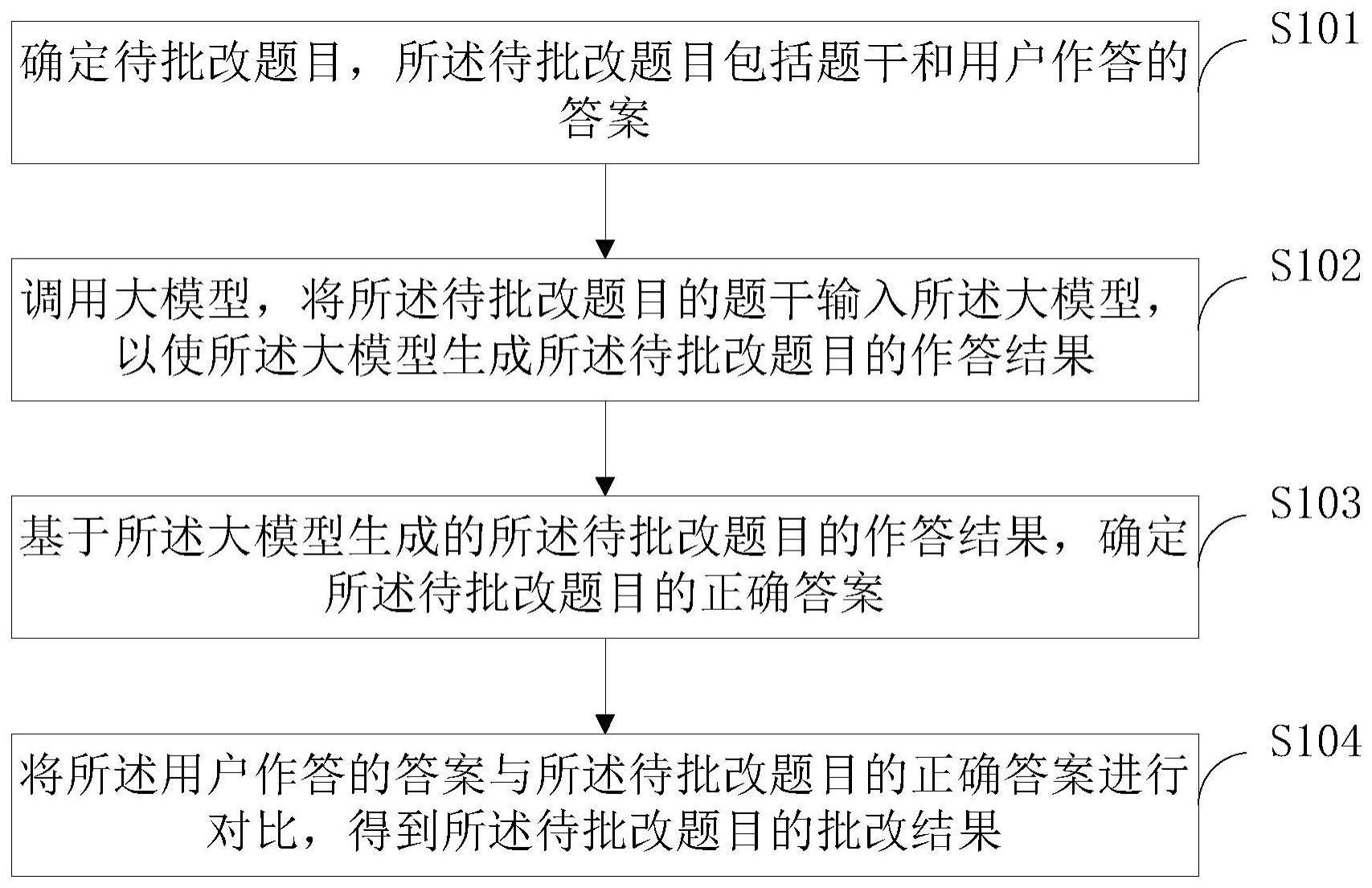
3、确定待批改题目,所述待批改题目包括题干和用户作答的答案;
4、调用大模型,将所述待批改题目的题干输入所述大模型,以使所述大模型生成所述待批改题目的作答结果;
5、基于所述大模型生成的所述待批改题目的作答结果,确定所述待批改题目的正确答案;
6、将所述用户作答的答案与所述待批改题目的正确答案进行对比,得到所述待批改题目的批改结果。
7、可选地,所述确定待批改题目,包括:
8、获取待批改页面的图片,所述待批改页面中包含多个题目;
9、对所述待批改页面的图片进行识别,确定每个题目的题干和用户作答的答案,所述待批改页面中的任一题目为所述待批改题目。
10、可选地,所述基于所述大模型生成的所述待批改题目的作答结果,确定所述待批改题目的正确答案,包括:
11、将所述待批改题目的题干以及所述大模型生成的所述待批改题目的作答结果输入答题模型,所述答题模型输出所述待批改题目的正确答案;
12、所述答题模型包括所述大模型以及小模型,所述答题模型是通过固定所述大模型的参数,以训练用题目的题干以及所述大模型生成的所述训练用题目的作答结果为训练样本,以标注的所述训练用题目的正确答案为训练标签,对所述小模型的参数进行调整训练得到的。
13、可选地,所述获取待批改页面的图片,包括:
14、获取原始页面的扫描图片作为所述待批改页面的图片;
15、或者,
16、获取原始页面的拍照图片;
17、对所述原始页面的拍照图片进行预处理,得到所述待批改页面的图片。
18、可选地,所述对所述原始页面的拍照图片进行预处理,得到所述待批改页面的图片,包括:
19、对所述原始页面的拍照图片进行页面提取,得到页面区域图片;
20、对所述页面区域图片进行增强处理,得到所述待批改页面的图片。
21、可选地,所述对所述原始页面的拍照图片进行页面提取,得到页面区域图片,包括:
22、对所述原始页面的拍照图片进行页面边界检测,得到有效页面区域图片;
23、对所述有效页面区域图片进行透视校正处理,得到页面区域图片。
24、可选地,所述对所述待批改页面的图片进行识别,确定每个题目的题干和用户作答的答案,包括:
25、将所述待批改页面的图片,转化为第一图片和第二图片,所述第一图片中包括所述待批改页面的图片中的印刷体文本行,所述第二图片中包括所述待批改页面的图片中的手写体文本行;
26、对所述第一图片以及所述第二图片进行文本行划分及识别处理,得到每个题目的题干和用户作答的答案。
27、可选地,所述对所述第一图片以及所述第二图片进行文本行划分及识别处理,得到每个题目的题干和用户作答的答案,包括:
28、对所述第一图片进行文本行划分处理,得到各个题目对应的印刷体文本行;
29、基于各个题目对应的印刷体文本行,对所述第二图片进行文本行划分处理,得到各个题目对应的手写体文本行;
30、针对每个题目,对所述题目对应的印刷体文本行进行识别,得到所述题目的题干,对所述题目对应的手写体文本行进行识别,得到所述题目的用户作答的答案。
31、可选地,在得到所述待批改页面中各个所述待批改题目的批改结果之后,所述方法还包括:
32、将所述待批改页面中各个待批改题目的批改结果在所述待批改页面的图片中进行展示。
33、一种批改装置,所述装置包括:
34、待批改题目确定单元,用于确定待批改题目,所述待批改题目包括题干和用户作答的答案;
35、大模型调用单元,用于调用大模型,将所述待批改题目的题干输入所述大模型,以使所述大模型生成所述待批改题目的作答结果;
36、正确答案确定单元,用于基于所述大模型生成的所述待批改题目的作答结果,确定所述待批改题目的正确答案;
37、答案对比单元,用于将所述用户作答的答案与所述待批改题目的正确答案进行对比,得到所述待批改题目的批改结果。
38、可选地,所述待批改题目确定单元,包括:
39、获取单元,用于获取待批改页面的图片,所述待批改页面中包含多个题目;
40、识别单元,用于对所述待批改页面的图片进行识别,确定每个题目的题干和用户作答的答案,所述待批改页面中的任一题目为所述待批改题目。
41、可选地,所述正确答案确定单元,包括:
42、将所述待批改题目的题干以及所述大模型生成的所述待批改题目的作答结果输入答题模型,所述答题模型输出所述待批改题目的正确答案;
43、所述答题模型包括所述大模型以及小模型,所述答题模型是通过固定所述大模型的参数,以训练用题目的题干以及所述大模型生成的所述训练用题目的作答结果为训练样本,以标注的所述训练用题目的正确答案为训练标签,对所述小模型的参数进行调整训练得到的。
44、可选地,所述获取单元,包括:
45、第一获取单元,用于获取原始页面的扫描图片作为所述待批改页面的图片;
46、或者,
47、第二获取单元,用于获取原始页面的拍照图片;
48、预处理单元,用于对所述原始页面的拍照图片进行预处理,得到所述待批改页面的图片。
49、可选地,所述预处理单元,包括:
50、页面提取单元,用于对所述原始页面的拍照图片进行页面提取,得到页面区域图片;
51、增强处理单元,用于对所述页面区域图片进行增强处理,得到所述待批改页面的图片。
52、可选地,所述页面提取单元,包括:
53、页面边界检测单元,用于对所述原始页面的拍照图片进行页面边界检测,得到有效页面区域图片;
54、透视校正处理单元,用于对所述有效页面区域图片进行透视校正处理,得到页面区域图片。
55、可选地,所述识别单元,包括:
56、转化单元,用于将所述待批改页面的图片,转化为第一图片和第二图片,所述第一图片中包括所述待批改页面的图片中的印刷体文本行,所述第二图片中包括所述待批改页面的图片中的手写体文本行;
57、文本行划分及识别处理单元,用于对所述第一图片以及所述第二图片进行文本行划分及识别处理,得到每个题目的题干和用户作答的答案。
58、可选地,所述文本行划分及识别处理单元,具体用于:
59、对所述第一图片进行文本行划分处理,得到各个题目对应的印刷体文本行;
60、基于各个题目对应的印刷体文本行,对所述第二图片进行文本行划分处理,得到各个题目对应的手写体文本行;
61、针对每个题目,对所述题目对应的印刷体文本行进行识别,得到所述题目的题干,对所述题目对应的手写体文本行进行识别,得到所述题目的用户作答的答案。
62、可选地,所述装置还包括:
63、批改结果展示处理单元,用于在得到所述待批改页面中各个所述待批改题目的批改结果之后,将所述待批改页面中各个待批改题目的批改结果在所述待批改页面的图片中进行展示。
64、一种批改设备,包括存储器和处理器;
65、所述存储器,用于存储程序;
66、所述处理器,用于执行所述程序,实现如上所述的批改方法的各个步骤。
67、一种可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现如上所述的批改方法的各个步骤。
68、借由上述技术方案,本技术公开了一种批改方法、装置、设备及可读存储介质。在确定待批改题目之后,先调用大模型,将待批改题目的题干输入大模型,以使大模型生成待批改题目的作答结果;再根据大模型生成的待批改题目的作答结果确定待批改题目的正确答案;通过将用户作答的答案与待批改题目的正确答案进行对比,即可得到待批改题目的批改结果。基于本方案,无需依赖题库资源,利用大模型强大的语言理解能力和文本生成能力即可实现高效、准确的批改。
- 还没有人留言评论。精彩留言会获得点赞!