一种基于数据分析的最优资源分配方法与流程
本发明涉及资源分配,具体而言,涉及一种基于数据分析的最优资源分配方法。
背景技术:
1、使用多资源调度器共同管理所有的资源,进而实现实时的资源分配与动态调整。其主要目的是为了管理存储和计算资源,以减低工程师对基础设施的维护难度,并形成资源共享,提高资源的整体利用率,同时对资源进行统一管理和统一监控以维护安全。
2、针对新型电力系统对优化资源调度的需求,提升资源利用率,支持电力场景的示范应用,提升在信创等体系下的云边协同能力;研究云边统一运维监控体系,全方位监管业务系统各个层面的运行状态和资源容量情况,实现云上业务的监控全覆盖,提升资源管理、系统监控和运行维护的能力。
3、但是,现有的技术在进行资源分配处理的时候,仅仅是实现对资源进行分配处理,将任务分配下去后,就不在管理和过问,静待边缘云或者集群系统进行计算处理,得到最后的结果,造成计算过程复杂,以及资源分配过度或者是资源分配不够,不能够有效的实现对自动扩缩调节,造成资源的分配无法有效的达到按需分配,精准化控制等问题。
技术实现思路
1、为了弥补以上不足,本发明提供了一种基于数据分析的最优资源分配方法,用于解决上述提出的现有的技术在进行资源分配处理的时候,仅仅是实现对资源进行分配处理,将任务分配下去后,就不在管理和过问,静待边缘云或者集群系统进行计算处理,得到最后的结果,造成计算过程复杂,以及资源分配过度或者是资源分配不够,不能够有效的实现对自动扩缩调节,造成资源的分配无法有效的达到按需分配,精准化控制等问题。
2、本发明是这样实现的:
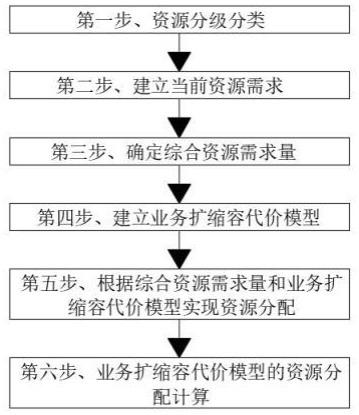
3、一种基于数据分析的最优资源分配方法,包括有以下步骤:
4、s1、资源分级分类:对各个异构网络内部的资源进行分级分类,为客体资源的库、表以及字段要素打上标签,理清全网资源的属性,建立客体数据资源目录,汇聚关联各类资源属性生成资源视图;
5、s2、建立当前资源需求:基于长短期记忆网络模型实现对用户未来任务量及资源需求进行精准的预测处理,即通过用户未来任务量实现对资源需求进行预测处理,实现对当前资源需求的容量进行计算出来;
6、s3、确定综合资源需求量:基于数据挖掘技术实现用户历史资源需求量的规律自动发现,并结合用户当前资源需求的情况,再基于加权平均算法实现综合资源需求量的评估和计算;
7、s4、建立业务扩缩容代价模型:面向业务实际负载动态变化场景,基于数据分析方法实现最合理的资源分配策略推荐,即通过造成的资源碎片化代价、云平台管理实例数代价和扩所容代价三个纬度,建立业务扩缩容代价模型;
8、s5、根据综合资源需求量和业务扩缩容代价模型实现资源分配:将综合资源需求量输入到业务扩缩容代价模型中,基于横向扩展的弹性扩缩容技术实现资源的动态调整,实现真正的按需分配;
9、s6、业务扩缩容代价模型的资源分配计算:基于资源分配经验初始化分配推荐值,并基于网格搜索生成所有可能的分配推荐值,将各个分配推荐值和业务实际负载曲线作为代价模拟仿真系统输入,得到每种分配推荐值下对应的扩缩容代价值,以扩缩容代价最小为目标函数,寻找全局最优的分配推荐值作为最终业务的最优资源分配推荐,实现自动化、智能化的最优资源分配推荐。
10、本发明的一种实施例中,所述s1中的资源分级分类以元数据的形式管理资源分级分类的标签,基于各个网络的各种元数据,形成统一的资源视图,定义各网络元数据管理要求、开发和维护网络元数据标准、建设元数据管理工具平台支撑数据分级分类活动、整合元数据形成资源视图、基于资源视图制定数据访问策略、进行持续的元数据跟踪和分析,元数据一旦变更,驱动访问策略就进行动态调整。
11、本发明的一种实施例中,所述s2中的长短期记忆网络模型是基于lstm网络进行建立,并且通过bp神经网络实现对未来任务量进行计算确定,再通过关联分析技术的贝叶斯定理实现对未来任务量和资源需求之间进行映射处理,对未来任务量和资源需求之间建立关系。
12、本发明的一种实施例中,所述未来任务量确定的资源需求既是当前资源需求,所述s3中的综合资源需求量既是当前资源需求和历史资源需求量之间通过加权平均算法进行计算得出,所述加权平均算法即将各数值乘以相应的权数,然后加总求和得到总体值,再除以总的单位数。
13、本发明的一种实施例中,所述加权平均算法的计算公式如下:
14、假设,当前资源需求表示为x,历史资源需求表示为y,并且权分别是w和v,则公式为:
15、。
16、本发明的一种实施例中,所述s3中的数据挖掘技术是从大量的数据中,提取隐藏在其中的,事先不知道的、但潜在有用的信息的过程,所述数据挖掘技术包括有数据清理、数据集成、数据选择、数据变换、数据挖掘、模式评估和知识表示,其中所述数据清理用于消除噪声和不一致的数据,所述数据集成用于将多种数据源组合在一起,所述数据选择用于从数据库中提取与分析任务相关的数据,所述数据变换通过汇总或聚集操作,把数据变换和统一成适合挖掘的形式,所述数据挖掘使用智能方法提取数据模式,所述模式评估识别代表知识的真正有趣的模式,所述知识表示使用可视化和知识表示技术,向用户提供挖掘的知识。
17、本发明的一种实施例中,所述数据挖掘技术采用的是循环神经网络,所述循环神经网络用于将当前资源需求和历史资源需求相结合,包含了信息融合的思想,当前资源需求反映了每个需求的独特特征,历史资源需求反映了历史需求中的共同特征;
18、所述循环神经网络的计算公式如下:
19、;
20、式中:u是输入层到隐藏层的参数矩阵,s是隐藏层的向量,v是隐藏层到输出层的参数矩阵,代表t时刻的输出,代表t时刻的隐藏层的值,w其实是每个时间点之间的权重矩阵,x是一个向量,是输出层激活函数,是隐藏层激活函数。
21、本发明的一种实施例中,所述s4中的业务扩缩容代价模型采用的是横向扩展的弹性扩缩容技术,且横向扩展也叫水平扩展,用更多的节点支撑更大的请求,即多增几台api服务器,实现对资源进行分配处理。
22、本发明的一种实施例中,所述s4中的数据分析方法采用的是决策树算法,所述决策树算法是根据信息增益来进行特征选择的,信息增益定义为:
23、,其中,其中d为总的样本,a为属性,v为在属性a中的v类样本,信息增益越大,表明该属性对分类的相关性越大,ent()表示信息熵,公式如下:,其中,k表示在样本d中的第k类样本,pk表示第k类样本所占样本总体的概率,类比于现实中的熵,理解为信息熵越小,表明分配推荐值越高。
24、本发明的一种实施例中,所述s6中的最优资源分配推荐采用的是粒子群算法,搜索最适方法方式进行分析处理;
25、所述粒子群算法的公式如下:
26、,
27、第d+1次的迭代,
28、;
29、式中:
30、n:粒子个数,
31、:粒子的一个分配学习因子,也称为分配加速因子,
32、:粒子的全部的分配学习因子,也称为全部的分配加速因子,
33、:速度的惯性权重,
34、:第d次迭代时,第i个粒子的速度,
35、:第d次迭代时,第i个粒子所在的位置,
36、:在位置x时的适应度值,
37、:到第d次迭代为止,第i个粒子经过的最好的位置,
38、:到第d次迭代为止,所有粒子经过的最好的位置。
39、本发明的有益效果是:
40、本发明在使用的时候,基于数据分析方法实现最合理的资源分配策略推荐,综合考虑单个系统实例造成的资源碎片化代价、云平台管理实例数代价和扩所容代价三个纬度,建立业务扩缩容代价模型,基于资源分配经验初始化分配推荐值,以扩缩容代代价最小为目标函数,寻找全局最优的分配推荐值作为最终业务的最优资源分配推荐,实现自动化、智能化的最优资源分配推荐,研究基于用户历史信息和当前资源需求情况的资源动态调整技术,即基于数据挖掘技术实现用户历史规律的自动发现,并结合用户当前资源需求情况,基于加权平均实现综合资源需求量的评估和计算,并基于横向扩展的弹性扩缩容技术实现资源的动态调整,实现真正的按需分配。
- 还没有人留言评论。精彩留言会获得点赞!