一种基于数据差异性增强的数据聚类方法及系统
本发明涉及数据处理,具体涉及一种基于数据差异性增强的数据聚类方法及系统。
背景技术:
1、聚类是一种探索性的分析方法,可以用来揭示数据的内部结构或模式。作为各学科的研究热点之一,聚类被广泛应用于营销分析、自然语言处理、图像处理、生物信息学、计算机视觉等领域。在大数据时代,传统聚类算法对样本的全部特征同等对待,数据特征的高维性会导致运行传统聚类算法所获得的单一聚类结果性能不佳。上述问题亟待解决,为此,提出一种基于数据差异性增强的数据聚类方法及系统。
技术实现思路
1、本发明所要解决的技术问题在于:如何解决传统聚类算法对样本的全部特征同等对待,数据特征的高维性会导致运行传统聚类算法所获得的单一聚类结果性能不佳的问题,提供了一种基于数据差异性增强的数据聚类方法。
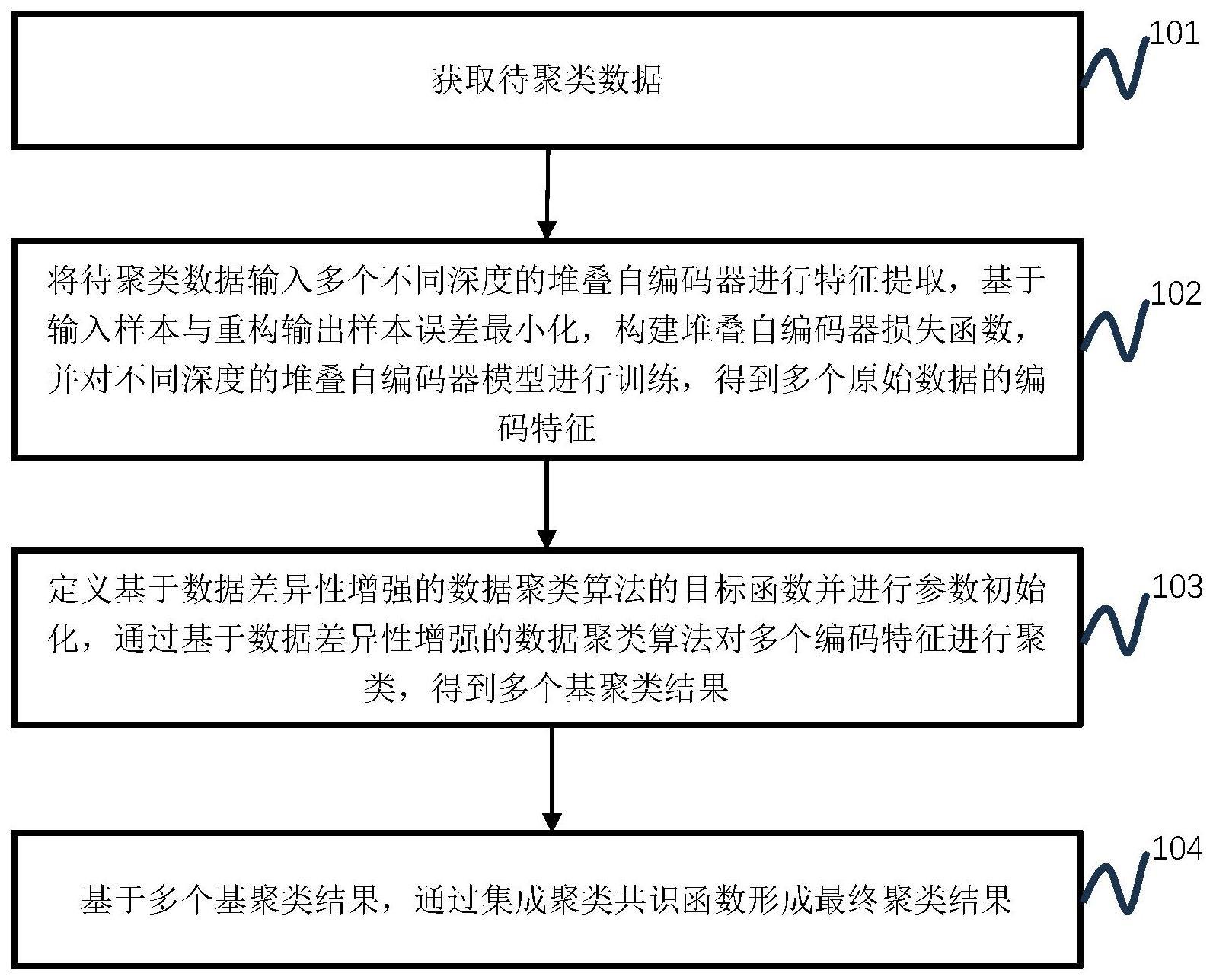
2、本发明是通过以下技术方案解决上述技术问题的,本发明包括以下步骤:
3、s1:获取待聚类数据集;
4、s2:将待聚类数据输入多个不同深度的堆叠自编码器进行特征提取,基于输入样本与重构输出样本误差最小化,构建堆叠自编码器损失函数,并对不同深度的堆叠自编码器模型进行训练,得到多个原始数据的编码特征;
5、s3:定义目标函数并进行参数初始化,对多个编码特征进行聚类,得到多个基聚类结果;
6、s4:基于多个基聚类结果,通过集成聚类共识函数形成最终聚类结果。
7、更进一步地,在所述步骤s1中,所述待聚类数据集包括待聚类图像、待聚类文本。
8、更进一步地,在所述步骤s2中,堆叠自编码器模型的损失函数为:
9、
10、其中,第一项为堆叠自编码器输入数据与重构数据之间的重构误差,第一项为‖x′-x‖2,x表示堆叠自编码器输入数据,x′表示输出数据;第二项为权值正则化项,第二项为w(a)表示堆叠自编码器第a层与第a+1层之间的权值矩阵,γ为平衡第二项权重的超参数,b表示堆叠自编码器的网络层数。
11、更进一步地,在所述步骤s3中,目标函数为:
12、
13、
14、
15、其中,n为样本总个数,c为聚类簇数,m为样本特征维度数;uik表示第k个样本对第i个簇的隶属度;fij表示第i个聚类的第j维特征权重;xk和xg分别为第k个样本和第g个样本,xkj表示第k个样本的第j维特征;vij表示第i个聚类中心的第j维特征;θ和λ为两个超参数。
16、更进一步地,在所述步骤s3中,聚类的过程下:
17、s31:初始化目标函数中的各参数;
18、s32:开始聚类,迭代更新隶属度、特征权重和聚类中心;
19、s33:判断两次迭代的目标函数差值是否小于迭代停止阈值ε;即判断||j(t)-j(t-1)||≤ε是否成立,若成立则停止迭代,若不成立则判断当前迭代次数是否大于最大迭代次数,即判断t≥t是否成立,若成立则停止迭代,否则继续迭代过程:迭代更新隶属度、特征权重和聚类中心;
20、s34:聚类结束后得到不同深度的编码特征的各个基聚类结果。
21、更进一步地,在所述步骤s31中,初始化目标函数中的各参数,即初始化如下参数:聚类数预设值c,超参数θ和λ,目标函数改变阈值ε=1e-5,初始迭代次数t=1,最大迭代次数t=100,fij初始化为1。
22、更进一步地,在所述步骤s32中,迭代更新隶属度、特征权重和聚类中心的公式分别为:
23、
24、
25、
26、更进一步地,在所述步骤s4中,共识函数采用基于投票方法的共识函数。
27、本发明还提供了一种基于数据差异性增强的数据聚类系统,采用上述的方法对数据进行聚类工作,包括:
28、数据获取模块,用于获取待聚类数据集;
29、特征编码模块,用于将待聚类数据输入多个不同深度的堆叠自编码器进行特征提取,基于输入样本与重构输出样本误差最小化,构建堆叠自编码器损失函数,并对不同深度的堆叠自编码器模型进行训练,得到多个原始数据的编码特征;
30、数据差异性增强聚类模块,用于定义目标函数并进行参数初始化,对多个编码特征进行聚类,得到多个基聚类结果;
31、输出模块,用于基于多个基聚类结果,通过集成聚类共识函数形成最终聚类结果。
32、本发明相比现有技术具有以下优点:该基于数据差异性增强的数据聚类方法,通过不同深度的堆叠自编码器获取鲁棒的低维特征表示,采用基于数据差异性增强的数据聚类算法进行聚类,获得基聚类结果,不仅能有效区分特征的不同重要性,并且能同时增强数据差异,提高了基聚类分析的聚类性能,最后利用聚类集成共识函数获取最终聚类结果,有效提高了聚类最终结果的质量,具备适用性强和聚类性能高的优良特性。
技术特征:
1.一种基于数据差异性增强的数据聚类方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于数据差异性增强的数据聚类方法,其特征在于:在所述步骤s1中,所述待聚类数据集包括待聚类图像、待聚类文本。
3.根据权利要求1所述的一种基于数据差异性增强的数据聚类方法,其特征在于:在所述步骤s2中,堆叠自编码器模型的损失函数为:
4.根据权利要求1所述的一种基于数据差异性增强的数据聚类方法,其特征在于:在所述步骤s3中,目标函数为:
5.根据权利要求4所述的一种基于数据差异性增强的数据聚类方法,其特征在于:在所述步骤s3中,聚类的过程下:
6.根据权利要求5所述的一种基于数据差异性增强的数据聚类方法,其特征在于:在所述步骤s31中,初始化目标函数中的各参数,即初始化如下参数:聚类数预设值c,超参数θ和λ,目标函数改变阈值ε=1e-5,初始迭代次数t=1,最大迭代次数t=100,fij初始化为1。
7.根据权利要求6所述的一种基于数据差异性增强的数据聚类方法,其特征在于:在所述步骤s32中,迭代更新隶属度、特征权重和聚类中心的公式分别为:
8.根据权利要求7所述的一种基于数据差异性增强的数据聚类方法,其特征在于:在所述步骤s4中,共识函数采用基于投票方法的共识函数。
9.一种基于数据差异性增强的数据聚类系统,其特征在于,采用如权利要求1~8任一项所述的方法对数据进行聚类工作,包括:
技术总结
本发明公开了一种基于数据差异性增强的数据聚类方法及系统,属于数据处理技术领域,包括获取待聚类数据集;将待聚类数据输入多个不同深度的堆叠自编码器进行特征提取,基于输入样本与重构输出样本误差最小化,构建堆叠自编码器损失函数,并对不同深度的堆叠自编码器模型进行训练,得到多个原始数据的编码特征等步骤。本发明通过不同深度的堆叠自编码器获取鲁棒的低维特征表示,采用基于数据差异性增强的数据聚类算法进行聚类,获得基聚类结果,能有效区分特征的不同重要性,并且能同时增强数据差异,提高了基聚类分析的聚类性能,最后利用聚类集成共识函数获取最终聚类结果,有效提高了聚类最终结果的质量,具备适用性强和聚类性能高的优良特性。
技术研发人员:吴紫恒,姚家祥,王兵,李聪,赵远,卢琨,汪文艳
受保护的技术使用者:安徽工业大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!