自动驾驶车辆的非线性数据字典质量估计方法与流程
本发明涉及行驶车辆重量的自动计算领域,具体为自动驾驶车辆的非线性数据字典质量估计方法。
背景技术:
1、目前,大部分国家和地区,通常需要在规定的时间内进行测量商用车的重量,以确保其符合相关的法规和安全标准。这通常涉及到在政府的认可机构进行的年度或半年度审查或年检过程中测量其重量,有些国家和地区还要求商业运营车辆使用称重站或其他测量站进行定期检查,以确保卡车的重量在合法范围内并符合法规要求。其中会使用电子称或其他重量测量装置。然而,在某些情况下,例如当卡车载重量有变化时,例如卸货或重新装载货物后,需要重新进行重量检查,由于车辆吨位比较大,周边很难找到专业的汽车载重测量公司。这时实时质量估计模型的价值便很容易凸显出来。总之,在合规性和安全方面,定期检查车辆重量对于所有商业运营车辆非常重要,而测量卡车重量的电子称是一种常用的测量工具之一。
2、此外,豪华车辆一般都配备了车辆载重质量估计系统,在车辆的多功能显示仪表盘或车载扩展系统中,可以查看当前车辆的载重质量状况。该系统通常会通过车辆悬架传感器、自车测速传感器等多种传感器收集车辆载重质量的相关数据,并对这些数据进行处理,然后在仪表盘显示相关的载重质量信息。通过该系统的帮助,驾驶员可以更准确地了解车辆当前的载重情况,以便根据实际情况进行调整和计划。这对于行驶在颠簸、崎岖的道路上或需要运输不同重量负荷的货物时尤其有用,可以有效提升驾驶员的安全意识和行驶效率。但是,计算过程相对繁杂,需要的传感器比较多,在降本增效的策略上很难有成效,特别是对于普通的商用车要实现批量化生成,节约成本也是主机厂考虑的关键。
3、通过大量调研发现目前汽车质量估计的常用方法包括以下几种:
4、(1):重量测量法:这种方法通过仪器测量车辆的重量,在不同的载重状态下进行比较,来评估汽车的质量。该方法优点精准度高,缺陷是受地点和仪器限制比较大,灵活度低,要求车辆静止,最大吨位也有限额。
5、(2):vin码检查法:vin码是车辆识别号码的缩写,每一辆车都会有唯一对应的vin码。通过查看vin码,可以获取车辆的生产厂家、生产日期、车型等重要信息,从而准确地评估汽车的质量,该方法仅对空载车辆有效,但是无法适应汽车零部件更换和装卸货物的场景。
6、(3):机械检查法:这种方法通过对车辆的机械部件进行检查,如车架、引擎、悬挂系统、转向系统等,评估汽车的质量和可靠性。该方法精准度比较低,存在较大偏差。
7、(4):历史档案检查法:对于二手车而言,可以通过查看车辆二手市场的历史档案,了解车辆过去的维修记录等相关信息,评估汽车的质量。同样,只适用车辆空载,缺乏实时性。
8、(5):行驶测试法:通过对汽车的行驶性能进行测试,如加速、刹车、转弯、悬挂等,评估汽车的性能和质量。
9、本发明专利属于第5种方法行驶测试法,可动态实时计算出不同路况和装载程度的质量,能满足实时性要求,灵活且实用性强。以上方法都有其优缺点,有些方法需要通过专业设备进行测量和检查,有些方法则需要考虑到人为因素的影响。综合使用多种方法,可以更全面、准确地评估汽车的质量。
10、因此,尽可能在不加载高端传感器的前提下,找到一个理性的实时质量估计模型,成为了很多车辆量产企业亟需解决的问题。鉴于以上问题背景的描述,本专利需要解决的问题再次被赋予了经济效益和工程化落地的一个分支考验。正是由于成本有限的前提下,探索一个行之有效的商用车载重估计模型。
技术实现思路
1、本发明的目的在于提供自动驾驶车辆的非线性数据字典质量估计方法,以解决上述背景技术中提出的问题。
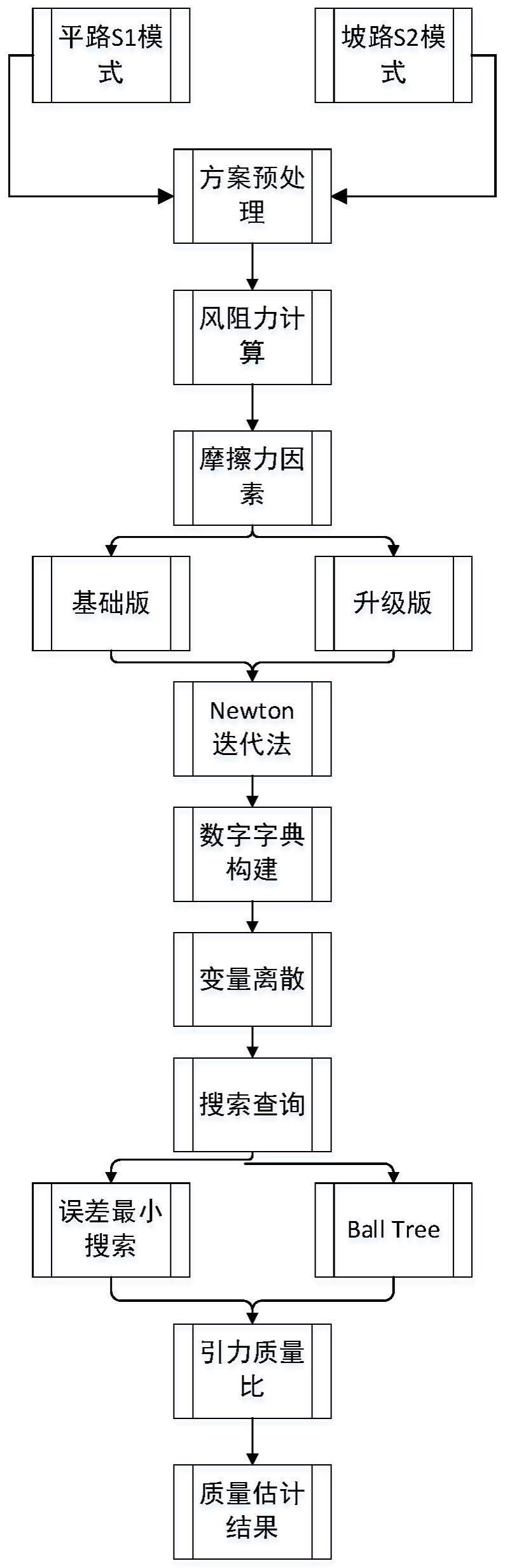
2、为实现上述目的,本发明提供如下技术方案:自动驾驶车辆的非线性数据字典质量估计方法,包括步骤:
3、s1:摩擦力系数计算,受天气和地理条件的影响,摩擦力因素是一个动态变化的值,通过建立动态的摩擦力计算模型计量;
4、s2:风阻力估算;
5、s3:建立坡道运动学方程,将原问题转化为非线性问题;
6、s4:使用非线性newton迭代来求解坡道上的运动学方程;
7、s5:构建高维数字字典,为非线性字典的质量估计查询做准备;
8、s6:邻近点搜索方法,根据输入变量来确定某时刻车辆的实际运动状况,并搜索出与之最接近的理论质量值;
9、s7:输出质量估计结果并计算质量估计的误差范围。
10、优选的,s1中摩擦力系数计算采用两种策略分别计算不同路段,其具体步骤包括:
11、s1a:摩擦力系数估计策略一,采用默认值结合人工输入法来实现不同路段摩擦力系数的近似等价应用;
12、s1b:平路摩擦力系数估计策略二,采用深度学习自动识别法,按照视频路面粗糙程度识别出对应的标签;
13、s1c:深度学习测试样本的路面类别标签与理论摩擦力系数相对应,即能获取路面类别标签,即获取相应的摩擦力系数。
14、优选的,s2中风阻力fair值的估算步骤如下:
15、s2a:计算商用车前截面的挡风面积,获取当前车辆行驶速度;
16、s2b:给出风阻力系数计算的分段函数,最终输出风阻力fair的估算值。
17、优选的,s4中具体步骤包括:
18、s4a:建立坡路的运动学方程,将运动学方程转变为含有未知参数m以及θ的非线性问题;
19、s4b:使用newton非线性迭代法求解非线性运动方程,设定迭代次数k,以及误差阈值ε;
20、s4c:通过多次迭代,输出近似解以及
21、优选的,s5中具体步骤包括:
22、s5a:将方程中的重要变量按已知范围进行空间离散,建立多维变量与牵引力质量比r的空间映射关系,即构建出高维非线性数字字典;
23、s5b:使用当前实际的牵引力f与牵引力质量比率r的比值可以估计出理论上此时刻商用车的质量。
24、优选的,s6中邻近点搜索的空间基于在s4构造的高维的数字字典中进行,其具体步骤包括:
25、s6a:使用邻近点搜索方法,在高维数字字典中查询与实际车辆行驶状态最接近的理论质量参考值,为质量估计输出做好准备;
26、s6b:使用邻近点搜索方法,包括最小距离误差搜索法以及ball tree搜索算法计算搜索。
27、优选的,s5a中具体步骤包括:
28、分别对(f,θ,v,a)的每个变量进行等距离散,得到高维离散坐标,为后续的字典查询做好准备;
29、使用非线性字典查询出车重量估计值并输出结果,这依赖于输入参数(f,θ,v,a),其中θ可由newton迭代获取。而(f,v,a)可由自车传感器获取。
30、与现有技术相比,本发明的有益效果是:
31、1、本发明的方法在计算过程有区别于传统计算方法,非线性数字字典估计方法不依赖于额外的电子传感器,如陀螺仪、加速度计、三维数字高程地图等。对于量产车辆能控制成本,属于较好的解决方案。
32、2、传统部分低端车辆,质量估计模型非常简单,只适用于平路估计,无法满足带有坡度的质量估计。而本发明非线性数字字典法可以同时兼顾这两种路况。
33、3、单独的newton迭代法求解带有坡度的车辆质量估计问题,其稳定性略差,易陷入局部最优,坡度估计值误差范围受影响较小,但是质量估计结果偏差较大。非线性数字字典质量估计方法恰解决了此问题,仅使用了newton迭代法估计的角度,然后,结合数字字典的求解精度较高,质量估计结果的误差在可控范围内。
34、4、三维数字高程地图来求解质量估计问题,缺陷在于三维地图成本维护极高,路段实时更新与软件同步有一定的时间差。因此,非线性数字字典的质量估计方法,覆盖面广、容易推广、受限制较小。
- 还没有人留言评论。精彩留言会获得点赞!