一种基于场景蒙太奇的自监督视频场景边界检测方法
本发明涉及人工智能中的深度学习领域,特别涉及一种基于场景蒙太奇的自监督视频场景边界检测方法。
背景技术:
1、视频场景边界检测是指根据镜头描述的内容将视频中的镜头序列分割为语义连贯的故事片段。
2、当前基于人工标注数据训练模型分割视频的方法严重受限于数据标注的高昂费用。通过拆分视频段为两个伪场景、从而获得伪场景边界的方法统称为基于拆分的方法。基于拆分的方法虽然在视频场景边界检测任务上取得了一定成果,但其生成的伪边界存在命中率的上限。基于拆分视频段来获取伪边界的方法极有可能过渡分割场景,使得单一场景被分为两个伪场景,扰乱视频段中的镜头间关系,从而损害视频场景边界检测模型的性能。
技术实现思路
1、针对现有技术存在的上述问题,本发明要解决的技术问题是:如何准确检测视频场景边界。
2、为解决上述技术问题,本发明采用如下技术方案:一种基于场景蒙太奇的自监督视频场景边界检测方法,包括如下步骤:
3、s1:镜头序列的提取:获取一段输入长视频svideo=[s1,…sn],获取其中的镜头,从镜头中进行关键帧的采样。
4、s2:构建和训练视频场景蒙太奇网络模型vsm。
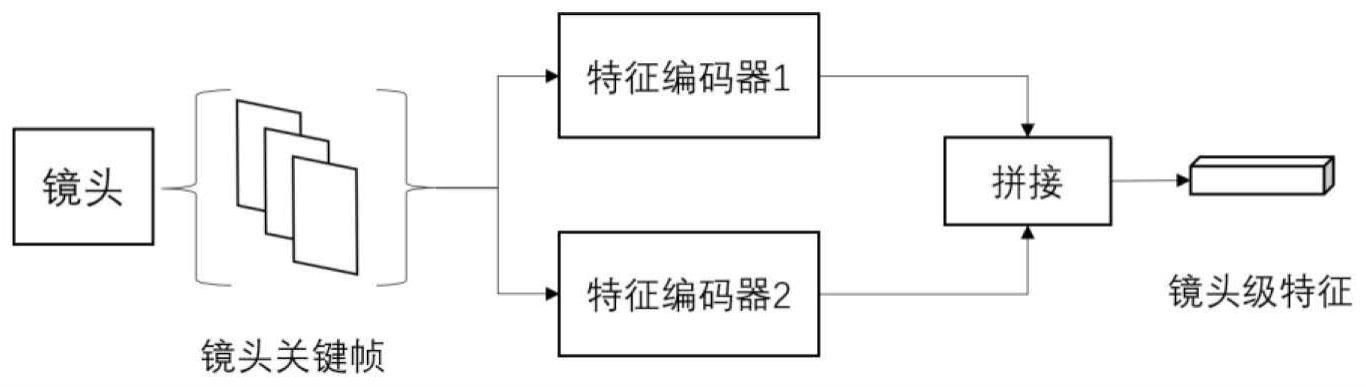
5、s21:对于svideo中的每个镜头si采用视觉编辑器编码为维特征向量xi,svideo=[s1,…sn]被编码为特征向量组成的序列xvideo=[x1,…,xb,…,xn],其中1≤γ≤n-1,1≤α≤n-γ+1和β1≤β≤n-γ+1,n表示svideo中镜头数量,n表示vsm生成的视频段中镜头的数量。
6、s22:通过随机参数γ,α,β来确定两个特征子序列的长度,以及它们的起始位置,通过拼接操作的合成的特征序列xsyn,对应着合成的镜头序列ssyn。
7、s23:通过s22的方法生成多个视频段为训练数据,以伪边界预测为代理任务,训练上下文编码器和场景边界判断模块。
8、s24:使用真实标注的场景边界信息进行对s25得到的预训练后的vsm进行微调,得到最终vsm。
9、s3:检测,将待检测视频片段通过步骤s1获取镜头序列s’,后通过步骤s21得到对应特征序列x’,将x’输入最终vsm,输出序列中间镜头为场景边界的置信度。
10、具体的,所述s21中svideo中的每个镜头si编码为维特征向量xi的具体步骤如下:
11、xi=concat(fge(si),bge(si))
12、其中concat(·)表示特征向量的拼接,fge(·)和bge(·)分别表示前景编码器和背景编,si表示第i个镜头,xi表示第i个镜头的特征。
13、作为优选,所述特征序列xsyn和ssyn合成的具体步骤如下:
14、首先选取一个随机的正整数γ,使得要截取的两个视频段中,一个包含γ个镜头,另一个包含n-γ个镜头,之后再选取两个随机的正整数α和β,作为要截取的两个视频段的起始镜头在长视频svideo中的位置,从而可从svideo截取出两个视频段作为两个伪场景,分别记作sleft=[sα,sα+1…,sα+γ+1]和sright=[sβ,sβ+1…,sβ+n-γ-1],两个伪场景共有n个镜头,将sleft和sright在时间维度上拼接在一起,形成一个合成的视频段rsyn=[sα,…sα+γ+1,sβ,…,sβ+n-γ-1]:
15、ssyn=splice(sleft,sright)
16、其中splice(·)表示在时间维度上进行拼接。α、β、γ都是不固定的随机数,每次合
17、成视频段时都会重新选取这些随机数。
18、在从xvideo=[x1,…,xn]中截取ssyn对应的部分可得到xsyn=[xα,…xα+γ+1,xβ,…,xβ+n-γ-1]。
19、作为优选,所述s23中训练训练上下文关系建模模块和场景边界判断模块的具体步骤如下:
20、将特征向量序列p=[p1,…,pn]拼接到xsyn以补充每个镜头的位置信息,最后馈入上下文关系建模模块,以获取包含上下文信息的特征向量序列rsyn=[rα,…rα+γ+1,rβ,…,rβ+n-γ-1]:
21、rsyn=context(concat(p,xsyn))
22、其中,context(·)是上下文关系建模模块,concat(·)是向量拼接操作。
23、对于视频段ssyn,伪场景sright的起始镜头sβ被看作正样本镜头,再从ssyn中随机选择一个镜头si作为负样本镜头。最后,将正负样本对应的特征向量{rβ,ri}输入到场景边界判断模块中,通过最小化二分类交叉熵损失来预训练上下文编码器:
24、
25、其中,hp(·)是场景边界判断模块,正则化项用于对抗过拟合,此处λ表示系数。
26、作为优选,用imagenet中的带有场景边界标注的训练数据集进行微调,数据集中的如果中心镜头sc是场景边界的镜头则标签yc=1,否则yc=0,损失的计算通过如下公式:
27、lsbd=-yc log(hsbd(rc))+(1-yc)log(1-hsbd(rc))
28、其中lsbd表示微调阶段的损失,yc表示微调时镜头序列中的中心镜头sc的标签,rc表示中心镜头sc的上下文关系特征,hsbd(·)表示场景边界判断模块。
29、相对于现有技术,本发明至少具有如下优点:
技术特征:
1.一种基于场景蒙太奇的自监督视频场景边界检测方法,其特征在于:包括如下步骤:
2.如权利要求1所述的一种基于场景蒙太奇的自监督视频场景边界检测方法,其特征在于:所述s21中svideo中的每个镜头si编码为维特征向量xi的具体步骤如下:
3.如权利要求2所述的一种基于场景蒙太奇的自监督视频场景边界检测方法,其特征在于:所述特征序列xsyn和ssyn合成的具体步骤如下:
4.如权利要求3所述的一种基于场景蒙太奇的自监督视频场景边界检测方法,其特征在于:所述s23中训练训练上下文关系建模模块和场景边界判断模块的具体步骤如下:
5.如权利要求2所述的一种基于场景蒙太奇的自监督视频场景边界检测方法,其特征在于:
技术总结
本发明涉及一种基于场景蒙太奇的自监督视频场景边界检测方法,通过从视频里选取两个随机位置处的视频片段,拼接两个片段合成一个语义转变点,作为伪视频场景边界,同时从余下镜头中再选取一处作为非视频场景边界,以此形成高质量的自监督信号,结合基于大数据集预先训练的视觉特征提取器,训练神经网络模型学习镜头间语义关系,检测场景边界。本发明方法有效地提高了生成的伪场景边界的质量,为场景边界检测模型提供了更多,以及更高质量的训练数据,显著提升了场景边界检测模型的准确性。
技术研发人员:王洪星,陈路,杨平安,谭嘉崴
受保护的技术使用者:重庆大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!