一种手势轨迹交互方法、智能眼镜及存储介质与流程
本技术涉及虚拟现实,尤其涉及一种手势轨迹交互方法、智能眼镜及存储介质。
背景技术:
1、虚拟现实(virtual reality,vr)交互技术是一门新兴的综合信息技术,用户可借助必要的设备与虚拟环境中的对象进行交互作用、互相影响,从而产生与亲临等同真实环境的感受和体验。
2、当下,用户通常可通过手势与虚拟现实设备(比如vr眼镜和xr眼镜等)进行交互。但是,当手部存在缺失的用户使用虚拟现实设备进行交互时,虚拟现实设备往往无法判断是由于其手部存在缺失部分还是由于物体遮挡而导致的无法检测到关键点,从而错误地执行交互指令。因此,亟待提出一种解决方案。
技术实现思路
1、本技术的多个方面提供一种手势轨迹交互方法、智能眼镜及存储介质,用以面向不同手部完整情况的用户,较为准确地执行用户想要发出的交互指令。
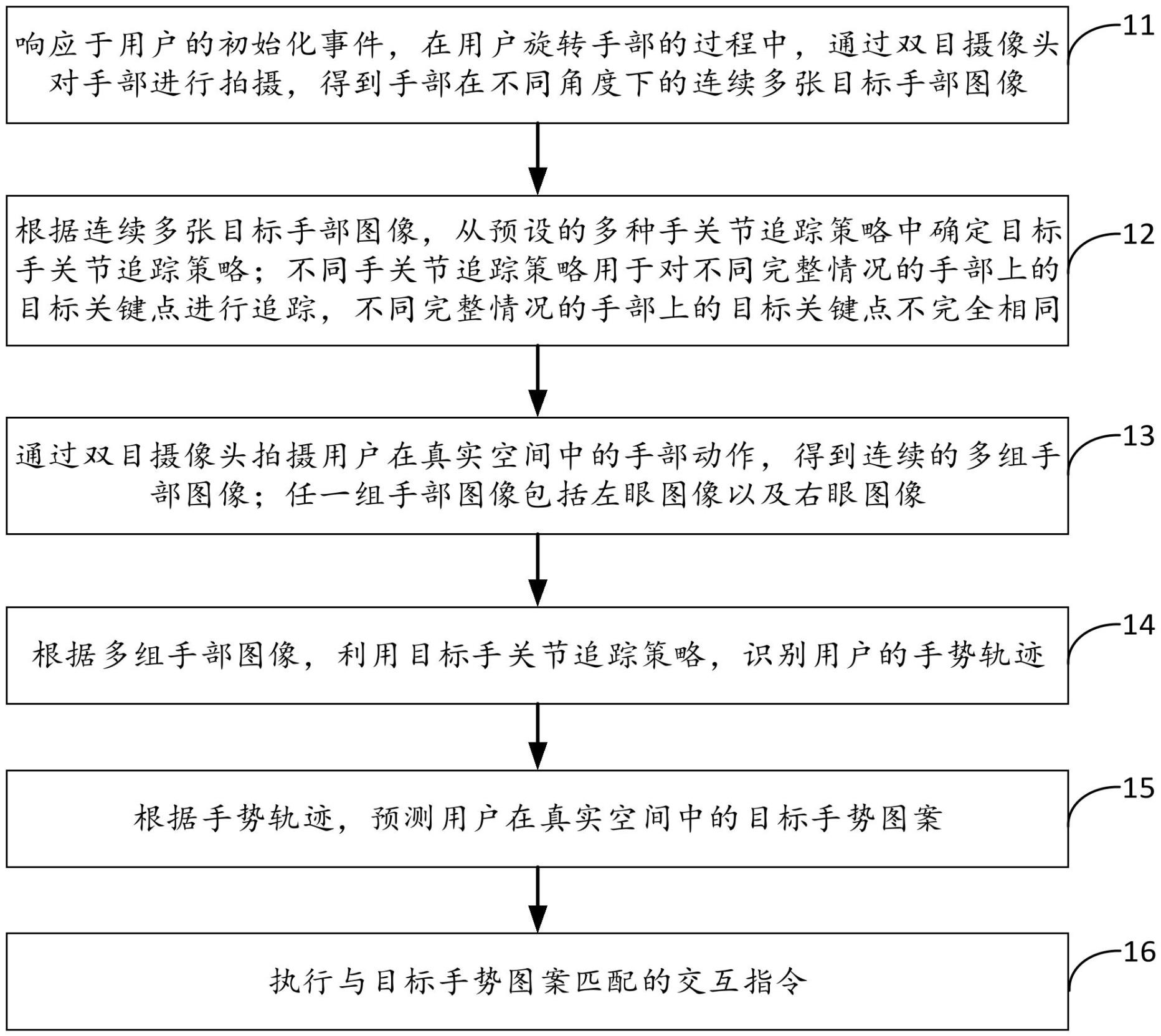
2、本技术实施例提供一种手势轨迹交互方法,适用于智能眼镜,所述智能眼镜包含双目摄像头,所述方法包括:响应于用户的初始化事件,在所述用户旋转手部的过程中,通过所述双目摄像头对所述手部进行拍摄,得到所述手部在不同角度下的连续多张目标手部图像;根据所述连续多张目标手部图像,从预设的多种手关节追踪策略中确定目标手关节追踪策略;不同手关节追踪策略用于对不同完整情况的手部上的目标关键点进行追踪,不同完整情况的手部上的目标关键点不完全相同;通过所述双目摄像头拍摄所述用户在真实空间中的手部动作,得到连续的多组手部图像;任一组手部图像包括左眼图像以及右眼图像;根据所述多组手部图像,利用所述目标手关节追踪策略,识别所述用户的手势轨迹;根据所述手势轨迹,预测所述用户在真实空间中的目标手势图案;执行与所述目标手势图案匹配的交互指令。
3、进一步可选地,根据所述连续多张目标手部图像,从预设的多种手关节追踪策略中确定目标手关节追踪策略,包括:根据所述连续多张目标手部图像,确定所述手部的完整情况;根据预设的完整情况与手关节追踪策略的对应关系,从所述预设的多种手关节追踪策略中确定目标手关节追踪策略。
4、进一步可选地,根据所述连续多张目标手部图像,确定所述手部的完整情况,包括:利用手关节追踪算法,基于所述连续多张目标手部图像,确定所述手部的至少一个手部关键点在不同角度下的坐标;根据所述手部的手部关键点在不同角度下的坐标,建立手部模型;将所述手部模型和预设的通用手部模型进行对比,并根据所述对比的结果确定所述手部的完整情况。
5、进一步可选地,根据所述多组手部图像,利用所述目标手关节追踪策略,识别所述用户的手势轨迹,包括:利用所述目标手关节追踪策略,确定用于记录轨迹的目标关键点;采用双目深度算法,识别所述双目摄像头拍摄到的多组手部图像中的所述目标关键点的坐标,得到所述目标关键点的坐标序列;根据所述目标关键点的坐标序列,确定所述用户的手势轨迹。
6、进一步可选地,利用所述目标手关节追踪策略,确定用于记录轨迹的目标关键点,包括以下任一种:在所述目标手关节追踪策略与手部健全的完整情况对应时,响应用户的目标关键点配置操作,确定所述目标关键点;在所述目标手关节追踪策略与手指部分残缺的完整情况对应时,在存在缺失的手指上选取与缺失部分最近的关键点作为目标关键点;在所述目标手关节追踪策略与单手指残缺或多手指残缺的完整情况对应时,对完全缺失的手指进行屏蔽,并响应用户针对未屏蔽手指的目标关键点配置操作,确定所述目标关键点;在所述目标手关节追踪策略与手部整体残缺的完整情况对应时,将所述用户的与残缺的手部最近的肢体末梢确定为所述目标关键点。
7、进一步可选地,采用双目深度算法,识别所述双目摄像头拍摄到的多组手部图像中的所述目标关键点的坐标,得到所述目标关键点的坐标序列,包括:从所述多组手部图像中识别所述目标关键点;针对任一时刻拍摄到的一组手部图像,确定所述目标关键点在所述任一组手部图像中的左眼手部图像以及右眼手部图像中的视差;根据所述视差,采用双目深度算法确定所述目标关键点在所述任一组手部图像的拍摄时刻的坐标。
8、进一步可选地,根据所述目标关键点的坐标序列,确定所述用户的手势轨迹,包括:从所述目标关键点的坐标序列中,确定满足手势运动启动条件的坐标,作为手势轨迹的开始位置;以及,在所述坐标序列中,确定满足手势运动停止条件的坐标,作为手势估计的停止位置;根据所述开始位置、所述停止位置以及所述开始位置与所述停止位置之间的坐标,确定所述用户的手势轨迹。
9、进一步可选地,所述手势运动停止条件包括:坐标中的深度值大于设定的第一深度阈值;所述第一深度阈值包括:所述智能眼镜提供的虚拟桌面的深度值;所述手势运动停止条件包括:坐标中的深度值小于或者等于设定的第二深度阈值;所述第二深度阈值根据所述第一深度阈值确定。
10、进一步可选地,根据所述手势轨迹,预测所述用户在所述真实空间中的目标手势图案之前,还包括:针对所述手势轨迹中的任一坐标,确定所述坐标对应的手部图像;对所述手部图像进行背景识别,以判断所述手部图像中的用户手部是否依附指定表面;若为是,则采用计算机视觉算法确定所述指定表面的法线方向;确定所述双目摄像头在所述手部图像的拍摄时刻的视线方向;根据所述法线方向与所述视线方向的夹角,对所述坐标进行单应性变换修正,得到修正后的坐标,并根据所述修正后的坐标更新所述手势轨迹。
11、进一步可选地,根据所述手势轨迹,预测所述用户在所述真实空间中的目标手势图案之前,还包括:根据所述智能眼镜的运动数据,判断所述智能眼镜在所述手势轨迹的拍摄时间范围内是否发生运动;若为是,则根据所述智能眼镜在所述拍摄时间范围内的运动矢量,对所述手势轨迹进行修正,得到修正后的手势轨迹。
12、进一步可选地,根据所述手势轨迹,预测所述用户在所述真实空间中的手势图案,包括:计算所述手势轨迹与预设的图案库中的手势图案的相似度;根据计算得到的相似度,从所述图案库中确定与所述手势轨迹的相似度最高的手势图案,作为所述手势轨迹对应的目标手势图案。
13、进一步可选地,执行与所述目标手势图案匹配的交互指令,包括:根据交互模式与手势图案的对应关系,确定所述目标手势图案对应的交互模式;在所述智能眼镜的显示屏幕上,展示所述目标手势图案以及所述目标手势图案对应的交互模式;响应指定事件的触发操作,执行所述交互模式对应的交互指令。
14、本技术实施例还提供一种智能眼镜,包括:摄像头组件、存储器和处理器;其中,所述存储器用于:存储一个或多个计算机指令;所述处理器用于执行所述一个或多个计算机指令,以用于:调用所述摄像头组件,执行所述手势轨迹交互方法中的步骤。
15、本技术实施例还提供一种计算机可读存储介质,当所述计算机程序被处理器执行时,致使所述处理器能够实现所述手势轨迹交互方法中的步骤。
16、在本实施例中,智能眼镜可响应初始化事件,在用户旋转手部过程中对手部进行拍摄得到手部在不同角度下的连续多张目标手部图像;根据这些目标手部图像从多种手关节追踪策略中确定目标手关节追踪策略。拍摄用户的手部动作,得到连续的多组手部图像;根据多组手部图像,识别用户的手势轨迹;根据手势轨迹,预测用户在真实空间中的手势图案并执行交互指令。通过这种方式,可面向不同手部完整情况的用户,根据用户个性化的手部信息较为准确地确定需要追踪的目标关键点,从而较为准确地执行用户想要发出的交互指令。
- 还没有人留言评论。精彩留言会获得点赞!