一种相似性比较型数据的伪标签生成方法与流程
本发明涉及计算机视觉,具体为一种相似性比较型数据的伪标签生成方法。
背景技术:
1、伪标签(pseudo label)属于半监督学习中的概念,能够帮助模型更好的从无标注的数据中进行学习。具体的指使用标签数据训练模型,再使用训练好的模型为没有标签的数据预测标签,预测的标签即伪标签。生成的伪标签数据可以和有标签的数据共同训练模型,以提高模型的精度。
2、现有技术中,基于视觉的模式识别已广泛应用于生物特征识别中,例如人脸识别、虹膜识别、掌纹识别、动物个体识别等。相较于人脸,其余的生物特征由于较难直接辨认,有标签的生物特征图像相对匮乏,生物特征识别仍然没有得到充分的探索。例如动物个体识别中的宠物狗鼻纹识别,宠物狗在成年后鼻纹特征固定,这为宠物狗鼻纹识别技术提供了基础。狗鼻纹匹配旨在识别两个狗鼻纹图像是否属于同一只狗。
3、但是,宠物狗鼻纹识别数据集只能在构建数据集时,主动对宠物狗鼻纹图片进行分类。若是存在未标注的宠物狗鼻纹数据集,存在细节特征模糊,生物特征难以区分的特点,人工标注数据集可靠性相对较低。
技术实现思路
1、本发明的目的在于提供一种相似性比较型数据的伪标签生成方法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:一种相似性比较型数据的伪标签生成方法,所述伪标签生成方法包括以下步骤:
3、伪标签生成;
4、匈牙利匹配算法结果优化。
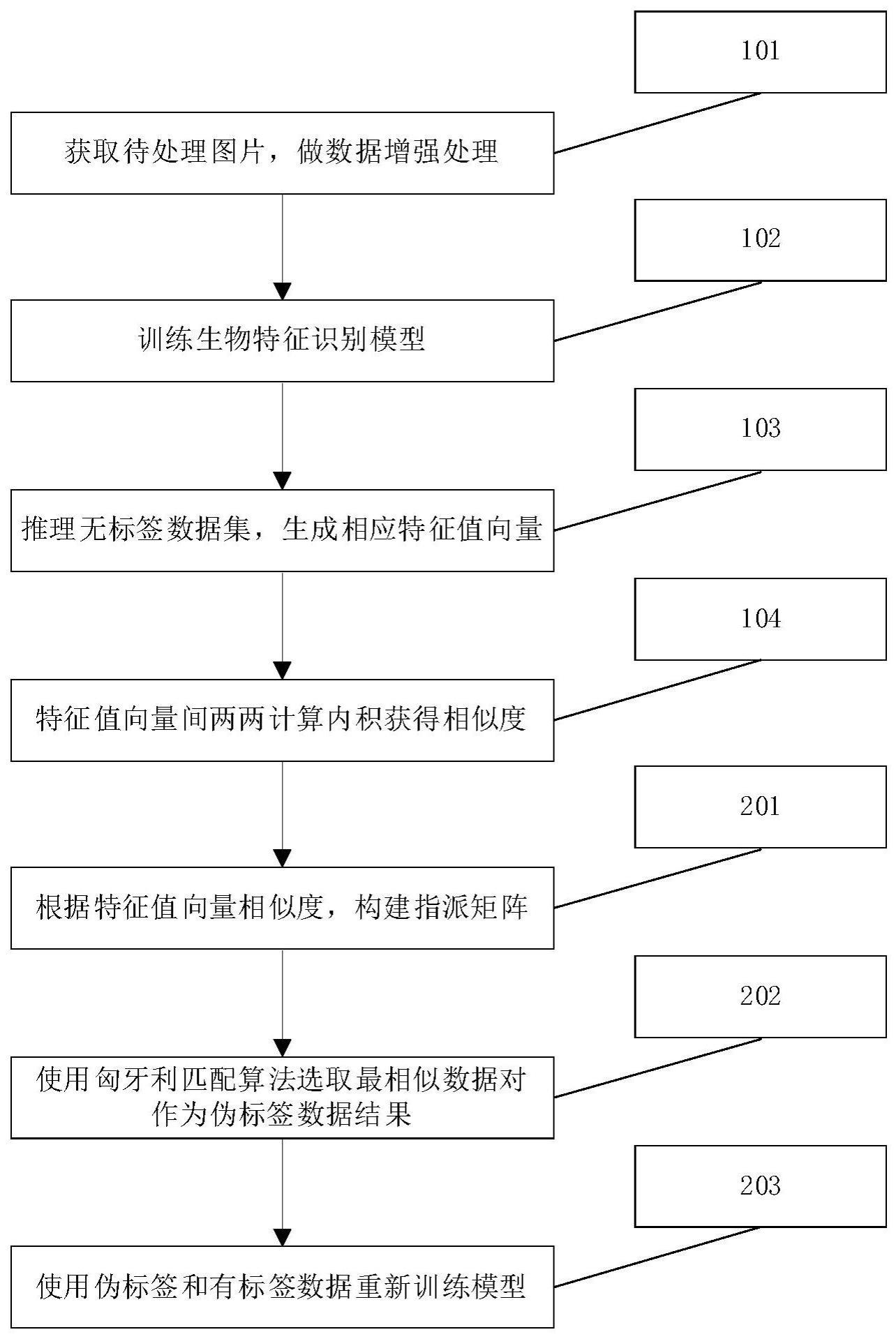
5、优选的,伪标签生成包括:
6、获取待处理的有标签数据集,对数据集图片进行图像模糊、翻转以及随机遮挡数据增强操作。
7、优选的,伪标签生成还包括:
8、根据获取到的数据增强图片,输入特征提取网络,使用余弦学习率衰减策略训练生物特征重识别模型。
9、优选的,伪标签生成还包括:
10、根据获取到的生物特征重识别模型,对无标签数据集推理,生成数据相对应的特征值向量。
11、优选的,伪标签生成还包括:
12、根据得到的特征值向量,对所有的特征值向量间两两计算内积获得相似度。
13、优选的,匈牙利匹配算法结果优化包括:
14、根据得到的无标签数据之间两两特征值向量相似度数据,构建指派矩阵
15、将矩阵初始化值为1,匈牙利匹配算法解决分配问题目的是使总开销最小化,为适配匈牙利匹配算法实现机制,在构建指派矩阵时,将无标签数据集中两张图片的特征向量相似值取负值,生成指派矩阵
16、其中,表示两张生物特征图片之间的相似度的值,值越小表示两张图片的相似度越高。的取值范围为[-1,1]。
17、优选的,匈牙利匹配算法结果优化还包括:
18、根据得到的指派矩阵使用匈牙利匹配算法得到最优分配结果。
19、优选的,匈牙利匹配算法结果优化还包括:
20、根据得到的最相似数据对作为伪标签数据结果,结合有标签数据重新训练优化生物特征识别模型,提升伪标签精度。
21、与现有技术相比,本发明的有益效果是:
22、本发明提出的相似性比较型数据的伪标签生成方法,通过已有标签数据训练生物特征识别模型,然后使用训练好的模型对无标签数据推理,生成数据相对应的特征值向量;再对所有的特征值向量间两两计算内积获得相似度;而后使用匈牙利匹配算法选取最相似数据对为伪标签数据结果;最后将优化后的伪标签数据与有标签数据一起混合重新训练得到生物特征识别模型;在有限的有标签数据的条件下,通过对无标签数据生成伪标签,进一步扩充数据集,提高模型的识别性能;与传统的伪标签生成方法相比,使用匈牙利匹配算法优化伪标签预测结果,进一步提高伪标签预测结果的准确性;在使用的匈牙利匹配算法时将图片之间的相似度取负值,可以更好地匹配匈牙利匹配算法机制,能够更好地匹配标签的分配结果。
技术特征:
1.一种相似性比较型数据的伪标签生成方法,其特征在于:所述伪标签生成方法包括以下步骤:
2.根据权利要求1所述的一种相似性比较型数据的伪标签生成方法,其特征在于:伪标签生成包括:
3.根据权利要求2所述的一种相似性比较型数据的伪标签生成方法,其特征在于:伪标签生成还包括:
4.根据权利要求3所述的一种相似性比较型数据的伪标签生成方法,其特征在于:伪标签生成还包括:
5.根据权利要求4所述的一种相似性比较型数据的伪标签生成方法,其特征在于:伪标签生成还包括:
6.根据权利要求5所述的一种相似性比较型数据的伪标签生成方法,其特征在于:匈牙利匹配算法结果优化包括:
7.根据权利要求6所述的一种相似性比较型数据的伪标签生成方法,其特征在于:匈牙利匹配算法结果优化还包括:
8.根据权利要求7所述的一种相似性比较型数据的伪标签生成方法,其特征在于:匈牙利匹配算法结果优化还包括:
技术总结
本发明涉及计算机视觉技术领域,具体为一种相似性比较型数据的伪标签生成方法,包括以下步骤:伪标签生成;匈牙利匹配算法结果优化;有益效果为:本发明提出的相似性比较型数据的伪标签生成方法,通过已有标签数据训练生物特征识别模型,然后使用训练好的模型对无标签数据推理,生成数据相对应的特征值向量;再对所有的特征值向量间两两计算内积获得相似度;而后使用匈牙利匹配算法选取最相似数据对为伪标签数据结果;最后将优化后的伪标签数据与有标签数据一起混合重新训练得到生物特征识别模型;在使用的匈牙利匹配算法时将图片之间的相似度取负值,可以更好地匹配匈牙利匹配算法机制,能够更好地匹配标签的分配结果。
技术研发人员:刘琛,李晗,马凤强,安晓博,尹萍
受保护的技术使用者:浪潮云信息技术股份公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!