基于文本和结构化数据的用户意向识别和量化方法与流程
本发明涉及数据挖掘,尤其涉及基于文本和结构化数据的用户意向识别和量化方法。
背景技术:
1、针对一些语音或文本的服务场景,例如电话、语音、微信、app聊天等,用户可能存在不同的需求,例如售前、售后、购买、投诉等。或者更具体的,在电话或微信销售场景中,用户可能对不同的产品和服务,有不同的购买需求。以多样产品服务的销售为例,在营销中为了更好地促成交易发生,对于用户的实时需求判定和实时意向度判定有较高的业务场景需求。而当前大多数电话销售场景,都无法支持用户的意向分析和预测,或者无法精准识别用户的关注点和意向度。
技术实现思路
1、本发明的目的在于提供一种语音或文本的服务场景中,用户意向类别和意向度等级实时判断的解决方案。具体的,通过对用户可能感兴趣的意向进行实时判断,并给出在对应意向类别中的意向度等级的实时预测。该功能不仅可以更精准地把握客户需求和意向的行为定性预测,给出对应意向下的可能性定量预测,且进一步形成用户行为倾向的动态监测结果。
2、为实现上述目的,本发明通过以下技术方案予以实现。
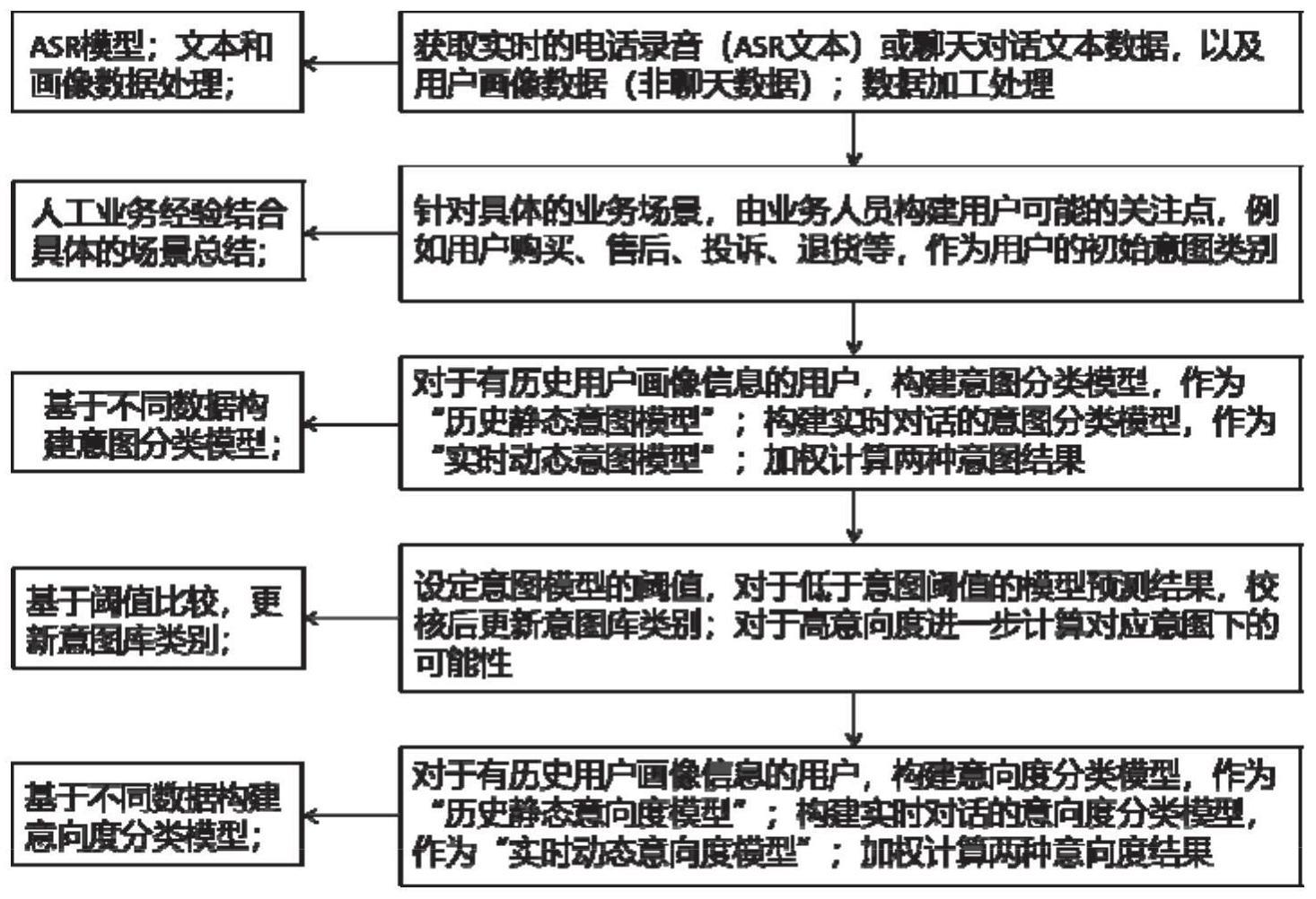
3、基于文本和结构化数据的用户意向识别和量化方法,包括以下步骤:
4、获取用户社交中的文本数据,以及用户画像构成的结构化数据;
5、根据业务场景,提取用户可能的潜在关注点,并总结概括,形成该业务场景下的初始意向类别;
6、利用结构化数据,构建静态意向分类模型,同时利用文本数据构建实时动态意向分类模型,两者加权获得定性的初始意向分类;
7、初始意向类别加权后的初始意向识别阈值大于等于设定阈值时,则进行意向度级别判断;
8、分别利用结构化数据和文本数据构建静态意向度分级模型和动态意向度分级模型,两者加权获得定量的意向度分级结果。
9、优选地,所述文本数据包括但不局限于电话录音数据、语音数据、文字文本数据。
10、优选地,还包括语音数据的转换,具体为:选用分段处理,将语音依次经过分帧、加窗、傅里叶变换、分段以及后续处理,使其在设定帧长范围内转换为频域信号,提取有用信号后,再将分段转换为文字的语音合成整体文本。
11、优选地,还包括静态意向分类模型和静态意向度分级模型的构建,具体为:选用决策树模型,将静态数据和用户画像数据形成的数据源分为训练集和验证集,构建模型以形成静态意向分类模型和静态意向度分级模型。
12、优选地,还包括动态意向分类模型和动态意向度分级模型的构建,具体为:
13、选取深度学习神经网络构建模型,用来实现文本向量化,并自动提取文本数据中的数据特征,最终通过构建文本分类模型,以形成动态意向分类模型和动态意向度分级模型。
14、优选地,所述初始意向分类和意向度分级结果获得中,所述加权权重的比例为0-1。
15、优选地,静态和动态意向类别模型预测结果加权后,其阈值小于设定阈值时,则样本将存储更新到意向库中,定期经由业务人员提炼和确定后,再次更新模型会扩充意向类别,以覆盖更全面。
16、优选地,所述定量的意向度分级结果至少包括为高中低三个意向分级。
17、本发明的有益效果如下:
18、1)用户意向的实时预测,实现用户的定性分析;对应意向下的意向度实时预测,实现用户的定量分析。
19、2)对话实时场景实现精准分析用户,有利于辅助实时决策。
20、3)记录用户的行为走势,扩充用户画像的维度。
21、4)自动化识别新的潜在意向,人工辅助扩充意向库。
技术特征:
1.基于文本和结构化数据的用户意向识别和量化方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于文本和结构化数据的用户意向识别和量化方法,其特征在于,所述文本数据包括但不局限于电话录音数据、语音数据、文字文本数据。
3.根据权利要求2所述的基于文本和结构化数据的用户意向识别和量化方法,其特征在于,还包括语音数据的转换,具体为:选用分段处理,将语音依次经过分帧、加窗、傅里叶变换、分段以及后续处理,使其在设定帧长范围内转换为频域信号,提取有用信号后,再将分段转换为文字的语音合成整体文本。
4.根据权利要求1所述的基于文本和结构化数据的用户意向识别和量化方法,其特征在于,还包括静态意向分类模型和静态意向度分级模型的构建,具体为:选用决策树模型,将静态数据和用户画像数据形成的数据源分为训练集和验证集,构建模型以形成静态意向分类模型和静态意向度分级模型。
5.根据权利要求1所述的基于文本和结构化数据的用户意向识别和量化方法,其特征在于,还包括动态意向分类模型和动态意向度分级模型的构建,具体为:
6.根据权利要求1所述的基于文本和结构化数据的用户意向识别和量化方法,其特征在于,所述初始意向分类和意向度分级结果获得中,所述加权权重的比例为0-1。
7.根据权利要求1所述的基于文本和结构化数据的用户意向识别和量化方法,其特征在于,静态和动态意向类别模型预测结果加权后,其阈值小于设定阈值时,则样本将存储更新到意向库中,定期经由业务人员提炼和确定后,再次更新模型会扩充意向类别,以覆盖更全面。
8.根据权利要求1所述的基于文本和结构化数据的用户意向识别和量化方法,其特征在于,所述定量的意向度分级结果至少包括为高中低三个意向分级。
技术总结
本发明提供了基于文本和结构化数据的用户意向识别和量化方法,包括以下步骤:获取用户社交中的文本数据,以及用户画像构成的结构化数据;根据业务场景,提取用户可能的潜在关注点,并总结概括,形成该业务场景下的初始意向类别;利用结构化数据,构建静态意向分类模型,同时利用文本数据构建实时动态意向分类模型,两者加权获得定性的初始意向分类;初始意向类别加权后的初始意向识别阈值大于等于设定阈值时,则进行意向度级别判断;分别利用结构化数据和文本数据构建静态意向度分级模型和动态意向度分级模型,两者加权获得定量的意向度分级结果。本发明同时利用文本数据和结构化数据,得到同时具备定性和定量的意向度结果,提高识别准确度。
技术研发人员:谢鹏
受保护的技术使用者:上海众调信息科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!