一种基于多端云计算集群的大数据存储方法及系统与流程
本发明涉及大数据存储领域,具体来说,涉及一种基于多端云计算集群的大数据存储方法及系统。
背景技术:
1、对于“大数据”,研究机构gartner给出了这样的定义。“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力来适应海量、高增长率和多样化的信息资产;麦肯锡全球研究所给出的定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征;大数据技术的战略意义不在于掌握庞大的数据信息,而在于对这些含有意义的数据进行专业化处理。换而言之,如果把大数据比作一种产业,那么这种产业实现盈利的关键,在于提高对数据的“加工能力”,通过“加工”实现数据的“增值”;从技术上看,大数据与云计算的关系就像一枚硬币的正反面一样密不可分。大数据必然无法用单台的计算机进行处理,必须采用分布式架构。它的特色在于对海量数据进行分布式数据挖掘。但它必须依托云计算的分布式处理、分布式数据库和云存储、虚拟化技术;随着云时代的来临,大数据也吸引了越来越多的关注。
2、在大数据存储领域,混合云、多云是未来信息技术基础设施的主流发展方向,但是目前混合云、多云方案落地面临复杂的大数据存储问题,而多云集群的数据管理与控制则是处理该问题的核心之一,并且在多端云计算集群中,数据可能会跨越多个地理位置存储,涉及数据传输和存储的安全问题。需要采取相应的加密和权限控制措施来保护数据的安全,不能及时发现潜在的异常情况、错误或者欺诈行为。
3、针对相关技术中的问题,目前尚未提出有效的解决方案。
技术实现思路
1、针对现有技术的不足,本发明提出一种基于多端云计算集群的大数据存储方法及系统,解决了上述背景技术中提出现有的数据可能会跨越多个地理位置存储,涉及数据传输和存储的安全问题。需要采取相应的加密和权限控制措施来保护数据的安全,不能及时发现潜在的异常情况、错误或者欺诈行为问题。
2、为实现以上目的,本发明通过以下技术方案予以实现:
3、根据本发明的一个方面,提供了一种基于多端云计算集群的大数据存储方法,该方法包括以下步骤:
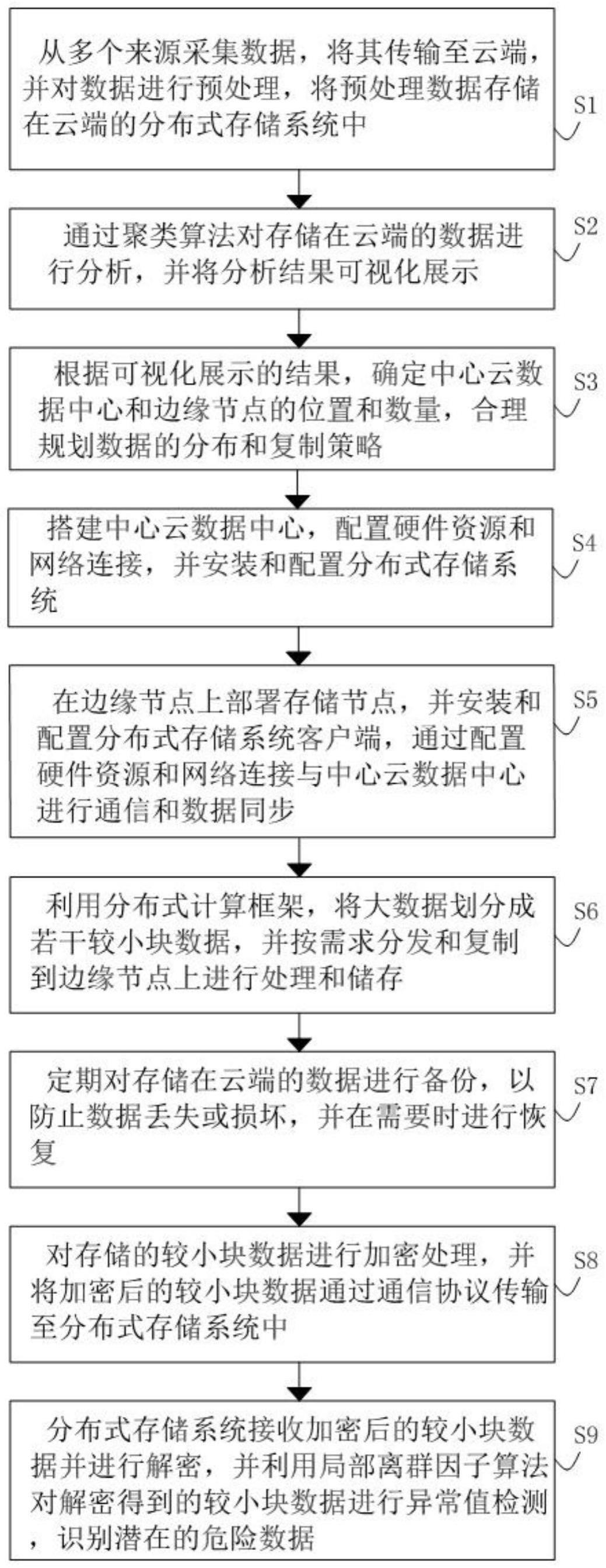
4、s1、从多个来源采集数据,将其传输至云端,并对数据进行预处理,将预处理数据存储在云端的分布式存储系统中;
5、s2、通过聚类算法对存储在云端的数据进行分析,并将分析结果可视化展示;
6、s3、根据可视化展示的结果,确定中心云数据中心和边缘节点的位置和数量,合理规划数据的分布和复制策略;
7、s4、搭建中心云数据中心,配置硬件资源和网络连接,并安装和配置分布式存储系统;
8、s5、在边缘节点上部署存储节点,并安装和配置分布式存储系统客户端,通过配置硬件资源和网络连接与中心云数据中心进行通信和数据同步;
9、s6、利用分布式计算框架,将大数据划分成若干较小块数据,并按需求分发和复制到边缘节点上进行处理和储存;
10、s7、定期对存储在云端的数据进行备份,以防止数据丢失或损坏,并在需要时进行恢复;
11、s8、对存储的较小块数据进行加密处理,并将加密后的较小块数据通过通信协议传输至分布式存储系统中;
12、s9、分布式存储系统接收加密后的较小块数据并进行解密,并利用局部离群因子算法对解密得到的较小块数据进行异常值检测,识别潜在的危险数据。
13、优选的,所述从多个来源采集数据,将其传输至云端,并对数据进行预处理,将预处理数据存储在云端的分布式存储系统中包括以下步骤:
14、s11、获取采集的多个来源相对应的重复数据、缺失值和异常值,并对重复数、缺失值和异常值据进行去噪、滤波及平滑处理;
15、s12、将采集的多个来源的数据中未处理的数据行进行联结,生成一个新的数据表,通过外部键值将不同的数据表进行关联,生成一个完整的数据表,并得到准确数据集;
16、s13、对准确数据集进行特征提取,排除无关特征,并得到多个来源数据的特征参数,并将特征参数进行可视化展示。
17、优选的,所述将采集的多个来源的数据中未处理的数据进行联结,生成一个新的数据表,通过外部键值将不同的数据表进行关联,生成一个完整的数据表,并得到准确数据集包括以下步骤:
18、s121、确定不同数据集之间的外键关系;
19、s122、根据需要将不同数据表中的数据行相互联结,创建一个新的数据表,并通过指定的外部键值进行关联;
20、s123、通过sql语句中的join操作符,将需要联结的数据表连接在一起;
21、s124、在进行联结时,确保数据的完整性约束得到满足;
22、s125、完成联结后,插入测试数据检查联结结果是否正确,确保能够正确地被识别和关联,并得到准确数据集。
23、优选的,所述通过聚类算法对存储在云端的数据进行分析,并将分析结果可视化展示包括以下步骤:
24、s21、预设聚类参数组合列表;
25、s22、以待提取对象当前特征数据作为聚类的数据集进行聚类初始化;
26、s23、通过聚类算法对数据集进行聚类,得到所有簇的集合;
27、s24、根据统计数据得到的集合进行删除处理,剔除集合中不属于特征区域的簇;
28、s25、采用集合中删除处理后的簇对特征区域进行更新,确定特征数据。
29、优选的,所述预设聚类参数组合列表包括以下步骤:
30、s211、从样本中随机的选择c个数据作为初始簇类中心点;
31、s212、通过划分算法对数据对象进行聚类,直到质心大小不再变化;
32、s213、计算误差平方和,通过c值的大小计算sc的取值;
33、s214、重复s211-s213的步骤,直到c值计算完成;
34、s215、步骤s211-s214重复进行预设次数,求出sc的平均值;
35、s216、选取最小的sc值,将其对应的c值作为最佳的聚类个数。
36、优选的,所述利用分布式计算框架,将大数据划分成较小块数据,并按需求分发和复制到边缘节点上进行处理和储存包括以下步骤:
37、s61、将大数据切分成可处理的若干较小块数据,并将较小块定义为input split;
38、s62、编写一个map函数,将若干较小块数据转换为键值对形式,并针对每个inputsplit,执行映射操作;
39、s61、将映射输出的键值对根据键进行分区,并按键进行排序;
40、s62、在映射结果分区之后,通过规约函数对每个分区内的数据进行局部聚合;
41、s65、编写一个reduce函数,对每个键的所有值进行聚合,并按照键对规约后的数据进行分组,执行缩减操作;
42、s66、将最终的缩减结果分发和复制到边缘节点上进行处理和储存。
43、优选的,所述分布式存储系统接收加密后的较小块数据并进行解密,并利用局部离群因子算法对解密得到的较小块数据进行异常值检测,识别潜在的危险数据包括以下步骤:
44、s91、分布式存储系统首先接收加密后的较小块数据,对较小块数据进行解密,获得每个较小块数据的数据点;
45、s92、计算每个较小块数据的数据点的k近邻距离和局部可达密度,通过比较较小块数据的数据点的局部可达密度与其k近邻的局部可达密度,计算局部离群因子值;
46、s93、设定局部离群因子值的阈值,若某较小块数据的数据点的局部离群因子值大于设定的阈值,将其视为异常值,得到潜在的危险数据。
47、优选的,所述计算每个较小块数据的数据点的k近邻距离和局部可达密度,通过比较较小块数据的数据点的局部可达密度与其k近邻的局部可达密度,计算局部离群因子值包括以下步骤:
48、s921、对于每个较小块数据的解密得到的较小块数据,构建特征矩阵,其中,每行代表一个较小块数据,每列代表一个特征;
49、s922、使用欧氏距离计算每个较小块数据的数据点之间的距离,以量化较小块数据的数据点之间的相似性;
50、s923、选择最优的k值,对于每个较小块数据的数据点,找到其距离最近的k个邻居,并记录k个邻居在特征矩阵的位置;
51、s924、对于每个较小块数据的数据点和它的某个k近邻,分别计算可达距离、局部可达密度及局部离群因子值;
52、s925、根据可达距离、局部可达密度及局部离群因子值得出较小块数据的数据点周围邻居的密集程度,评估较小块数据的数据点的异常程度,并按照局部离群因子值对较小块数据的数据点进行排序。
53、优选的,所述对于每个较小块数据的数据点和它的某个k近邻,分别计算可达距离、局部可达密度及局部离群因子值包括以下步骤:
54、s9241、对于较小块数据的数据点和较小块数据的数据点一个k近邻,计算较小块数据的数据点与较小块数据的数据点一个k近邻之间的实际距离和较小块数据的数据点一个k近邻与其所有k近邻之间的最大距离之间的较大值,得出可达距离;
55、s9242、利用k值除以较小块数据的数据点,得到其k近邻的可达距离之和,得出局部可达密度;
56、s9243、为较小块数据的数据点的k近邻的局部可达密度之和除以较小块数据的数据点自身的局部可达密度再除以k值,得出局部离群因子值。
57、根据本发明的另一个方面,还提供了一种基于多端云计算集群的大数据存储系统,该系统包括:数据采集与处理模块、数据分析与展示模块、云计算与边缘计算数据规划模块、云计算基础设施建设模块、边缘计算基础设施建设模块、数据分发与复制模块、数据备份与恢复模块、数据加密与传输模块及解密与异常检测模块;
58、其中,所述数据采集与处理模块,用于从多个来源采集数据,将其传输至云端,并对数据进行预处理,将预处理数据存储在云端的分布式存储系统中;
59、所述数据分析与展示模块,用于通过聚类算法对存储在云端的数据进行分析,并将分析结果可视化展示;
60、所述云计算与边缘计算数据规划模块,用于根据场景和需求,确定中心云数据中心和边缘节点的位置和数量,合理规划数据的分布和复制策略;
61、所述云计算基础设施建设模块,用于搭建中心云数据中心,配置硬件资源和网络连接,并安装和配置分布式存储系统;
62、所述边缘计算基础设施建设模块,用于在边缘节点上部署存储节点,并安装和配置分布式存储系统客户端,通过配置硬件资源和网络连接与中心云数据中心进行通信和数据同步;
63、所述数据分发与复制模块,用于利用分布式计算框架,将大数据划分成若干较小块数据,并按需求分发和复制到边缘节点上进行处理和储存;
64、所述数据备份与恢复模块,用于定期对存储在云端的数据进行备份,以防止数据丢失或损坏,并在需要时进行恢复;
65、所述数据加密和传输模块,用于对存储的较小块数据进行加密处理,并将加密后的较小块数据通过通信协议传输至分布式存储系统中;
66、所述解密与异常检测模块,用于分布式存储系统接收加密后的较小块数据并进行解密,并利用局部离群因子算法对解密得到的较小块数据进行异常值检测,识别潜在的危险数据。
67、本发明的有益效果为:
68、1、本发明采用分布式存储方式可以将数据分成多份进行存储,通过多台机器同时读写数据,进一步提高了数据访问速度的同时,还能减轻单台服务器的压力,提高了服务器的稳定性与可靠性,并且在多端云计算集群中,可以设置数据备份节点,当部分节点出现状况时,备份节点可以自动替代原节点,确保数据的安全性和连续性,从而还可以及时发现潜在的异常情况、危险数据或者欺诈行为,进而能够提供更高效、更安全、更可靠的大数据存储方式。
69、2、通过对数据进行预处理,使得提高数据质量和准确性的同时,还可以根据数据的特点和需求,进行特征提取和选择,并且通过提取关键特征或选择最具代表性的特征,可以减少数据的维度,提高数据处理和分析的效率。
70、3、通过聚类算法可以帮助我们从大规模数据中发现潜在的模式和关联,通过将相似的数据点聚集在一起形成簇或类别,使得可以更好地理解数据的结构和内在关系,可视化展示聚类结果可以直观地呈现数据的模式和分布,帮助用户发现数据中的规律和趋势,并且与传统聚类算法相比,本发明采用的改进的聚类算法不仅能够有效的自动确定簇的个数,而且适用于多维的数据。
71、4、通过对较小块数据并进行加密解密,使得通过加密数据块,可以保护数据的隐私和机密性,只有在解密之后,数据才能被正常处理和分析,从而有助于防止未经授权的访问和数据泄露,并且利用局部离群因子算法对解密得到的数据块进行异常值检测,可以识别出潜在的危险数据或异常情况,从而可以帮助及早发现潜在的数据安全问题、网络攻击或其他异常事件,进而有助于提高数据安全性、减少风险,同时提升数据的可靠性和准确性。
- 还没有人留言评论。精彩留言会获得点赞!