一种基于语义信息感知的视频描述生成方法
本发明属于计算机视觉和视频理解领域,涉及一种基于语义信息感知的视频描述生成方法。
背景技术:
1、视频描述生成旨在对给定的一段输入视频自动生成一句对应的文本来概述视频中发生的事件。它需要准确的识别出视频中出现的关键实体及事件,并且使用符合人类习惯的语言方式将其描述出来。现有的方法忽视了语义信息在描述中的作用,这可能导致模型生成的描述忽略了部分重要语义。此外,现有的方法大多使用在采样帧上提取的特征作为视频的表示,这使得特征中含有大量的冗余信息干扰模型的效果。而且现有的方法忽略了高层语义之间的重要关系,导致最后的融合特征并不能很好的表现出视频信息。
技术实现思路
1、本发明的目的是为了提供一种基于语义信息感知的视频描述生成方法,充分利用了视频中的语义信息,使得生成的描述更加关注关键语义。
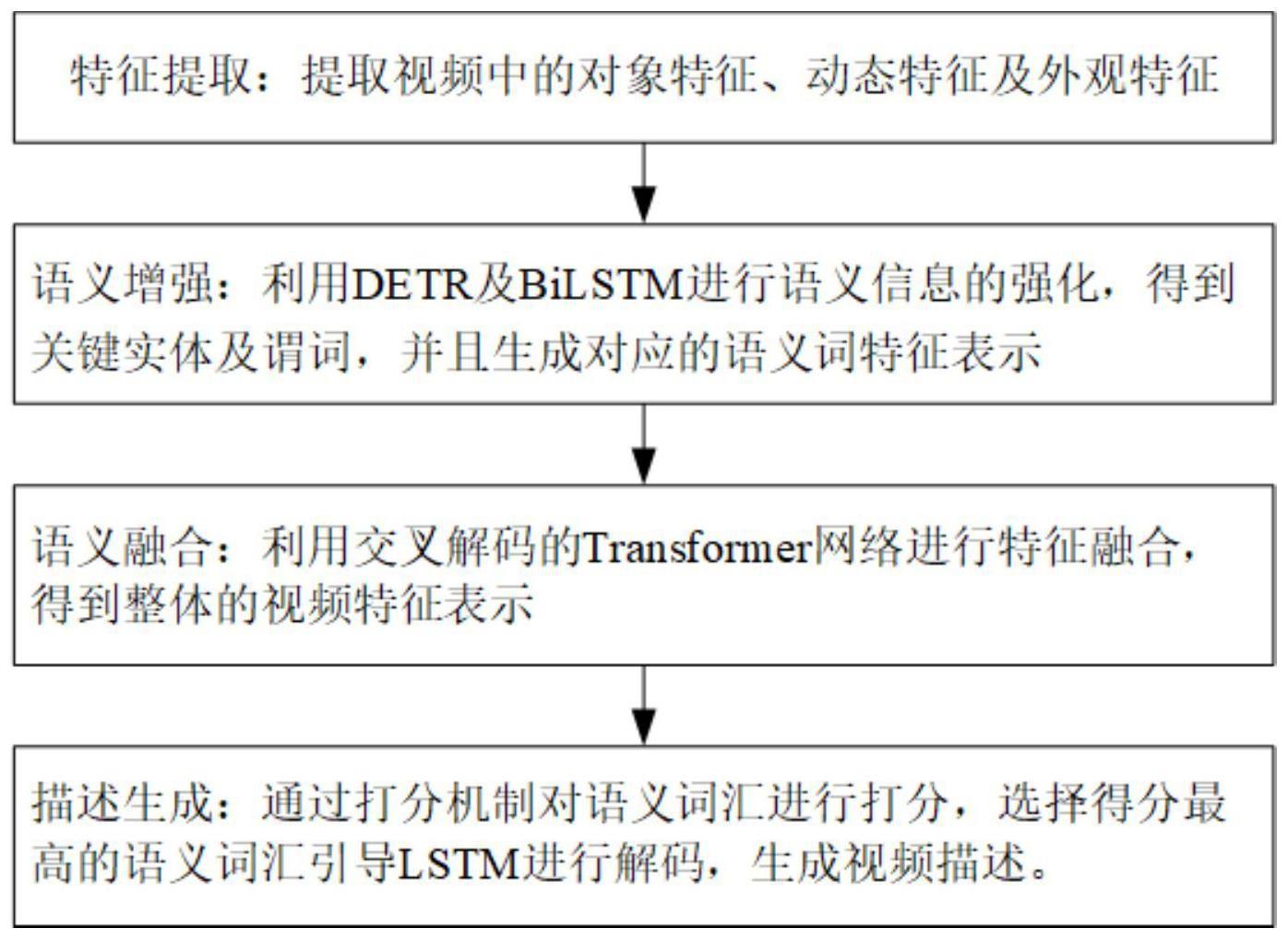
2、为解决以上技术问题,本发明的技术方案为:一种基于语义信息感知的视频描述生成方法,包括:
3、步骤1:特征提取:提取视频中的对象特征、动态特征及外观特征;
4、步骤2:语义增强:基于提取的特征通过detr及bilstm进行语义信息的强化,得到视频关键实体及谓词,并且生成对应的语义词特征;
5、步骤3:语义融合:利用交叉解码的transformer网络进行特征融合,得到整体视频的融合特征;
6、步骤4:描述生成:通过打分机制对语义词汇进行打分,选择得分最高的语义词汇引导lstm进行解码,生成视频描述。
7、进一步地,步骤1包括:
8、步骤1.1:对视频进行均匀的帧采样,得到视频的帧序列用x={x1,x2,…,xn}表示,其中n为采样的帧数目,xn表示第n帧的视频帧;
9、步骤1.2:使用2d特征提取网络对采样到的视频帧提取其外观特征vc,提取到的外观特征包含了视频的背景和环境信息;
10、步骤1.3:将采样帧的前后8帧作为一个片段并使用3d特征提取网络来提取视频的动态特征mi表示第i个动态特征;提取到的动态特征包含了视频的动作和时序交互;步骤1.4:使用目标检测网络对采样到的视频帧提取视频的对象特征vo,对象特征包含目标信息。
11、进一步地,步骤2包括:
12、步骤2.1:基于对象特征、动态特征及外观特征通过dert网络得到视频的关键实体特征o;
13、步骤2.2:基于视频动态特征mi和关键实体特征o通过sa-bilstm得到视频谓词相关的动态特征a即谓词特征。
14、进一步地,步骤2.1包括:
15、步骤2.1.1:通过dert编码器将输入的对象特征vo映射为目标的全局表示vo′,学习到对象之间的长距离依赖;
16、步骤2.1.2:将外观特征vc和动态特征vm进行拼接,通过bilstm进行编码得到序列特征间上下文关系的隐藏状态c;
17、步骤2.1.3:对隐藏状态c进行最大值池化,得到视觉信息表示v;
18、步骤2.1.4:将编码后的目标全局表示vo′,一组随机生成的关键实体查询向量和k个相同的视频视觉信息{v}×k输入到dert解码器中,解码出视频特定的关键实体特征o。
19、进一步地,步骤2.2包括:
20、步骤2.2.1:利用注意力机制将动态特征mi整合进关键实体特征中,计算出一个动态的实体特征
21、步骤2.2.2:将动态的实体特征和原本的动态特征mi进行拼接,使用bilstm进行编码,学习序列上下文信息之间的关联,得到谓词相关的动态特征a。
22、进一步地,所述步骤2.1、2.2中,在得到实体特征及谓词特征后,通过一个全连接层将关键实体的特征向量o、谓词特征a分别投射到语言的语义空间得到实体词向量e、谓词词向量p。
23、进一步地,步骤3包括:
24、步骤3.1:利用transformer编码器对输入的关键实体特征o进行编码,将其映射为关键实体的全局表示0′;
25、步骤3.2:使用多头注意力机制,分别将外观特征和谓词相关的动态特征作为多头注意力的q和k、v,以学习静态和动态信息之间的交叉表示特征;其中,q,k,v指多头注意力的不同输入,即下面式子括号中的不同位置的参数;将外观特征和谓词相关的动态特征作为多头注意力的q和k、v,分别得到两个不同层面的特征:
26、context2d=mutilheadattention(vc,a,a)
27、context3d=mutilheadattention(a,vc,vc)
28、步骤3.3:利用transformer解码器对步骤3.2得到的特征进行解码得到融合特征v。
29、进一步地,步骤3.3中,解码部分采用一种双解码器的形式,分别解码步骤3.2得到的不同层面的信息并进行拼接得到最终的融合特征v:
30、v=k*decoder(o′,q,context2d)+(1-k)*decoder(o′,q,context3d)
31、其中k为(0,1)之间可学习的系数,decoder为transformer解码器;两个解码器共用一组随机的关键实体查询向量以建立解码器间的联系。
32、进一步地,步骤4包括:
33、步骤4.1:对编码器阶段得到的所有语义词汇进行打分,进而判断该时间步每个词向量被选择的概率;所有语义词汇包括:实体词向量e、谓词词向量p;
34、步骤4.2:使用gumbel softmax策略来近似模拟最大值采样选择用于引导的词向量步骤4.3:将融合后的特征向量v,当前时间步选择出用于引导的词向量前一个单词的编码向量dw为编码维度,当前时间步lstm输出的隐藏状态ht送入lstm中解码得到当前时刻的输出。
35、进一步地,步骤4.1中,打分的具体计算公式为:
36、score(ei,h)=fc(tanh(fc(h)+fc(ei)))
37、其中ei为要打分的词向量,h为lstm上一时间步的隐藏状态,fc表示全连接层,score表示词的得分;
38、步骤4.2中,正向传播时,词选择模块首先利用softmax函数对打分器得到的所有词向量得分进行归一化处理,得到所有词向量得分的一个概率分布,接着模型会对概率分布添加一个gumbel噪声,最后使用最大值采样的方式进行采样得到决策向量zt;反向传播的过程中用softmax来近似one-hot(argmax(.))这一操作,同时添加一个温度系数τ来控制近似程度。
39、本发明具有如下有益效果:
40、一、本发明的方法利用dert和bilstm得到关键的目标实体及谓词表示,有效减少了冗余特征对描述的影响;
41、二、本发明的方法设计了交叉解码的transformer网络学习关键实体之间的交互关系,并将全局视觉信息和整个语言层面的描述连接起来,从整体层面进一步发掘视频的内容,将视觉信息映射到语义空间中;
42、三、本发明的方法设计的基于词选择的解码器,在每一个时间步挑选一个合适的词向量来引导描述的生成,突出其中的重要语义信息,提高了模型对于关键内容的表示能力。
- 还没有人留言评论。精彩留言会获得点赞!