一种基于深度学习的藏汉翻译系统
本发明涉及藏汉翻译,具体为一种基于深度学习的藏汉翻译系统。
背景技术:
1、随着机械翻译的进一步发展,越来越多的方言形式的翻译,藏语,属汉藏语系藏缅语族藏语支。分布在中华人民共和国西藏自治区和青海、四川甘孜藏族自治州、阿坝藏族羌族自治州以及甘肃甘南藏族自治州与云南迪庆藏族自治州5个地区,不丹、印度、尼泊尔、巴基斯坦四个国家的部分地区也有人说藏语,因此藏语作为一种被经常使用过的语音,因此需要进一步地研发对藏语的翻译应用系统;
2、参阅公开号为“cn104239294b”的“藏汉翻译系统的多策略藏语长句切分方法”可知,该专利接收藏语长句,对每一成分逐个判断,若成分为数字或特殊符号、逗号但无源文模式匹配成功且模式条件满足的逗号切分实例、单词但在特征词索引表中检索不到,或者检索到然而无源文模式匹配成功且模式条件满足的特征词切分实例,则继续判断下一成分,否则记录切分点,切分点之前成分作为切分子句送出,继续判断余下第一个成分。在判断各成分之前先要判断指针当前是否指向空,若是则将余下成分送出结束,否则读取指针当前指向的成分;
3、但是在使用该专利的过程中,申请人发现该专利存在以下问题:由于分段式的翻译,导致整体的翻译过程较慢,且不便于进行对语序情绪的辅助理解,导致功能性和效果较差;
4、因此需要对以上问题提出一种新的解决方案。
技术实现思路
1、本发明的目的在于提供一种基于深度学习的藏汉翻译系统,以解决现有的问题:由于分段式的翻译,导致整体的翻译过程较慢,且不便于进行对语序情绪的辅助理解,导致功能性和效果较差。
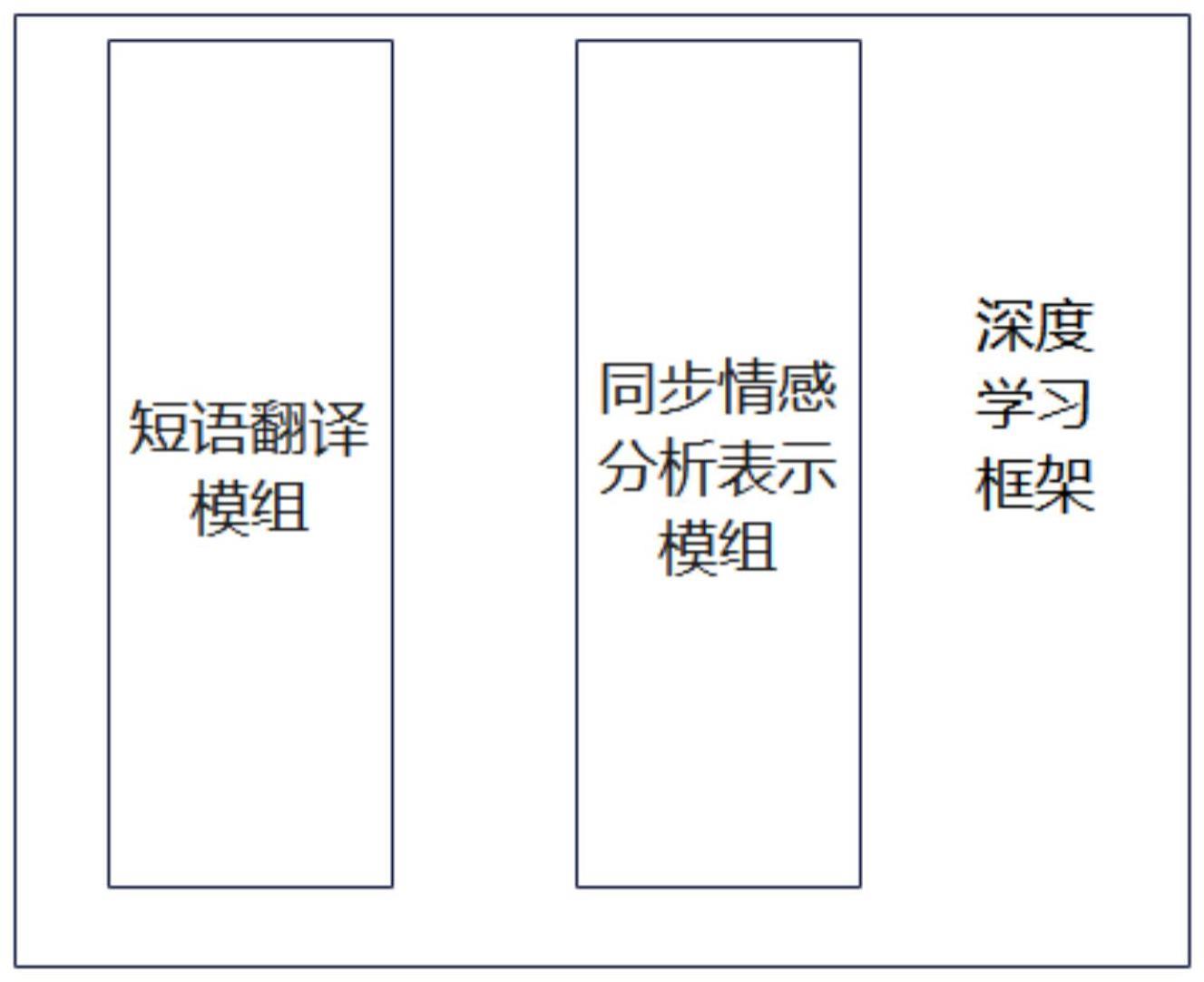
2、为实现上述目的,本发明提供如下技术方案:一种基于深度学习的藏汉翻译系统,至少包括深度学习框架,所述深度学习框架上搭建有短语翻译模组和同步情感分析表示模组,所述短语翻译模组用于对语言进行便捷翻译,所述同步情感分析表示模组用于在翻译过程中分析语句情感,所述深度学习框架至少包括序列到序列模型、注意力机制和词嵌入模块,所述序列到序列模型将输入的序列转换为输出的序列的一种模型,用于基于上下文信息进行翻译,所述注意力机制是一种权重分配机制,允许模型将注意力集中于输入序列中的某些位置,以便更好地对其进行翻译,所述词嵌入是一种将文本中的单词转换为向量表示的方法,所述深度学习框架的训练方法至少包括教师强制方法和微调应用方法。
3、优选的,所述序列到序列模型包括两个相互独立的长短时记忆网络,所述两个相互独立的长短时记忆网络分别用于编码输入序列和解码输出序列,在编码器中,每个单词都会转换成一个向量表示,因此整个序列可以表示为一个向量序列,在解码器中,每个输出单词都由之前的单词预测出来;
4、所述注意力机制用于根据上一个输出单词和编码器中的每个输入单词计算一个权重,权重会被用于加权平均和编码器输出,以计算解码器对下一个单词的预测;
5、所述词嵌入为将每个单词构成一个向量,其中每个维度代表语义特性,允许计算机将单词之间的语义相似性建模为向量空间中的距离。
6、优选的,所述短语翻译模组至少包括翻译模型训练工具、语言模型训练工具、词语对齐工具、藏汉机器翻译自动评测工具、搭建的藏汉在线翻译系统工具、藏汉双语对齐语料库、藏汉双语语料预处理、训练藏汉短语翻译模型、giza++进行双语对齐和构建藏汉解码器。
7、优选的,所述翻译模型训练工具至少包括seq2seq模型,所述语言模型训练工具至少包括词嵌入训练和注意力机制的复配应用,所述构建藏汉解码器至少包括循环神经网络和卷积神经网络。
8、优选地,所述同步情感分析表示模组至少包括tsd词典的构建,;
9、sstsd的构建,主要采用合并去重算法,sstsd词典包含基础情感词、程度词、否定词、转折词、双重否定词、藏文停用词
10、优选地,所述同步情感分析表示模组的算法至少包括:
11、input:
12、setmicro-blogpositivescore:positive
13、setmicro-blognegativescore:negative
14、setdegreewordwi:={most,very,more,-ish,insufficiently,
15、over};
16、setdegreelevelw_degree(wa):=12,1.75,1.25,0.75,
17、0.5,1.5};
18、setmicro-blognumberm:={m,,m2,…,ml;
19、output:
20、micro-blogscores:scores(k);
21、foreachmdo
22、forwordinm
23、if(wordinstop_word)
24、deleteword;
25、elseif(wordinturn_word)
26、m,=word.next;
27、elseif(wordinpos_word)
28、positive=w_emotion_resuit(i);
29、if(word.pre==wi)
30、positive=w_emotion_resuit(i)*w_degree(wa);
31、elseif(wordinneg_word)
32、negative=w_emotion_resuit(j);
33、if(word.pre==wi)
34、negative=w_emotion_resuit(j)*w_degree(wa);
35、elseif(word.pre==deny_word)
36、positive=(-1)*positive;
37、negative=(-1)*negative;
38、elseif(word.pre==double-deny_word)
39、positive=2*positive;
40、negative=2*negative;
41、foreachscores(k)do
42、scores=positive-negative;
43、end
44、end
45、end。
46、与现有技术相比,本发明的有益效果是:
47、本发明通过在深度学习的框架基础上搭建藏汉翻译系统,从而便于对藏族短语进行便捷及时的汉化,且便于对藏族短语中的情感进行对应的捕捉分析,便于进一步地构成多元化应用的翻译系统,提高适用范围和功能性。
技术特征:
1.一种基于深度学习的藏汉翻译系统,其特征在于:至少包括深度学习框架,所述深度学习框架上搭建有短语翻译模组和同步情感分析表示模组,所述短语翻译模组用于对语言进行便捷翻译,所述同步情感分析表示模组用于在翻译过程中分析语句情感,所述深度学习框架至少包括序列到序列模型、注意力机制和词嵌入模块,所述序列到序列模型将输入的序列转换为输出的序列的一种模型,用于基于上下文信息进行翻译,所述注意力机制是一种权重分配机制,允许模型将注意力集中于输入序列中的某些位置,以便更好地对其进行翻译,所述词嵌入是一种将文本中的单词转换为向量表示的方法,所述深度学习框架的训练方法至少包括教师强制方法和微调应用方法。
2.根据权利要求1所述的一种基于深度学习的藏汉翻译系统,其特征在于:所述序列到序列模型包括两个相互独立的长短时记忆网络,所述两个相互独立的长短时记忆网络分别用于编码输入序列和解码输出序列,在编码器中,每个单词都会转换成一个向量表示,因此整个序列可以表示为一个向量序列,在解码器中,每个输出单词都由之前的单词预测出来;
3.根据权利要求1所述的一种基于深度学习的藏汉翻译系统,其特征在于:所述短语翻译模组至少包括翻译模型训练工具、语言模型训练工具、词语对齐工具、藏汉机器翻译自动评测工具、搭建的藏汉在线翻译系统工具、藏汉双语对齐语料库、藏汉双语语料预处理、训练藏汉短语翻译模型、giza++进行双语对齐和构建藏汉解码器。
4.根据权利要求3所述的一种基于深度学习的藏汉翻译系统,其特征在于:所述翻译模型训练工具至少包括seq2seq模型,所述语言模型训练工具至少包括词嵌入训练和注意力机制的复配应用,所述构建藏汉解码器至少包括循环神经网络和卷积神经网络。
5.根据权利要求1所述的一种基于深度学习的藏汉翻译系统,其特征在于:所述同步情感分析表示模组至少包括tsd词典的构建,所述tsd词典包含基础情感词、程度词、否定词、转折词;
6.根据权利要求1所述的一种基于深度学习的藏汉翻译系统,其特征在于:所述同步情感分析表示模组的算法至少包括:
技术总结
本发明公开了一种基于深度学习的藏汉翻译系统,涉及藏汉翻译技术领域。本发明至少包括深度学习框架,深度学习框架上搭建有短语翻译模组和同步情感分析表示模组,短语翻译模组用于对语言进行便捷翻译,同步情感分析表示模组用于在翻译过程中分析语句情感,深度学习框架至少包括序列到序列模型、注意力机制和词嵌入模块。本发明通过在深度学习的框架基础上搭建藏汉翻译系统,从而便于对藏族短语进行便捷及时地汉化,且便于对藏族短语中的情感进行对应的捕捉分析,便于进一步地构成多元化应用的翻译系统,提高适用范围和功能性。
技术研发人员:朱云飞,达瓦次仁,岳昕哲,李旭昌,袁雨琛
受保护的技术使用者:西藏大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!