一种基于生成与排序二阶段的遥感图像描述生成方法与流程
本发明涉及一种图像描述生成方法,特别是一种基于生成与排序二阶段的遥感图像描述生成方法。
背景技术:
1、遥感图像描述生成任务的目标是将图像转换为文本,不仅可以全面地捕捉图像的内容,还能理解图像中的场景信息、对象属性和对象之间的关系。这种语义理解能够提供对图像更高层次的抽象表示,使得最终生成的文本更容易被人理解和接受。因此,遥感图像描述生成任务是一种跨模态转换技术,可以将图像和文本之间进行有效的信息交流和转换。
2、现有图文生成机制没有充分考虑遥感图像本身固有的属性,比如目标尺度差异大、分布不均、弱小且密集;此外现有方案仅仅考虑目标局部特征而缺乏全局特征的融合;此外现有生成模型解码过程中存在的曝光偏差问题。
技术实现思路
1、发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种基于生成与排序二阶段的遥感图像描述生成方法。
2、为了解决上述技术问题,本发明公开了一种基于生成与排序二阶段的遥感图像描述生成方法,包括如下步骤:
3、步骤1,构建基于多尺度的目标检测网络,提取目标即所述遥感图像的区域特征,具体方法包括:
4、步骤1-1,基于swin transformer的骨架网络,提取目标即所述遥感图像的多尺度特征图,具体包括:
5、采用基于多尺度的swin transformer作为骨架网络,将所述遥感图像经过该骨架网络下采样为原始的遥感图像大小的1/8、1/16、1/32和1/64的特征图即所述的多尺度特征图;
6、记上述过程中,输入的遥感图像分辨率为h*w,则输出的多尺寸特征图为其中,特征图vl的分辨率分别为8×8、16×16、32×32和64×64,l表示第l个特征图,lb表示特征图个数;
7、步骤1-2,将步骤1-1提取得到的多尺寸特征图输入到基于deformabledetr的目标检测网络中,得到所述遥感图像的区域特征,具体如下:
8、向基于deformabledetr的目标检测网络中输入包含步骤1-1中提取得到的多尺度特征图和n个目标查询向量rd表示d维的实数向量集,d表示向量维度,ri表示第i个目标查询向量;
9、基于deformabledetr的目标检测网络经过3个以上deformable层更新目标查询向量,取最后一层的隐状态作为目标的区域特征r。
10、步骤2,构建融合全局特征和局部特征的端到端图文生成模型,使用该模型对所述遥感图像生成不同的描述文本,具体包括:
11、步骤2-1:基于多层自注意力机制,提取所述遥感图像的网格特征,具体方法包括:
12、取swin transformer骨干网络的最后一层获取得到的特征图作为输入,该特征图的维度是其中,m为64倍下采样即m=h/64*w/64,表示特征向量维度,上述特征图经过一个全连接层将其向量维度映射为d维向量经过一个包含lg层的自注意力的transformer模块更新g0,取最后一层的隐状态向量作为所述遥感图像的网格特征g∈rm*d;
13、步骤2-2:使用特征融合网络,对网格特征和区域特征进行融合,具体方法包括:
14、特征融合网络为l层网络,针对第l层交叉注意力网络其输入包含三部分:经过解码器解码的文本即单词向量记为x′l={x′i},目标的区域特征r,遥感图像的网格特征g;
15、进行融合的具体过程如下:
16、步骤2-2-1,将单词向量{x′i}作为查询,将区域特征r作为键和值进行多头注意力交互,产生注意力权重同样将单词向量{x′i}和网格特征g进行多头注意力交互得到对应注意力权重
17、步骤2-2-2,进行向量拼接得到和并将拼接向量投影到d维,经过sigmoid函数转化为概率和具体如下:
18、
19、
20、
21、其中,bg表示网格特征偏执,br表示区域特征偏执,ln()表示层归一化,表示元素相乘,wr表示区域特征权重,表示时间步骤j针对层l的注意力值;
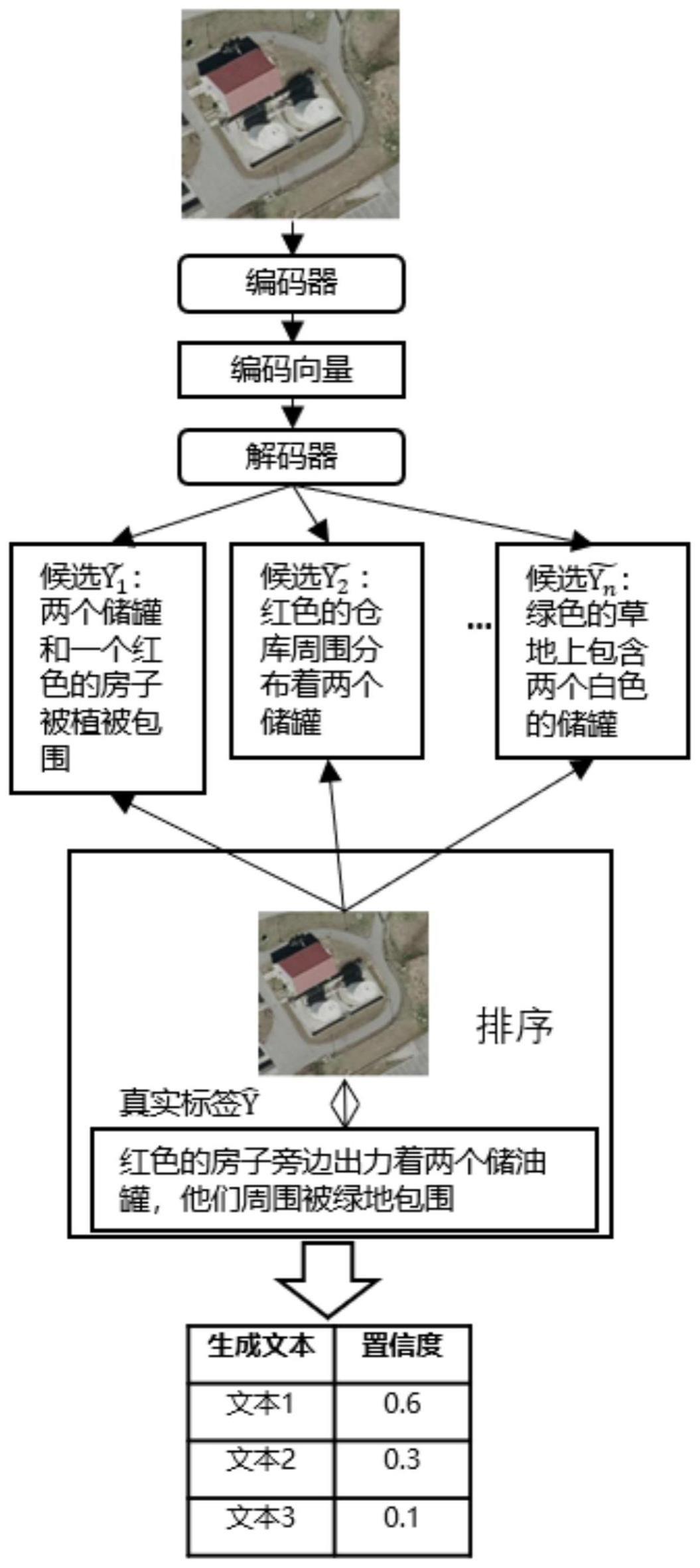
22、步骤2-2-3,对第l层中的各向量进行加权求和,经过层归一化后得到针对该层l的注意力权重
23、步骤2-3,采用自回归的方式训练基于自回归的图文生成模型g(.)做为所述的解码器,用于选择概率最大的文本作为已解码的文本,具体包括:
24、训练目标是最大似然给定输入图片i参考描述文本的条件概率具体如下:
25、
26、其中,i表示输入的遥感图像,c表示图像全局特征和局部特征编码后的表示,m表示文字长度,yk表示当前时间步k的解码概率,表示当前字在当前时间步k前的文本编码表示,表示解码网络参数。
27、步骤2-4,重复步骤2-2至步骤2-3,直至生成候选的描述文本;
28、步骤2-5、生成其他候选的描述文本,具体包括:
29、采用束约束方法生成文本,并加入相似性惩罚因子,保证生成文本的多样性,生成n个候选描述文本,即候选的描述文本s1,...,sn,并计算每个候选描述文本与真实标注的描述文本的cider值,最后按照cider值降序排列为:
30、
31、其中,表示排名为m候选描述文本。
32、步骤3,将排序方法引入步骤2所述的端到端图文生成模型中,构建基于先生成后排序的二阶段模型,即根据所述排序方法对步骤2中所生成的不同的描述文本进行排序,并选择最优的描述文本;
33、步骤3-1、构建排序网络,进行排序,即采用单流多模态网络作为排序器,依据其计算得到的语义相似度得分进行排序;
34、所述单流多模态网络输入图片和描述文本,输出为二者之间的语义相似度得分,具体包括:
35、所述描述文本经过词嵌入编码,得到词向量表示;
36、所述图片经过swin transformer得到图片的语义表征,然后经过一个投影层得到和摘要文本的词向量表示同样的维度;
37、将词向量表示和语义表征拼接输入到bert预训练模型的字符编码层,经过berttransformer编码,取最后一层隐状体作为最终的语义表征,经过一个输出为1的全连接层得到图片和描述文本的语义距离即语义相似度得分;
38、步骤3-2、基于对比学习损失计算:
39、采用基于对比学习的排序损失来衡量图片和文本摘要的距离l,具体包括:
40、
41、其中,是最大化边界的三元组损失,表示排序损失;其优化目标是:对于给定图像,两个排名差距越大的候选文本摘要之间的上述距离越大;
42、公式中和分别表示按照cider降序后排名m1、p和q的候选摘要,表示针对相应图片的标注真实文本,λij=(j-i)*λ是超参数,用来区分排序第一的摘要和其他的候选摘要的差距,d表示给定图像;
43、在所有候选摘要中,选择步骤3-1中所述的语义相似度得分最高的作为最佳摘要s:
44、
45、
46、步骤4,采用上述模型,在所述遥感图像中提取出描述文本。
47、有益效果:
48、本发明针对遥感图像目标尺度差异大、分布不均、弱小且密集提出了一种基于多尺度的目标检测网络提取目标的区域特征。
49、本发明针对现有图文生成机制仅考虑目标局部特征而缺乏全局特征的问题,提出了一种融合全局特征和局部特征的端到端图文生成模型。
50、本发明针对现有生成模型解码过程中存在的曝光偏差问题,本文将排序引入图文生成模型中,提出了一种基于先生成后排序的二阶段模型。
51、本发明能够自动对遥感图像进行语义描述,生成可读性强、反应目标的活动情况的文本描述。
- 还没有人留言评论。精彩留言会获得点赞!