一种有效的软件需求可跟踪性链接恢复的机器学习方法
本发明属于计算机技术软件工程需求跟踪领域,尤其涉及一种有效的软件需求可跟踪性链接恢复的机器学习方法。
背景技术:
1、软件系统通常由各种各样的软件制品组成,例如需求说明、设计文档、用例、代码、错误报告和测试用例。软件需求跟踪试图发现这些软件制品之间的关系。在不同的制品之间建立可跟踪性链接,使得需求文档到实现软件制品的映射成为可能,这扮演着重要的角色。用例和源代码是软件开发过程中常见且重要的软件制品,工程师通常关注用例和源代码之间的可跟踪性链接。在规范的软件开发过程中,需要在整个系统生命周期中创建和维护可跟踪性链接。遗憾的是,维护可跟踪性链接通常是手工的,这既耗时又容易出错。因此,由于软件开发中的时间压力,这种可跟踪性链接在实践中通常是缺失的。尽管在自动化需求跟踪方面已经做了大量的研究,但是自动化技术经常受到噪声的影响,产生大量的误报环节,导致精度低。
2、近年来,研究人员提出了各种自动化创建和维护跟踪链接任务的解决方案,包括信息检索和机器学习。信息检索方法是计算需求文本与代码文本之间的相似度,依赖预先设定的阈值筛选软件需求所跟踪链接,大大节省了人力成本,但是性能往往不能达到预期。机器学习方法可以更有效地通过提取和构建软件需求与代码文件的文本特征,以及训练有效分类器预测软件需求和代码文件之间的跟踪链接,并达到比信息检索方法更好的性能。然而,这些方法都是依赖于软件文件的丰富和高质量的文本信息才能获得更好的效果。
3、目前现状是针对代码文件用到的更多代码信息是类名,方法名,api序列,代码块之间的结构关系等,一部分技术也使用到了注释的信息,但是对注释特征的使用大多是简单的关键字提取等,并没有对注释信息进行深入的挖掘和利用。如何有效的利用注释信息,将更多的注释信息利用在代码语料中来训练模型没有考虑,如何更加有效的利用注释,同时结合其他代码特征进行丰富代码语料库,是提高模型预测准确率所迫切需要的。此外,在需求跟踪领域使用的机器学习模型,虽然通过优化算法和调节算法参数可以比原有的单一算法模型具有更高的精度,泛化能力也有所增强。但由软件代码文件的数据相对复杂,单一的预测算法模型有自身的局限性,存在泛化能力不强的问题。因此,为了提高需求跟踪链接恢的准确率,解决这些问题成为了研究的重点。
技术实现思路
1、有鉴于此,本发明提供了一种有效的软件需求可跟踪性链接恢复的机器学习方法,目的在于,提高代码文件信息的利用率,减小代码语料利用率不足而造成负面的影响,提高软件需求可跟踪性链接恢复的准确率,降低恢复成本,减少人工,提高自动化程度和项目的工作效率。
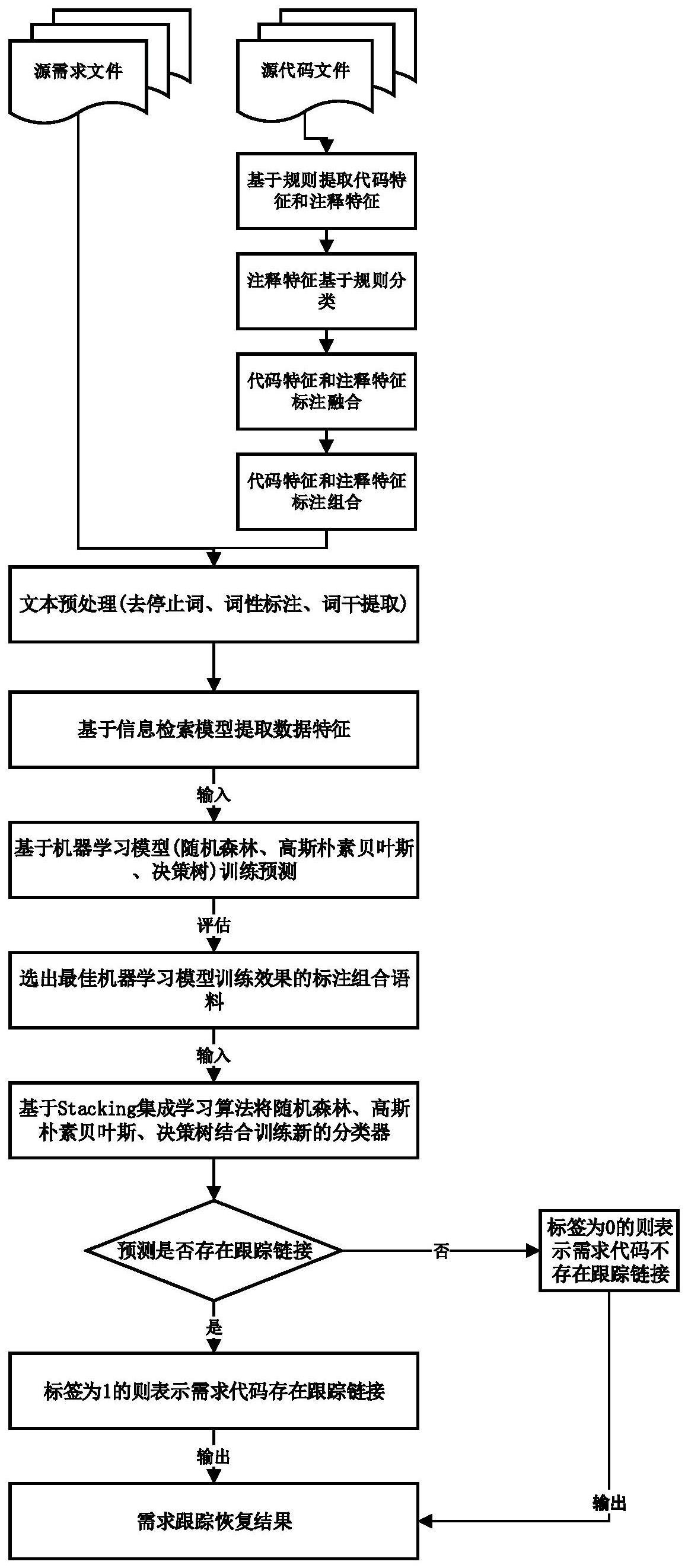
2、为实现上述目的,本发明提供了一种有效的软件需求可跟踪性链接恢复的机器学习方法,包括以下步骤:
3、步骤1,将待确定跟踪关系代码文件按规则对代码特征和注释特征进行分类提取并标注融合,然后按标注维度对描述代码语料进行组合;
4、步骤2,将组合的不同描述代码语料分别与需求语料进行预处理,并基于信息检索中使用最多的若干个模型对预处理后的数据进行特征提取;
5、步骤3,输入不同的特征数据对基于机器学习需求跟踪领域中使用最多的若干个模型进行训练预测评估,选出最佳效果的描述代码语料组合;
6、步骤4,利用stacking集成算法将机器学习模型结合起来并用最佳效果的特征数据训练出新的分类器进行预测。
7、进一步的,步骤1的具体实现方式如下;
8、步骤11,利用python工具的javalang库解析java源代码为抽象语法树,并用walk方式遍历获取抽象语法树节点上的信息,对于代码类层面,提取了包名,变量名,类名,方法名,方法参数,方法返回值,api序列作为代码代码特征;
9、步骤12,利用python工具的javalang库解析java源代码为抽象语法树,并用walk方式遍历获取抽象语法树节点上的注释信息,然后将提取的注释特征按功能注释,使用注释,结构注释,开发注释和异常注释这五类进行分类;
10、步骤13,根据步骤11中获取的代码特征和步骤12中获取的注释特征的功能属性生成多维代码标注;
11、步骤14,把根据步骤13形成的多维代码标注融合的语料,按标注维度进行组合。
12、进一步的,步骤13中的多维代码标注从四个方面描述代码,分别为功能标注、使用标注、方法体标注、开发标注,多维代码标注的内容由代码特征和注释特征融合而成,功能标注包括包名、变量名、方法名和功能注释,使用标注包括方法参数、方法返回值和使用注释,方法体标注包括调用序列、异常注释和结构注释,开发标注包括开发注释;
13、进一步的,步骤2中预处理的具体实现方式如下;
14、a)删除字符:对所有需求文件和源代码文件执行标记化操作,删除非字母字符、标点符号、停用词、无意义的术语;b)分词:从需求文件和源代码文件中的标识符中提取有意义的单词,标识符是连接两个或多个单词或缩写或任何其他分隔符的复合词,采用骆驼拼写法拆分复合词;c)翻译:当需求和源代码包含非英语单词时,将需求和源代码的文本内容翻译成英语;然后,用信息检索模型vsm,lsi,lda和js通过提取需求和代码文档的语料中的术语出现信息来将软件文档索引入文档空间,提取的信息存储在m×n矩阵中,称为term-by-document矩阵,其中m是文档中出现的所有术语的数量,n是存储库中文档的数量,该矩阵的元素aij表示第j个文档中的第i个术语的权重,即相关性,最后通过计算term-by-document矩阵中两个软件文档向量之间的文本相似度得到特征值。
15、进一步的,步骤3的具体实现方式如下;
16、将步骤2中得到的不同语料组合的特征数据,输入到基于机器学习需求跟踪领域中使用最多的随机森林(random forest,rf),决策树(decision tree,dr)和高斯朴素贝叶斯(gaussian naive bayes,gnb)三个机器学习模型进行训练预测,得到预测结果用precision、recall、f1-score三个评估指标评估,若某个语料组合对应的三个预测效果都优于其他语料组合,则将保留此代码语料组合。
17、进一步的,步骤4的具体实现方式如下;
18、步骤41,从步骤3中获取到效果最佳的特征数据集;
19、步骤42,选择基于机器学习的需求跟踪领域里使用最多的decision tree,randomforest和gaussian naive bayes三个机器学习模型作为初级学习器,并通过sklearn库中的网格搜索方法选取个体学习器的最优参数;
20、步骤43,将步骤41中的特征数据集以一定比例切分为训练集y和测试集x,并将处理好的训练集平均分为5份数据集yi,i∈{1,2,3,4,5};
21、步骤44,在第一层预测模型中,将3个初级学习器分别采用5折交叉验证进行训练;
22、步骤45,为了更好地得到初级学习器中的有效信息,基于初级学习器中的模型的预测的结果效果不同,对第一层中每个学习器设置不同的权重;
23、步骤46,基于步骤45给第一层三个学习器设置权重后,然后对3个初级学习器进行训练及预测,完成后会得到和两个新的矩阵数据集(y1,,y2,,y3,)和(x1,,x2,,x3,),在第二层,次级学习器多元线性回归(mlr)以矩阵y,作为训练集,矩阵x,作为测试集,以其为基础进行训练,得到最终预测结果,即需求跟踪链接恢复结果,0表示不存在跟踪链接,1表示存在跟踪链接。
24、进一步的,步骤43中,针对decision tree,每次交叉验证包含两个过程:首先用其中的4份数据集作为decision tree训练集进行训练,剩下的1份作为decision tree模型预测的测试集,得到预测数据集yi,i∈{1,2,3,4,5},将其整合为1列记为y1,;然后再由上一步基于4份数据集训练的decision tree模型对测试集x进行预测,得到预测数据集xi,再对5次预测的结果xi按行相加取均值,得到数据集x1,。
25、进一步的,步骤45中权重值具体计算公式为:
26、
27、其中,dj为第j个模型的误差平方和,即对误差平方和小的模型赋以高权重,j是模型个数;
28、
29、其中,n为预测的跟踪链接总个数,xt表示真实值,表示预测值。
30、与现有技术相比,本发明具有如下有益效果:
31、1、本发明通过对代码特征和注释特征进行分类提取并标注融合,然后按标注维度对代码语料进行组合,对组合的不同来语料训练模型,通过比较效果获取有效的代码语料库,减小代码语料利用率不足而造成负面的影响。
32、2、本发明为提高机器模型的泛化能力,充分发挥个体学习器的优势,本文采用stacking集成方法,对基于机器学习的需求跟踪领域里使用最多随机森林,决策树和高斯朴素贝叶斯3个异质学习器进行非线性组合,构建两层stacking集成学习模型,有效的提高了软件需求可跟踪性链接恢复的准确率,降低恢复成本,减少人工,提高自动化程度和项目的工作效率。
33、3、本发明在构建两层stacking集成学习模型中,由于初级学习器中的模型的性能各有差异,为了减少这种差异对预测结果带来的影响,则设置权重值wj来减小影响,以此提高预测的精准度。
- 还没有人留言评论。精彩留言会获得点赞!