一种基于改进SwinTransformer的图片分类方法
本发明涉及图片分类,具体为一种基于改进swintransformer的图片分类方法。
背景技术:
1、随着社会的快速发展,在越来越多的信息化社会,当需要对大量数据集中的图片按照分类需求进行对应的分类区别,从而便于将多个图片进行对应的使用;
2、参阅公开号为“cn114120088a”的“一种图片分类方法”可知,该专利通过响应用户通过多个设备上传图片的操作,接收上传图片集合,所述上传图片集合中包含用户所上传的多张图片;可以对所述上传图片集合中的每一图片进行分析识别,得到所述图片对应的分析识别结果;可以将所述分析识别结果作为所述图片的标签,得到标签化的图片;可以根据所述标签化的图片中的标签信息,确定与所述标签信息匹配的预设的图片分类模型,所述图片分类模型为以所述标签信息对应的训练图片数据训练得到;最后,调用所述图片分类模型,对所述标签化的图片进行分类,而所述标签化的图片为所述上传图片集合中的每一张图片。显然,本申请可以整理多个设备中的电子图片;
3、然而在具体实施过程中,可知该专利在具体应用过程中,存在以下问题:
4、单独采用图片信息训练,学习全局特征能力不强,整体在应用于图片分类过程中,整体效果较差,使用不便,因此需要对以上问题提出一种新的解决方案。
技术实现思路
1、本发明的目的在于提供一种基于改进swintransformer的图片分类方法,以解决现有的问题:单独采用图片信息训练,学习全局特征能力不强,整体在应用于图片分类过程中,整体效果较差,使用不便。
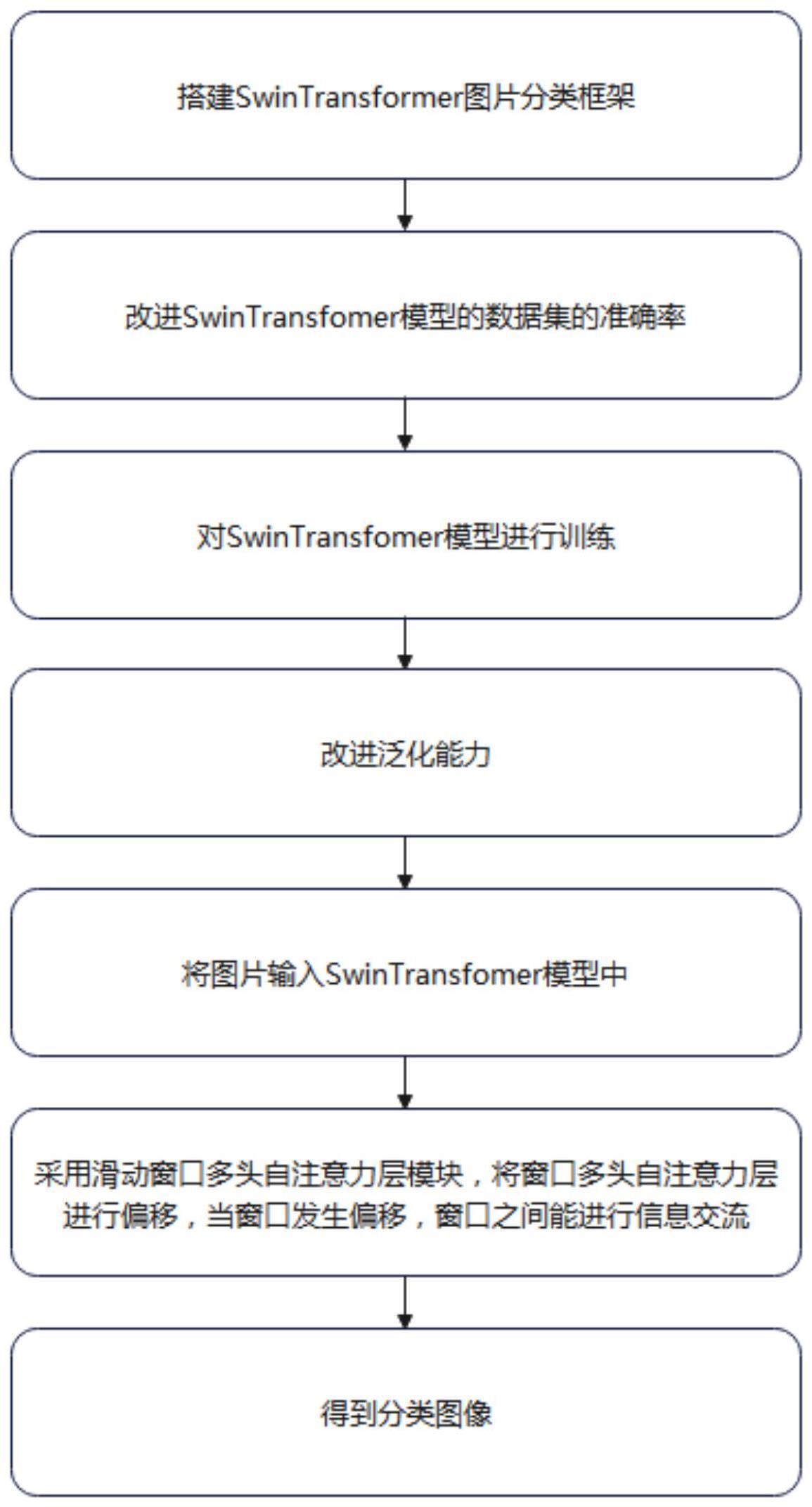
2、为实现上述目的,本发明提供如下技术方案:一种基于改进swintransformer的图片分类方法:至少包括以下步骤:
3、s1:搭建swintransformer图片分类框架,通过采用滑窗操作、层次化构建方式构建transformer,进而构成了由窗口多头自注意力层、滑动窗口多头自注意力层、标准化层和多层感知机构成的swin transfomer模型;
4、s2:改进swintransfomer模型的数据集的准确率,图像分类vit网络与swintransformer图片分类框架的配合设计;
5、s3:对swintransfomer模型进行训练;
6、s4:改进泛化能力,针对swintransformer图片分类框架进行训练样品不足的辅助提升,采用mixup和cutmix等基于混合的数据增强方法能够提高视觉transformer的泛化能力;
7、s5:将图片输入swintransfomer模型中,基于全局的自注意力计算会导致平方倍的复杂度,对每个窗口单独进行计算;
8、s6:采用滑动窗口多头自注意力层模块,将窗口多头自注意力层进行偏移,当窗口发生偏移,窗口之间能进行信息交流;
9、s7:得到分类图像。
10、优选的,所述像分类vit网络与swintransformer图片分类框架的配合设计的具体应用过程包括以下步骤:
11、对于输入的2d(x∈rc×h×w)图像数据,vit将其重新塑造成一系列扁平的2d图像块xp∈rn×(p2×c),其中c是通道数;
12、将输入分辨率为(h,w)的原始图像,划分为每个分辨率为(p,p)的图像块(补丁),其有效的输入序列长度为n=hw/p2;
13、采用了与bert相似的[class]分类标记,该标记可以表示整个图像的特征信息,被用于下游的分类任务中;
14、在大型数据集上预训练,针对较小的下游任务预训练。
15、优选地,所述s7至少包括以下步骤:
16、首先在patchpartition模块中进行分块,设定每4×4相邻的像素为patch,在channel方向进行展平;
17、然后图像经过四个stage构建特征图,其中图像在经过stage1中要先通过linearembeding层;
18、剩下三个stage都要先经过patchmerging层;
19、图像经过stage4时后会经过layernorm层、全局池化层以及全连接层最后得到分类后的图像。
20、优选地,所述s5的计算公式为:
21、ω(msa)=4hwc2+2(hw)2c(1)
22、ω(w-msa)=4hwc2+2m2hwc(2)
23、h为featuremap的高度、w为featuremap的宽度、c为featuremap的深度,m为每个窗口的大小。
24、优选地,所述s3至少包括以下步骤:
25、按照最终分类类目预备对应的多张图片组成的数据集;
26、在进行数据集训练时为加快模型收敛,需要先加载预训练权重,加载swin_tiny_patch4_window7_224预训练权重;
27、当输入图片为224×224×3图片进行前向传播时,图片经过patchpartition模块后图片变为56×56×48,此时patchpartition模块相当于大小为4×4,步长为4卷积块;
28、56×56×48的图像继续前向传播通过linearembeding层对每个像素的channel数据做线性变换,此时图像为56×56×96,经过stage1时图像为56×56×96,经过stage2时图像为28×28×192,经过stage3时图像为14×14×384,经过stage4时图像为7×7×768,stage4输出值经过layernorm层、全局池化层以及全连接层最后得到分类后的结果;
29、图像在经过四个stage时,除stage1中先通过一个linearembeding层外,剩下stage都是直接经过patchmerging层然后进行下采样;
30、swintransformerblock包含两种结构,分别是w-msa结构和sw-msa结构,这两个结构是成对使用的,因此堆叠swintransformerblock的次数是偶数;
31、利用制作完成后图片数据集,进行swintransfomer模型图像分类算法对数据集进行模型训练。
32、与现有技术相比,本发明的有益效果是:
33、本发明基于自注意机制的深度神经网络swintransformer模型和cnn模型联动设计,具有多头自注意力机制,可以通过此机制进行特征提取,可以减少对外部信息的依赖,能更好地捕获数据或特征内部的相关性,从而提取更强有力的特征,从而便于对图片进行分类,大大提高了分类的便捷性和实用性。
技术特征:
1.一种基于改进swintransformer的图片分类方法,其特征在于:至少包括以下步骤:
2.根据权利要求1所述的一种基于改进swintransformer的图片分类方法,其特征在于:所述像分类vit网络与swintransformer图片分类框架的配合设计的具体应用过程包括以下步骤:
3.根据权利要求1所述的一种基于改进swintransformer的图片分类方法,其特征在于:所述s7至少包括以下步骤:
4.根据权利要求1所述的一种基于改进swintransformer的图片分类方法,其特征在于:所述s5的计算公式为:
5.根据权利要求1所述的一种基于改进swintransformer的图片分类方法,其特征在于:所述s3至少包括以下步骤:
技术总结
本发明公开了一种基于改进SwinTransformer的图片分类方法,涉及图片分类技术领域。本发明至少包括以下步骤:S1:搭建SwinTransformer图片分类框架,通过采用滑窗操作、层次化构建方式构建Transformer,进而构成了由窗口多头自注意力层、滑动窗口多头自注意力层、标准化层和多层感知机构成的Swin Transfomer模型。本发明基于自注意机制的深度神经网络SwinTransformer模型,具有多头自注意力机制,可以通过此机制进行特征提取,使用自注意力机制相比于单独采用CNN模型能学习到全局特征,可以减少对外部信息的依赖,能更好地捕获数据或特征内部的相关性,从而提取更强有力的特征,从而便于对图片进行分类,大大提高了分类的便捷性和实用性。
技术研发人员:李旭昌,朱云飞,达瓦次仁,岳昕哲,袁雨琛
受保护的技术使用者:西藏大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!