一种基于LSTM-Attention的污水处理加药量预测方法及系统
本发明属于污水处理领域,具体涉及一种基于lstm-attention的污水处理加药量预测方法及系统。
背景技术:
1、污水处理是一项关键的环境保护工作,其目的是通过去除污水中的有害物质,使水体质量符合规定标准。为了实现有效的污水处理,需要在处理过程中准确预测适当的药剂加药量。然而,由于涉及复杂的生化反应和动态的水质变化,准确预测污水处理中的药剂加药量是一个具有挑战性的问题。传统的污水处理加药量预测方法主要基于统计分析、经验公式或简单的回归模型。这些方法通常基于输入参数之间的线性关系,忽视了时间序列数据中的时序特征和事件关联性。由于污水处理过程的动态性和不确定性,传统方法在预测精度和鲁棒性方面存在一定的局限性。
2、近年来,深度学习技术在时间序列预测领域取得了显著的突破。长短期记忆网络(lstm,long short-term memory)是一种常用的循环神经网络,可以有效地捕捉时间序列数据中的长期依赖关系。lstm模型通过自适应地更新和遗忘信息,能够记住重要的历史数据,并且对未来的预测具有较好的效果。然而,由于污水处理过程中包含的复杂性和多样性,仅仅使用lstm模型可能无法充分利用时间序列数据的特征。
技术实现思路
1、本发明的目的是提供一种基于lstm-attention的污水处理加药量预测方法及系统,实现对未来时刻加药量的精准预测,以帮助企业减少资源浪费,降低成本。
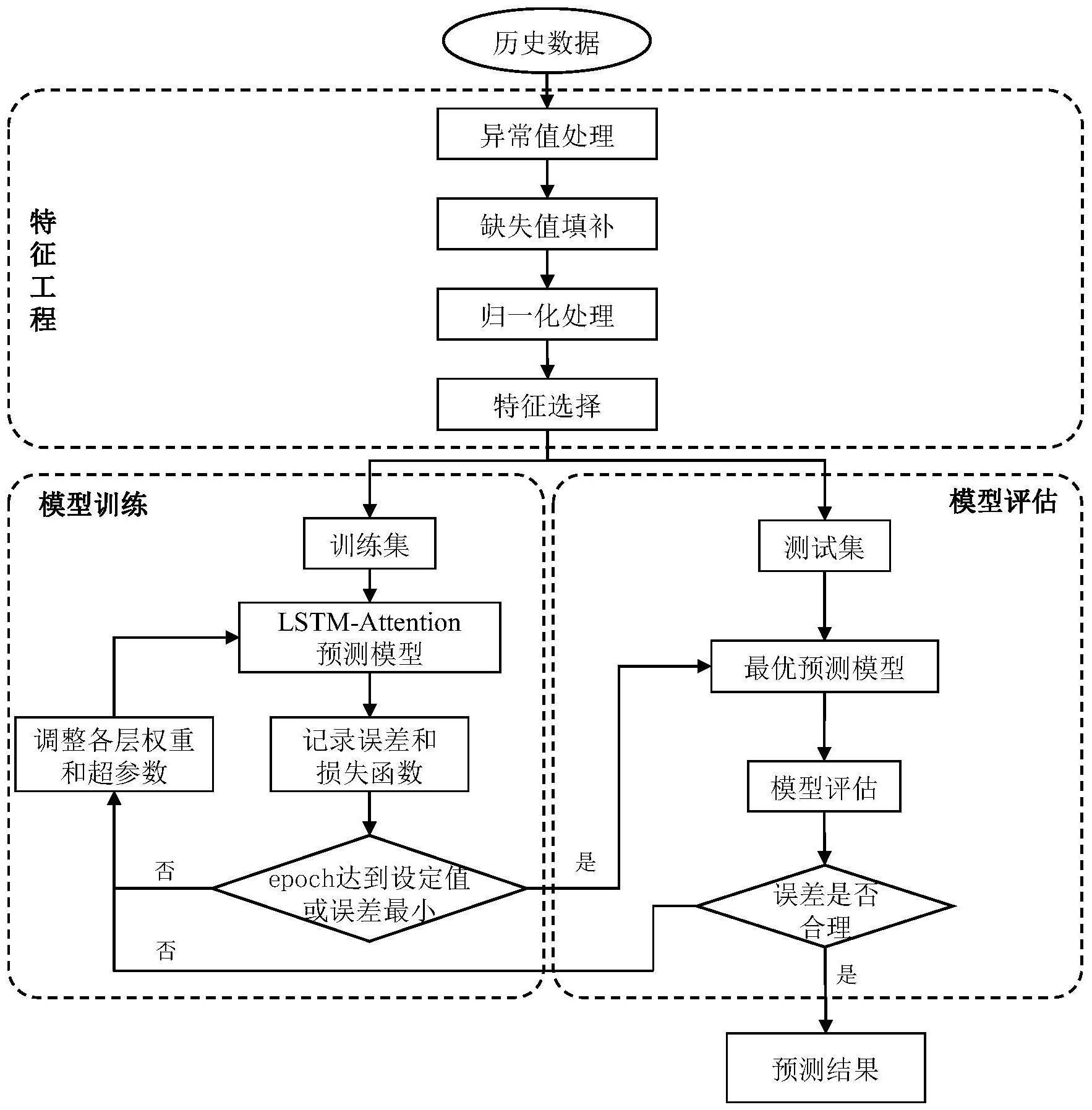
2、一种基于lstm-attention的污水处理加药量预测方法,包括以下步骤:
3、步骤1、数据收集,通过设置在污水处理场地内的边缘计算设备和传感器,在污水处理场地内实时采集污水数据;
4、步骤2、特征工程,对收集到的污水数据进行异常值处理,缺失填充和归一化处理;并计算数据间的相关系数,选择与加药量指标相关性高的数据作为特征;
5、步骤3、构建lstm-attention模型,使用添加了注意力机制的lstm构建模型,lstm-attention模型包括输入层、lstm层、注意力层和输出层;
6、步骤4、模型训练和调参,将处理后的污水数据转化为lstm-attention模型可用数据集,将数据集划分成训练集和测试集,将训练集输入lstm-attention模型进行训练,保存最优模型;将测试集输入最优模型,评估模型性能;
7、步骤5、模型预测,将要预测加药量的污水数据输入训练好的lstm-attention模型中,得到加药量预测结果,为污水处理过程药品的配比和投加剂量提供参考。
8、所述污水数据包括原水浊度、原水导电率、原水溶氧量,进水流量、进水浊度、进水ph,进水温度、回流污泥流量、高密池污泥排放量、高密池污泥液位、实时混凝剂投加量、实时聚合物投加量、澄清水浊度和澄清水ph。
9、所述步骤2中,
10、异常值处理,使用箱线图来对异常值进行检测和定位,并将异常值和0值替换为空,作为缺失值处理;
11、缺失填充,使用knn填补法进行处理;
12、使用pearson相关系数计算数据间的相关系数,选择相关性系数大于0.3的变量作为特征变量。
13、所述异常值处理的箱线图方法为
14、lower=q1-3·iqr
15、upper=q3+3·iqr
16、iqr=q3-q1
17、式中,q1表示所有数值由小到大排列后第25%的数字,即第一分位数,q3则表示所有数值由小到大排列后第75%的数字,即第三分位数;iqr表示四分位距,通常用来表示数据的分布情况;upper和lower分别代表上、下异常边界,若数据大于上界或小于下界,则被认为是异常值;
18、将识别出的异常值和0值替换为空,作为缺失值进行处理;
19、使用knn填补法进行缺失填充的具体流程为
20、
21、
22、式中,xi表示一组数据中的第i个数据,di表示缺失值xi与其他m个正常值之间的欧氏距离,ωi表示缺失值xi最邻近的k个数据点的权值,x0表示缺失值的替换值;
23、归一化处理具体为
24、计算相关系数的具体方法为,
25、式中,表示变量xi和yi之间的相关性系数。
26、所述构建lstm-attention模型的具体方法为,
27、建立基础lstm模型,具体为,
28、ft=σ(ωf·[ht-1,xt]+bf)
29、it=σ(ωi·[ht-1,xt]+bi)
30、
31、
32、ot=σ(ωo·[ht-1,xt]+bo)
33、ht=ot·tanh(ct)
34、σ=1/(1+e-x)
35、式中,ft表示遗忘门机制,表示输入门,表示新输入的信息,ct-1和ct表示前一个时刻和当前时刻的lstm单元的状态,ot表示输出门,ht-1和ht表示上一个单元和当前单元的隐藏状态,xt表示当前时刻lstm的输入向量,σ表示sigmoid函数,tanh表示双曲线正切函数,ω和b分别表示权重参数和偏置项;
36、在lstm模块的输出向量后添加attention机制,
37、et=ω1·tanh(ω2·ht+b)
38、αt=softmax(et)
39、
40、式中,et表示注意力系数的得分函数,ω1和ω2表示权重参数,αt表示归一化后的注意力系数,h表示lstm模块输出向量和注意力系数的加权求和得到的输出序列。
41、所述步骤4中,将处理后的数据按照90%,10%的比例划分为训练集和测试集,并设置时间步长,将二维数据集按照时间步长转换为满足lstm-attention模型输入的监督学习任务的数据集。
42、所述步骤4中,调整的模型超参数为时间步长、lstm单元个数、训练次数和批次大小。
43、所述步骤4中,训练集用于拟合模型,调整各层权重及模型超参数直到误差最小,保存最优模型;测试集用于确定模型参数后,对模型性能进行评价。
44、一种基于lstm-attention模型的污水处理加药量预测系统,包括
45、水质实时监测模块,包括设置在污水处理场地的边缘计算设备和传感器,将实时污水水质数据收集到数据库,系统可对数据进行可视化,并对数据进行预处理和特征选择,将处理后的特征数据传输至云端;
46、lstm-attention模型训练模块,在云端使进行,进行lstm-attention预测模型的训练,根据误差指标进行参数调优,使用多组历史数据定时更新模型,并将模型部署到本地处理器;
47、加药量预测模块,将训练好的模型部署在实际污水处理场地,输入实时污水监测数据对加药量进行预测,得到的加药数据为污水处理过程药品的配比和投加剂量提供参考。
48、本发明的有益效果在于:在lstm预测模型的基础上引入了attention机制,相较于lstm预测模型,能更加精准地对污水处理加药量进行预测。实时的加药量预测结果能够帮助污水处理工程师和操作人员更好地调整和优化处理设备的运行参数,提高污水处理的效率和成效。
49、为污水处理工艺的优化和节能减排提供重要的决策依据。通过准确预测加药量,可以避免过量投放药剂,从而降低处理成本和减少对环境的负面影响。有效的药剂加药量预测有助于提高处理过程的运行效率,减少能源消耗和排放物的产生,实现可持续的污水处理。
- 还没有人留言评论。精彩留言会获得点赞!