一种基于多模态信息双重融合的AR互动情感识别方法和系统与流程
本技术涉及增强现实,尤其涉及一种基于多模态信息双重融合的ar互动情感识别方法和系统。
背景技术:
1、在线上文化旅游传播过程中,为了提升游客体验和情感交流,基于多模态信息融合的ar互动情感识别方法成为一个备受关注的研究方向。
2、传统的文化旅游场景通常只能通过有限的感官来传递信息,而ar技术能够通过文本、声学、视觉等多模态信息,进一步增强游客与文化遗产之间的情感互动。然而,情感识别作为ar互动体验的关键环节,面临着重要的挑战。目前的方法要么仅考虑单一的模态信息,要么忽略了不同感官所传递的情感信息存在复杂的差异和融合问题,导致情感状态的表达不够准确和全面。
3、因此,目前有关文旅的ar情感识别互动难以提供更加丰富、真实和个性化的情感交流体验,影响了游客对文化旅游场景的情感共鸣和参与度。
4、研究人员发现,现有技术在情感识别领域通常仅单一使用文本、声觉和视觉模态中的某一模态信息进行情感分析,忽略了多模态信息融合对情感识别的综合影响。此外,基于多模态信息的情感识别方法将每种模态的信息看作是同等重要的,因此通过简单的拼接来进行融合,其缺乏对各个模态之间关联性和重要程度的充分考虑,无法全面捕捉情感信息的多模态表达。此外,现有技术在自监督学习方面的应用相对有限,未能充分利用各模态之间的互信息,导致在融合表示中可能存在模态偏差,如噪声过多、共性过少,影响情感识别的准确性。
5、申请内容
6、本技术提供一种基于多模态信息双重融合的ar互动情感识别方法及系统,其充分利用文本、声觉和视觉模态信息,实现了情感信息的全面融合和建模。本方法设计了混合的融合方法,通过基于自注意力机制的融合方法,有效地考虑了各模态信息之间的关联性和重要程度,提升情感识别的全面性。
7、同时,设计基于自监督学习的融合方法,成功地提取自监督信号并自动纠正模态偏差,剔除了无用的噪声数据,保留了模态信息的共性,提升了情感识别的准确性。该方法为情感识别任务带来了显著的技术进步,为用户提供了更丰富、真实和个性化的情感交互体验,增强了用户对ar互动情感识别的感知和参与度。
8、为解决上述问题,根据本技术的第一方面,本技术提出了一种基于多模态信息双重融合的ar互动情感识别方法,包括:
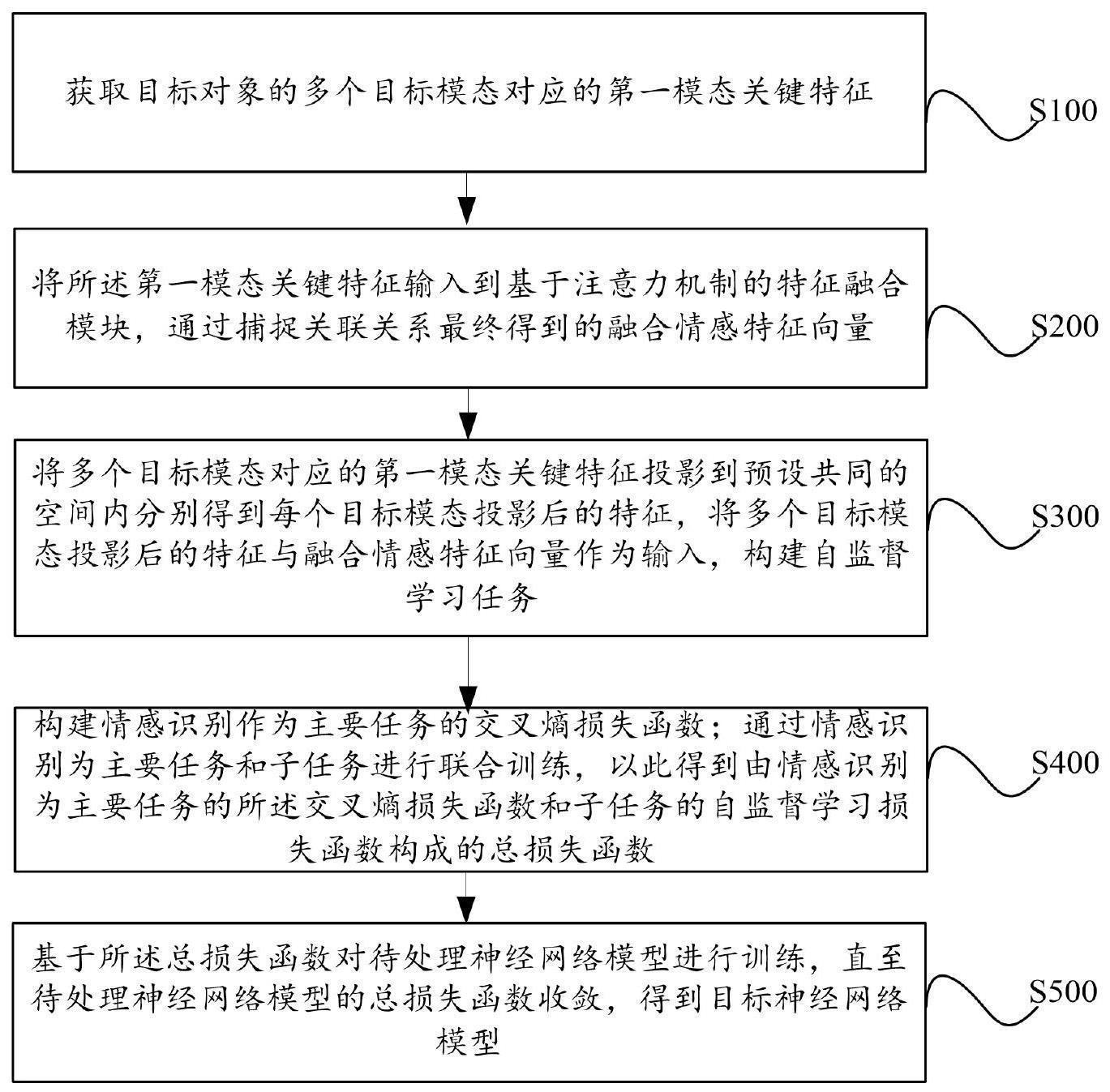
9、获取目标对象的多个目标模态对应的第一模态关键特征;
10、所述目标模态包括文本编码通道、声学编码通道以及视觉编码通道;所述第一模态关键特征为文本编码通道的情感特征向量、声学编码通道的情感特征向量以及视觉编码通道的情感特征向量;
11、将所述第一模态关键特征输入到基于注意力机制的特征融合模块,通过捕捉关联关系最终得到的融合情感特征向量;
12、将多个目标模态对应的第一模态关键特征投影到预设共同的空间内分别得到每个目标模态投影后的特征,将多个目标模态投影后的特征与融合情感特征向量作为输入,构建自监督学习任务;
13、所述自监督学习任务包括三个子任务,三个子任务分别用于在实现求取目标模态投影后的特征与融合情感特征向量之间的互信息最大化之后,再通过求取所述互信息最大化之间的差异来表示子任务的自监督学习损失函数;
14、构建情感识别作为主要任务的交叉熵损失函数;通过情感识别为主要任务和子任务进行联合训练,以此得到由情感识别为主要任务的所述交叉熵损失函数和子任务的自监督学习损失函数构成的总损失函数;
15、基于所述总损失函数对待处理神经网络模型进行训练,直至待处理神经网络模型的总损失函数收敛,得到目标神经网络模型。
16、优选的,作为一种可实施方式;所述第一模态关键特征为文本编码通道的情感特征向量ft、声学编码通道的情感特征向量fa以及视觉编码通道的情感特征向量fv。
17、优选的,作为一种可实施方式;将所述第一模态关键特征输入到基于注意力机制的特征融合模块,通过捕捉关联关系最终得到的融合情感特征向量,具体包括:
18、将所述第一模态关键特征输入到基于注意力机制的特征融合模块,然后将文本编码通道的情感特征向量ft、声学编码通道的情感特征向量fa以及视觉编码通道的情感特征向量fv分别转换为三个向量矩阵q、k、v;
19、所述三个向量矩阵q、k、v是使用线性投影的查询、键和值,计算公式如下所示:
20、
21、
22、
23、其中,qx、kx、vx分别是文本编码通道对应线性投影的查询、键和值;
24、qy、ky、vy分别是声学编码通道对应线性投影的查询、键和值;
25、qz、kz、vz分别是视觉编码通道对应线性投影的查询、键和值;
26、和以及是对应的投影矩阵;
27、计算查询和键的点积,将点积的计算结果按比例缩放并按行排列,并由softmax函数归一化后以获得注意力权重;
28、
29、
30、
31、其中,zt、za和zv分别表示文本编码通道、声学编码通道以及视觉编码通道的self-attention层的输出,dk为输入的特征向量的维度;
32、然后分别经过全局最大池化层降维处理,得到一维的文本特征向量st、一维的声学特征向量sa和一维的视觉特征向量sv;
33、最后将输出的三个一维的情感特征向量(即各种一维特征向量)整合在一个目标向量中,得到的目标向量用ffusion表示,如下所示:
34、ffusion=concat[st,sa,sv];
35、所述目标向量为融合情感特征向量ffusion。
36、优选的,作为一种可实施方式;将多个目标模态对应的第一模态关键特征投影到预设共同的空间内分别得到每个目标模态投影后的特征,将多个目标模态投影后的特征与融合情感特征向量作为输入,构建自监督学习任务,具体包括:
37、将文本编码通道的情感特征向量ft、声学编码通道的情感特征向量fa以及视觉编码通道的情感特征向量fv分别投影到一个预设共同的空间中获得统一表示计算如下:
38、
39、
40、
41、其中,w和b是各个目标模态的权重和偏置,relu是激活函数;
42、将多个目标模态投影后的特征分别与融合情感特征向量ffusion作为输入,构建自监督学习任务;
43、目标模态投影后的特征与融合情感特征向量ffusion之间的互信息最大化之后,再通过求取所述互信息最大化之间的差异来表示子任务的自监督学习损失函数;
44、所述子任务的自监督学习损失函数如下:
45、
46、
47、
48、其中,采用infonce()函数实现互信息最大化;
49、最后融合三个子任务的自监督学习损失函数形成最终的子任务损失:
50、
51、优选的,作为一种可实施方式;所述构建情感识别作为主要任务的交叉熵损失函数,具体包括:
52、在得到融合情感特征向量表示ffusion之后,使用softmax分类层来完成最终的情感分类任务,为情感分类预测值;
53、
54、使用交叉熵损失函数lossmain作为情感识别的主要任务的损失,用于评价预测值和情感分类真实值之间的差异,其计算方式如下:
55、
56、其中,y表示情感分类真实值,表示情感分类预测值。
57、优选的,作为一种可实施方式;通过情感识别为主要任务和子任务进行联合训练,以此得到由情感识别为主要任务的所述交叉熵损失函数和子任务的自监督学习损失函数构成的总损失函数,具体包括:
58、将情感识别作为主要任务与自监督学习作为子任务进行联合训练,以此得到由情感识别为主要任务的所述交叉熵损失函数和子任务的自监督学习损失函数构成的总损失函数;
59、所述总损失函数如下:
60、
61、其中λ1和λ2分别是用来调节自监督学习的力度和l2正则化力度的超参数,θ表示bert框架预训练模型、covarep框架预训练模型、mtcnn框架预训练模型的训练参数集合。
62、优选的,作为一种可实施方式;在获取目标对象的多个目标模态对应的第一模态关键特征之前,还包括;
63、将有关情感的文本数据作为输入,采用bert框架预训练模型对文本数据进行处理,提取获得对应的文本编码通道的情感特征向量ft。
64、将有关情感的音频数据作为输入,使用covarep框架来提取声学编码通道的情感特征向量fa;
65、将有关情感的视频数据作为输入,使用mtcnn框架预训练模型提取视觉编码通道的情感特征向量fv。
66、一种基于多模态信息双重融合的ar互动情感识别系统,包括获取模块、自注意力处理模块、自监督学习处理模块和联合处理模块;其中,
67、获取模块,用于获取目标对象的多个目标模态对应的第一模态关键特征;
68、自注意力处理模块,用于将所述第一模态关键特征输入到基于注意力机制的特征融合模块,通过捕捉关联关系最终得到的融合情感特征向量;
69、自监督学习处理模块,用于将多个目标模态对应的第一模态关键特征投影到预设共同的空间内分别得到每个目标模态投影后的特征,将多个目标模态投影后的特征与融合情感特征向量作为输入,构建自监督学习任务;所述自监督学习任务包括三个子任务,三个子任务分别用于在实现求取目标模态投影后的特征与融合情感特征向量之间的互信息最大化之后,再通过求取所述互信息最大化之间的差异来表示子任务的自监督学习损失函数;
70、联合处理模块,用于构建情感识别作为主要任务的交叉熵损失函数;通过情感识别为主要任务和子任务进行联合训练,以此得到由情感识别为主要任务的所述交叉熵损失函数和子任务的自监督学习损失函数构成的总损失函数。
71、一种电子设备,包括:存储器、处理器及存储在所述存储器上并在所述处理器上运行的基于多模态信息双重融合的ar互动情感识别处理程序,所述基于多模态信息双重融合的ar互动情感识别处理程序被所述处理器执行时实现基于多模态信息双重融合的ar互动情感识别方法的步骤。
72、一种计算机可读存储介质,所述计算机可读存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现所述基于多模态信息双重融合的ar互动情感识别方法的步骤。
73、与现有技术相比,至少存在如下方面的技术优势:
74、本实施例提出了一种多模态信息双重融合的ar互动情感识别方法,其提出了混合的融合方法有效地将不同感官传递的情感信息进行双重建模,从而提高了ar交互情感识别的全面性和准确性。
75、本实施例在具体实施过程中,将第一模态关键特征输入到基于注意力机制的特征融合模块,通过捕捉关联关系最终得到的融合情感特征向量;将多个目标模态对应的第一模态关键特征投影到预设共同的空间内分别得到每个目标模态投影后的特征,将多个目标模态投影后的特征与融合情感特征向量作为输入,构建自监督学习任务;自监督学习任务包括三个子任务,三个子任务分别用于在实现求取目标模态投影后的特征与融合情感特征向量之间的互信息最大化之后,再通过求取所述互信息最大化之间的差异来表示子任务的自监督学习损失函数;然后构建情感识别作为主要任务的交叉熵损失函数;
76、最终,通过情感识别为主要任务和子任务进行联合训练,以此得到由情感识别为主要任务的所述交叉熵损失函数和子任务的自监督学习损失函数构成的总损失函数。基于所述总损失函数对待处理神经网络模型进行训练,直至待处理神经网络模型的总损失函数收敛,得到目标神经网络模型。
77、上述处理方法能够充分考虑各模态信息之间的关联性和重要程度,通过在不同模态信息之间相互施加注意力的方式,寻找文本、声觉和视觉信息之间相互认为重要的信息。该方法有效地建模不同感官之间的重要关联关系,更好地捕捉情感信息之间的多模态表达,提高情感识别的全面性。
78、综上所述,基于自注意力机制的融合方法,利用自注意力机制建模不同感官之间的重要关联关系。同时利用基于自监督学习的融合方法,利用各模态之间的互信息提取自监督信号,自动纠正融合表示中可能存在的模态偏差。
79、因此说,基于多模态信息双重融合的ar互动情感识别方法,综合考虑文本、声觉和视觉模态信息对情感识别的影响,提出双重混合的方法将不同感官传递的情感信息进行建模。
技术实现思路
- 还没有人留言评论。精彩留言会获得点赞!