一种基于几何和语义的视觉定位与建图方法、系统、设备及介质
本发明属于智能机器人,具体涉及一种基于几何和语义的视觉定位与建图方法、系统、设备及介质。
背景技术:
1、视觉slam(simultaneous localization and mapping)是一种先进的计算机视觉技术,用于同时实时定位和构建未知环境的地图,被广泛应用于自主导航、增强现实、机器人和虚拟现实等领域。传统上,导航和地图构建是分开进行的,其中导航依赖于预先构建的地图,而地图则需要已知位置信息。然而,对于许多实际应用,如无人机、无人车辆和机器人等,环境可能是未知的或动态变化的,这就需要实时进行定位和地图构建,即slam技术的出现。视觉slam利用计算机视觉技术,通过处理来自相机或摄像头的视觉输入数据,在未知环境中同时估计自身的位置(定位)和构建环境地图。它基于视觉特征提取、特征匹配、姿态估计、三维重建等关键技术,具有以下几个关键优势:1.实时性:视觉slam系统可以在实时环境下处理传感器数据,快速更新定位信息和地图。2.无需先验信息:相比传统方法,视觉slam不需要先验地图或gps等先验信息,适用于未知或动态环境。3.精度:随着计算机视觉和传感器技术的不断发展,视觉slam的定位和地图构建精度不断提高。4.独立性:相比其他slam技术,如激光slam,视觉slam仅依赖于相机或摄像头,不需要附加传感器,降低了系统复杂性和成本。然而,视觉slam技术也面临一些挑战,如遮挡、快速运动和大规模环境等情况可能影响定位和地图的精度。
2、公开号为cn114627184a的专利申请,提供了一种基于直接法的移动机器人双目视觉定位与建图方法,将图像进行分割并选取分区域阈值的特征点,设计基于双向静态立体匹配的初始化算法,使用基于辐射度误差约束的后端图优化模型,解决了视觉slam系统存在实时性不足的问题,但是,其系统依赖于静态环境,使得系统不能够在实际的高动态场景中鲁棒的运行。
3、公开号为cn110838145a的专利申请,提供了一种室内动态场景的视觉定位与建图方法,对查询图像和目标图像进行特征点提取和匹配,并通过词袋模式加速特征点的匹配,对匹配后的特征点添加精度约束与几何约束,采用双向打分规则对特征点进行双约束,得到最终滤除后的特征点,将其添加到orb-slam视觉里程计框架中,提高了定位与建图的精度,但是其对动态目标的滤除只是用双向打分规则,不能够完全剔除场景中的动态目标,同时未对双向打分规则误判的特征点进行优化处理。
技术实现思路
1、为了克服上述现有技术的不足,本发明的目的在于提供一种基于几何和语义的视觉定位与建图方法、系统、设备及介质,通过使用神经网络进行语义分割、特征点提取和使用二项式概率模型对分割信息边缘进行完善,剔除了场景中的动态对象,通过使用几何关联约束,对语义分割未能处理的动态对象进行了进一步补充,能够更好的剔除场景中不良的动态信息;本发明能够有效的提高视觉slam系统在现实高动态场景中定位与建图的准确性和鲁棒性,大大减少了不良和不稳定的数据关联。
2、为了实现上述目的,本发明采用的技术方案是:
3、一种基于几何和语义的视觉定位与建图方法,包括以下步骤:
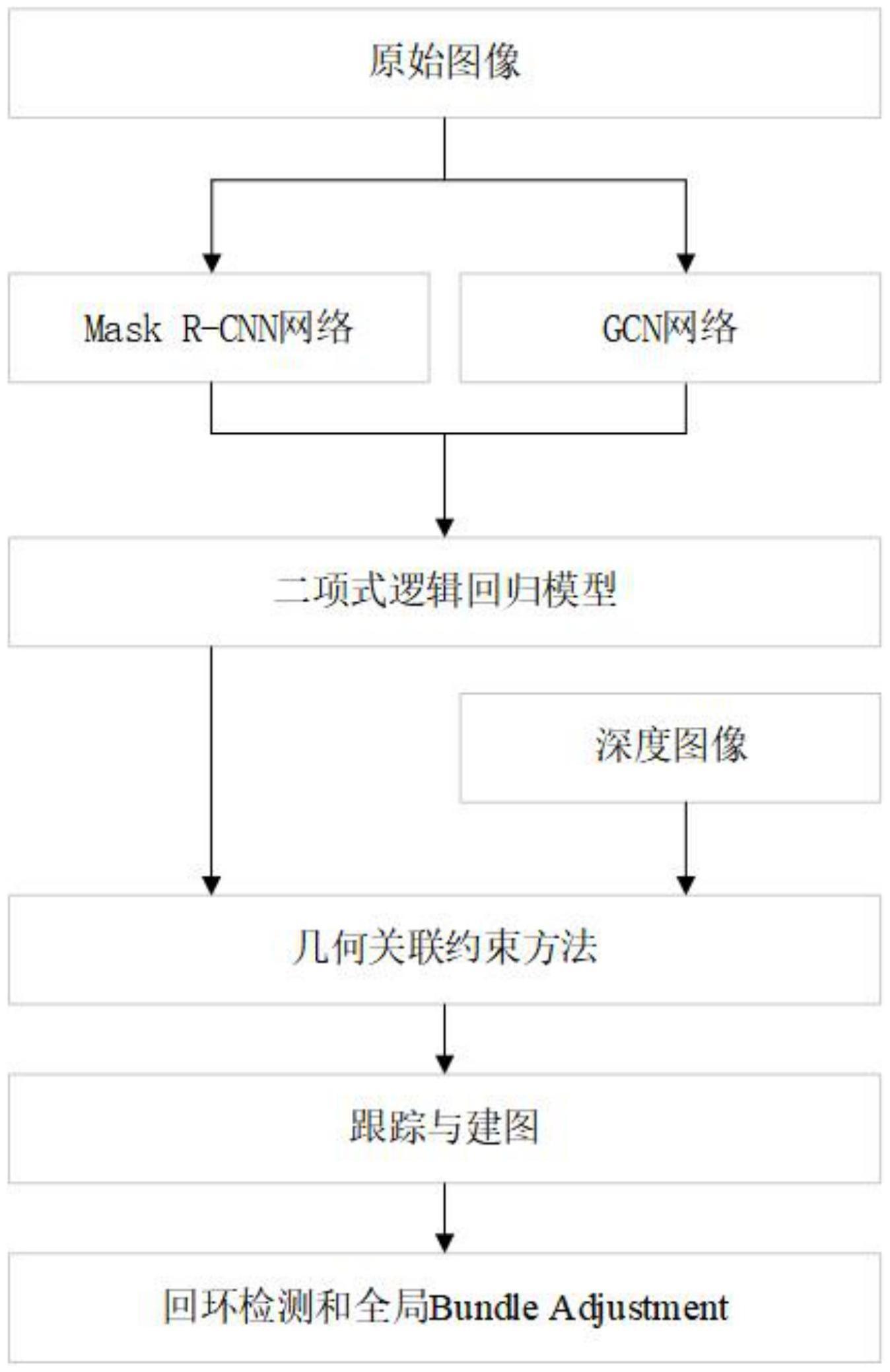
4、步骤s1:将原始图像输入到mask r-cnn网络模型中,对原始图像进行逐像素的语义分割,得到实例标签和图像的二进制掩膜,分割出的实例标签用于跟踪不同的对象,根据图像的二进制掩膜获得原始图像场景中出现的全部动态对象;
5、步骤s2:将原始图像输入到gcn网络模型中,对原始图像中的特征进行提取,得到图像上的全部特征点;
6、步骤s3:对步骤s1中mask r-cnn网络模型获取的图像的二进制掩膜和步骤s2中gcn网络模型获取的全部特征点,使用二项式逻辑回归模型计算每个关键点的语义分割动态概率,对于图像的二进制掩膜中概率小于0.75的特征点被认为是静态特征点,得到处理后的图像中的特征点;
7、步骤s4:通过步骤s1中mask r-cnn网络模型获取的图像的二进制掩膜对原始图像场景中的动态对象进行剔除后,使用步骤s3获得处理后的图像中的特征点进行定位,得到当前帧图像的关键帧序列;
8、步骤s5:将当前帧图像特征与步骤s4中获得的对应的关键帧序列中选取的最高重叠关键帧的特征的角度和距离进行比较,若两个帧图像的特征角度超过预设的阈值,则认为当前帧图像特征为动态特征,在特征角度未超过阈值的情况下,则判断深度差是否超过预设的阈值,若深度差超过一定阈值,则认为是动态特征,否则认为特征是静态特征,比较完成后,得到处理完全的图像中的静态特征点;
9、步骤s6:将步骤s5处理完全的图像中的静态特征点输入到跟踪与建图线程中,通过逐帧的关联对相机位姿估计,完成建图工作,得到全局地图;
10、步骤s7:对步骤s6得到的全局地图进行回环检测和全局bundleadjustment的优化工作,优化全局地图定位的精确性。
11、所述步骤s2中gcn网络模型的二元激活层如下:
12、forward:
13、backward:
14、其中,b是特征f的二值化版本,1|f|≤1取消了绝对值大于1的代表f各个特征响应的梯度,1|f|≤1是用于反向传播梯度的所谓硬符号函数的直通估计器。
15、所述步骤s3的二项式逻辑回归模型包括:语义分割结果标签、特征点语义分割结果标签集合、像素点几何标签集合、特征点与边界像素点距离和回归模型的定义;
16、所述语义分割结果标签定义如下:
17、
18、其中,表示特征点pi在时间t时刻的语义分割结果标签;
19、所述特征点语义分割结果标签集合定义如下:
20、
21、其中,st表示特征点语义分割结果标签的集合,其中n为特征点的数量;
22、所述像素点几何标签集合定义如下:
23、
24、其中,bt为时间t时边界像素点的集合,其中m为边界像素点的数量,所有的边界点都包含在bt中;
25、所述特征点与边界像素点距离定义如下:
26、
27、其中,dist(pi,bt)表示特征点pi与边界像素点之间的距离;
28、所述回归模型的定义如下:
29、
30、其中,表示语义分割特征点pi的动态该概率,其中α为平衡检测结果曲线的影响因子。
31、所述步骤s5将当前帧图像特征与对应的最高重叠的关键帧特征的角度和距离进行比较,通过几何关联约束算法剔除动态特征点,其中,几何关联约束算法过程如下所示:
32、
33、
34、其中,若返回值为sf,则判断当前帧图像上的当前特征为静态特征,若返回值为df,则判断当前帧图像上的当前特征为动态特征。
35、所述步骤s6中逐帧关联进行位姿估计和全局地图的构建过程包括以下步骤:
36、步骤s6.1、检查缓冲队列中是否含有关键帧;
37、步骤s6.2、取出步骤s6.1缓冲队列中的第一个关键帧进行处理;
38、步骤s6.3、剔除地图中出现的坏点;
39、步骤s6.4、使用对极几何或三角化方法创建新的地图点,对步骤s6.3剔除坏点的地图进行补充;
40、步骤s6.5、将步骤s6.2中取出的第一关键帧与其共视关键帧形成的地图点融合;
41、步骤s6.6、对步骤s6.3中的地图进行局部ba优化;
42、步骤s6.7、剔除步骤s6.1缓冲队列的冗余关键帧;
43、步骤s6.8、将步骤s6.2中取出的当前关键帧加入到闭环检测线程中。
44、所述步骤s7中回环检测的过程包括以下步骤:
45、步骤s7.1.1、取出缓冲队列头部关键帧作为当前检测闭环关键帧;
46、步骤s7.1.2、如果距离上次回环检测时间小于5秒,则不进行回环检测;
47、步骤s7.1.3、计算步骤s7.1.1当前检测闭环关键帧与共视关键帧间的最大相似度;
48、步骤s7.1.4、根据步骤s7.1.3获得的最大相似度寻找当前检测闭环关键帧的闭环候选关键帧;
49、步骤s7.1.5、在步骤s7.1.4中的闭环候选关键帧形成的闭环候选关键帧组和循环变量中存在的闭环候选关键帧组之间寻找匹配;
50、步骤s7.1.6、维护循环变量,使得步骤s7.1.4中的闭环候选关键帧形成的闭环候选关键帧组当作下一帧之前的闭环候选关键帧组;
51、所述步骤s7对步骤s6得到的全局地图进行全局bundle adjustment的优化,是指使用最小化重投影误差优化运动点的求解,得到旋转矩阵r和平移矩阵t,使用求解得到的旋转矩阵r和平移矩阵t来优化地图上点的位姿;
52、其中,使用观测模型对全局地图进行全局bundle adjustment优化:
53、步骤s7.2.1、世界坐标系转相机坐标系:
54、设p点的世界坐标为(x,y,z),转到相机的坐标系为:
55、p′=rp+t=(x′,y′,z′)
56、步骤s7.2.2、归一化:
57、p′c=[uc,vc,1]t=[x′/z′,y′/z′,1]t
58、步骤s7.2.3、去畸变:
59、p′c(uc,vc)→(u′c,v′c)
60、步骤s7.2.4、相机坐标系转像素坐标系:
61、us=fx·u′c+cx
62、vs=fy·v′c+cy
63、步骤s7.2.5、相机观测模型:
64、g(us,vs)=h(r,t,x,y,z)
65、步骤s7.2.6、重投影误差模型:
66、e=z-h(r,t,x,y,z)
67、其中,z是观测值,h为估测模型得到的值。
68、一种基于几何和语义的视觉定位与建图系统,包括:
69、视觉里程计模块:用于将原始图像输入到mask r-cnn网络模型中,对原始图像进行逐像素的语义分割,得到实例标签和图像的二进制掩膜,分割出的实例标签用于跟踪不同的对象;将原始图像输入到gcn网络模型中,对原始图像中的特征进行提取,得到图像上的全部特征点;通过二项式逻辑回归模型计算每个关键点的语义分割动态概率;通过使用处理后的图像中的特征点进行定位,得到小范围内几帧图像的关键帧;通过几何关联约束算法剔除动态特征点;
70、建图模块:用于将处理完全的图像中的静态特征点输入到跟踪与建图线程中,通过逐帧的关联实现对相机位姿估计,完成建图工作,得到全局地图;
71、非线性优化模块:用于对全局地图进行回环检测和全局bundle adjustment的优化工作,优化全局地图定位的精确性。
72、本发明还提供了一种基于几何和语义的视觉定位与建图设备,包括:
73、存储器:存储上述一种基于几何和语义的视觉定位与建图方法的计算机程序,为计算机可读取的设备;
74、处理器:用于执行所述计算机程序时实现所述的一种基于几何和语义的视觉定位与建图方法。
75、本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时能够实现所述的一种基于几何和语义的视觉定位与建图方法。
76、相较于现有技术,本发明的有益效果为:
77、1、本发明提供一种基于几何和语义的视觉定位与建图方法,首先通过使用神经网络进行语义分割和使用二项式概率模型对分割信息边缘进行完善,剔除了场景中的动态对象。采用gcn网络模型对图像中的特征进行提取,并且使得提取的特征更具有可重复性和分布更广的特征,能够更精准的进行后续的定位与建图工作。使用几何关联约束方法对语义分割未能处理的动态对象进行了进一步补充,能够更好的剔除场景中不良的动态信息,有效的降低不稳定和不良的数据关联。将处理完的图像通过逐帧的关联实现对相机位姿估计,完成后端优化和建图等一系列工作。
78、2、本发明通过结合语义和几何方法增强智能机器人对环境的感知能力,使用gcn网络模型对图像中的特征进行提取,增强了特征的分布广泛性。同时本发明针对大场景中的动态对象采取了语义与几何结合的方法,剔除场景中的动态目标,能够使得定位更加准确。
79、3、本发明通过采用了mask r-cnn网络模型,能够对原始图像进行逐像素的语义分割,获得实例标签和图像的二进制掩膜,实例标签能够用于跟踪不同对象,二进制掩膜可获得图像的全部动态对象,因此增强了剔除场景中动态语义信息的能力。
80、4、本发明由于采用了gcn网络模型,能够提取图像上分布较广的全部特征点,使得提取的特征点更具代表性和可跟踪性。
81、5、本发明由于采用了二项式逻辑回归模型,能够计算每个关键点的语义分割动态概率,对于概率低于0.75的特征点可被重新处理为静态特征点,使得经过mask r-cnn网络模型分割获得的掩膜边缘的特征点语义信息更加精准。
82、6、本发明由于采用了几何关联约束方法,能够使用角度和距离两个约束条件对特征进行进一步有效的判别,对于mask r-cnn网络模型和二项式逻辑回归模型不能处理的动态对象也能进行有效的分割,因此增强系统在高动态场景的适应能力。
83、综上,本发明解决智能机器人在未知动态环境下的环境感知问题,以提高智能机器人执行任务的成功率,推动智能机器人产业的发展。
- 还没有人留言评论。精彩留言会获得点赞!