一种基于时序扩散概率模型的增强软测量方法
本发明涉及化工过程软测量建模领域,特别涉及一种基于时序扩散概率模型的增强软测量方法。
背景技术:
1、在智能制造的大背景下,生产过程数字化水平不断提高,各种传感器的使用使得生产者只需在监控室就能实时获取生产数据,并对生产过程进行监测和控制。然而在实际生产中,由于高温高压、强酸强碱等恶劣环境的干扰,测量装置无法直接获得生产过程的全部数据,同时部分测量装置存在滞后性,也阻碍了对关键数据的实时获取。软测量技术是一种利用生产过程中容易测量的辅助变量,借助机理模型、数据驱动建模等方式,输出过程关键变量的技术方法,对生产设备的连续平稳运行以及提高产品的质量具有重要作用。其中,基于数据驱动的软测量建模方法,不仅克服了复杂化工过程机理模型难以构建的困难,而且具有准确率高、实现简单等优点,已经成为化工过程软测量技术的主流方法。
2、尽管软测量建模方法已经在化工生产中广泛应用,但在实际生产过程中,由于数据采集成本高、采集周期长等问题的存在,仅仅使用已有的少量数据来训练软测量模型,无法得到性能稳定、预测准确的模型。因此,采用高效的数据生成方法,对原有数据集进行扩充,有利于提高软测量模型的性能。扩散模型,作为一种热门的具有强大数据生成能力的生成模型,已经在计算机视觉、语音合成、自然语言处理等领域取得了巨大成就,而其在工业软测量建模领域的应用还尚未挖掘。工业过程数据多具有时序特性,即当前时刻的采样值与之前时刻的值之间有着密切联系。为了解决时序数据有限建模困难的问题,本发明提出了基于一种时序扩散概率模型(time-series denoising diffusion probabilisticmodel,timeddpm)的软测量建模方法,通过扩充样本的数量以达到提高模型预测性能的目的。
技术实现思路
1、为了解决时序工业过程中标签样本有限建立可靠软测量模型困难的问题,本发明提出了一种基于时序扩散概率模型的增强软测量方法。通过在扩散模型的核心结构噪声预测网络中融入能学习时间特性的长短期记忆(long short term memory,lstm)单元和空间特性的一维卷积神经网络结构,同时捕捉数据的时空特性;从而生成与原始数据相似的生成样本,丰富原始样本的信息并扩大样本空间,以进一步提高模型的预测性能。
2、本发明解决其技术问题所采用的技术方案是:
3、一种基于时序扩散概率模型的增强软测量方法,所述方法包括以下步骤:
4、(1)获取动态过程的样本数据;
5、(2)时序数据的数据集划分以及预处理:
6、将获取的样本数据划分为两个部分:训练集和测试集,接着为加快模型收敛速度,消除不同变量量纲对模型训练的影响,对数据归一化处理,进一步,序列化训练集和测试集数据;
7、(3)建立时序扩散概率模型并生成扩充样本:
8、利用训练集样本训练噪声预测网络,当模型训练完毕,在时序扩散模型的反向去噪过程中生成数据,并与原始有限训练数据合并,组成新的训练集;
9、(4)建立三相流过程压力变量预测模型:
10、基于扩充后的训练集样本建立动态软测量模型;
11、(5)模型表现评估
12、为了客观评价本发明所提方法,引入评价指标均方根误差(root mean squareerror,rmse)和平均绝对误差(meanabsolute error,mae),定量衡量扩充样本的效果。
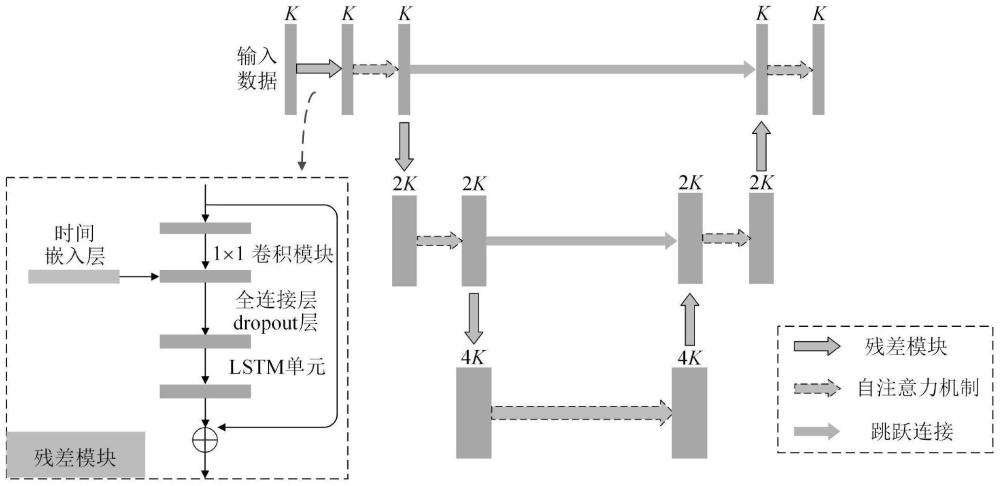
13、进一步的,时序扩散概率模型可以学习给定数据集的分布,其包括两个过程:扩散过程即前向过程和去噪过程即反向过程。扩散过程对原始数据逐渐增加高斯噪声直至原始数据变成随机噪声,而去噪过程通过去除噪声的方式,生成新的数据。时序扩散概率模型是在传统的去噪概率扩散模型(ddpm)的基础上,对其噪声预测网络unet网络进行改进,通过引入一维卷积结构和lstm单元,构成conv-lstm-unet网络。conv-lstm-unet可以同时捕捉数据的时间特性和空间特性,有助于生成与原始样本相似的时序数据,所述步骤(3)的具体过程如下:
14、步骤3.1:timeddpm的前向和反向过程:
15、准备原始数据,在t步的前向过程中,对原始数据逐步增加高斯噪声,经t步后原始数据的信息被覆盖,服从高斯分布反向过程为重构数据的过程。
16、步骤3.2:训练conv-lstm-unet网络:
17、为捕捉时序数据在时间维度和空间维度的动态特性,构建融入一维卷积网络和lstm单元的conv-lstm-unet噪声预测网络;训练conv-lstm-unet模型预测高斯噪声;当模型训练稳定即预测的噪声与高斯噪声一致时,模型停止训练。
18、步骤3.3:生成数据并与原始数据合并:
19、在t步的反向过程中,第(t-1)步的数据是在第t步数据的基础上计算得到;重复上一步骤t次,最终得到生成数据。将新生成的数据与原始数据合并,组成新的训练集用于训练lstm软测量模型。
20、进一步,所述步骤3.1的具体过程如下:
21、对于原始数据x0~q(x0),在包含t步的前向扩散过程中,第t步的数据xt是在第(t-1)步数据xt-1的基础上增加高斯噪声得到:
22、
23、在这里,为每一步所采用的方差,其值介于0~1之间,通常情况下,随着扩散过程的进行,会逐步采用更大的方差,即满足β1<β2<…<βt。根据预先定义的方差表经t步扩散后,如t=50,那么最终得到的数据xt就完全丢失了原始数据而变成了随机噪声。在本发明中,我们采用线性方差表。对于整个扩散过程,以马尔卡夫链的形式表示为:
24、
25、扩散过程的一个重要特性是我们可以直接基于原始数据x0对任意t步的xt进行采样:xt~q(xt|x0)。这里定义αt=1-βt和通过重参数技巧,得到:
26、
27、
28、扩散过程是将数据噪声化,而反向过程为去噪过程。若已知反向过程中每一步的真实数据分布q(xt-1|xt),则从随机噪声开始,逐渐去噪即能生成真实的样本,所以反向过程也是生成数据的过程。在这里,我们通过神经网络估计样本的真实分布q(xt-1|xt)。将反向过程也定义为一个马尔科夫链,记作:
29、
30、pθ(xt-1|xt)=n(xt-1;μθ(xt,t),∑θ(xt,t))
31、其中pθ(xt-1|xt)为参数化的高斯分布,其均值和方差由神经网络得到,其中θ表示神经网络中的可训练参数。扩散模型旨在得到这个训练好的网络,以构成最终的生成模型。
32、神经网络的预测目标是使预测噪声和真实的噪声一致,即:
33、
34、其中,t在[1,t]范围内取值。ε表示噪声,εθ表示一个基于神经网络的噪声预测模型。当模型训练稳定即预测的噪声与高斯噪声ε一致时,模型停止训练。
35、进一步,步骤3.2的具体过程如下:
36、在本发明中,采用conv-lstm-unet网络进行噪声预测。给定原始动态数据其中,k表示特征的数量,l表示序列的长度,其由滑动窗口的大小决定。在时间维度上,样本s1至sl间存在着时间依赖性,同时,由于过程的外部扰动,变量间呈现出非线性关系。lstm因其门控单元结构可以解决时间数据的依赖性和非线性问题。在空间维度上,不同的特征间存在空间依赖关系,如特征1和特征2,特征1和特征3。随着过程的进行,特征间的关系会发生变化,因此,我们采用卷积结构提取不同变量间的动态空间关系。为了捕捉数据不同位置间的依赖关系,采用自注意力机制为不同的特征赋予不同的权重,增加网络的全局建模能力。
37、噪声预测网络conv-lstm-unet属于编码器-解码器结构,编码器由不同的下采样模块构成,以降低特征图的空间大小,同时提取数据的低层次特征。解码器结构与编码器相反,其将编码器压缩的特征逐渐恢复。此外,在conv-lstm-unet的解码器模块中引入跳跃连接(skip connections)结构,将编码器中的浅层特征和解码器中的深层特征进行融合。进一步,在编码器中加入时间嵌入模块,将时间步信息嵌入到每个输入数据的通道中。该嵌入的向量是正弦和余弦函数的组合。通过引入时间嵌入模块,conv-lstm-unet网络能够有效学习时间序列数据的结构,并在生成数据时保持时间上的连续性。总的而言,conv-lstm-unet网络同时捕捉了数据在时间和空间上的特性,在扩散模型的反向过程中被用来指导数据生成过程,以生成高质量的时序数据。
38、进一步,步骤3.3的具体过程如下:
39、当噪声预测网络训练完成,我们可以预测反向过程任何阶段的数据,在t步的反向过程中,第(t-1)步的数据是在第t步数据的基础上根据以下公式计算得到:
40、
41、其中,当n=n,...,2时当n=1时,z=0。
42、重复采样步骤t次,得到最终的生成数据sgen,将原始有限动态训练数据与生成数据合并,组成新的训练集snew={strain∪sgen}={xnew,ynew}。
43、进一步的,所述步骤(4)的具体过程如下:
44、考虑到lstm模型在动态时序数据建模方面的优越性能,根据扩充后的新训练数据集snew构建lstm模型,并预测测试集的关键质量变量值。
45、发明的有益效果主要表现在:本发明提出一种基于时序扩散概率模型的增强软测量方法,该方法在噪声预测网络conv-lstm-unet中融入了lstm单元和一维卷积结构,因此能够同时捕捉动态数据的时间特性和空间特性,可以生成与原始样本相似的时序数据,进一步基于扩充后训练集构建模型,提高在测试集上预测精度。
- 还没有人留言评论。精彩留言会获得点赞!