一种基于增量编译的Verilog语法分析方法
本发明涉及电子设计自动化,具体涉及一种基于增量编译的verilog语法分析方法。
背景技术:
1、增量编译技术最早起源于软件领域,其技术核心是只编译代码中被修改的部分,以提高编译效率。因此,基于增量编译的程序开发必须考虑编译结果的保存问题,以便下一次编译时使用。在软件开发中,增量编译的结果通常只需要满足一个单一的需求,即生成计算机底层的机器码。因此,软件编程语言中的增量编译技术通常保存与目标代码结构相似的中间结果,也就是同汇编代码接近的.o文件。所以,增量编译中间结果的数据结构往往同目标语言绑定。
2、随着硬件设计规模的扩大,增量编译技术在硬件领域也变得流行。与软件领域增量编译单一的需求不同,硬件语言编译的中间结果具有多种用途,包括仿真、网表生成、形式化验证、时序分析以及不同硬件语言之间代码转换等。然而,现有的硬件语言编译技术都与特定应用密切相关,比如,同仿真有关的增量编译产生的中间代码是适合仿真的中间代码。这样导致所保存的增量编译结果缺少通用性,只能直接满足目标应用需求。例如,在论文《基于层次化设计的verilog hdl增量编译方法》中,提出了一种利用verilog语言层次化特点的增量编译方法。由于该论文的目的是将verilog语言转化为vhdl语言,因此在编译结果的生成上,选择了一种更适合vhdl语言生成的层次结构。但是,这种结构缺乏通用性,无法直接用于逻辑综合等其他开发用途。此外,为了生成这种专门的中间结果,每次编译都需要对代码中的模块进行排序,优先编译底层模块,这在一定程度上影响了编译效率。
技术实现思路
1、发明目的:本发明的目的是提供一种基于增量编译的verilog语法分析方法解决了现有增量编译技术中间语言与目标应用紧密相关的问题;采用以模块为单位的增量编译方法,当出现微小的修改仅限于某个模块时,相较于整个文件的重新编译,仅对发生修改的模块本身及其依赖模块进行重编译能够显著节省重编译所需的时间。
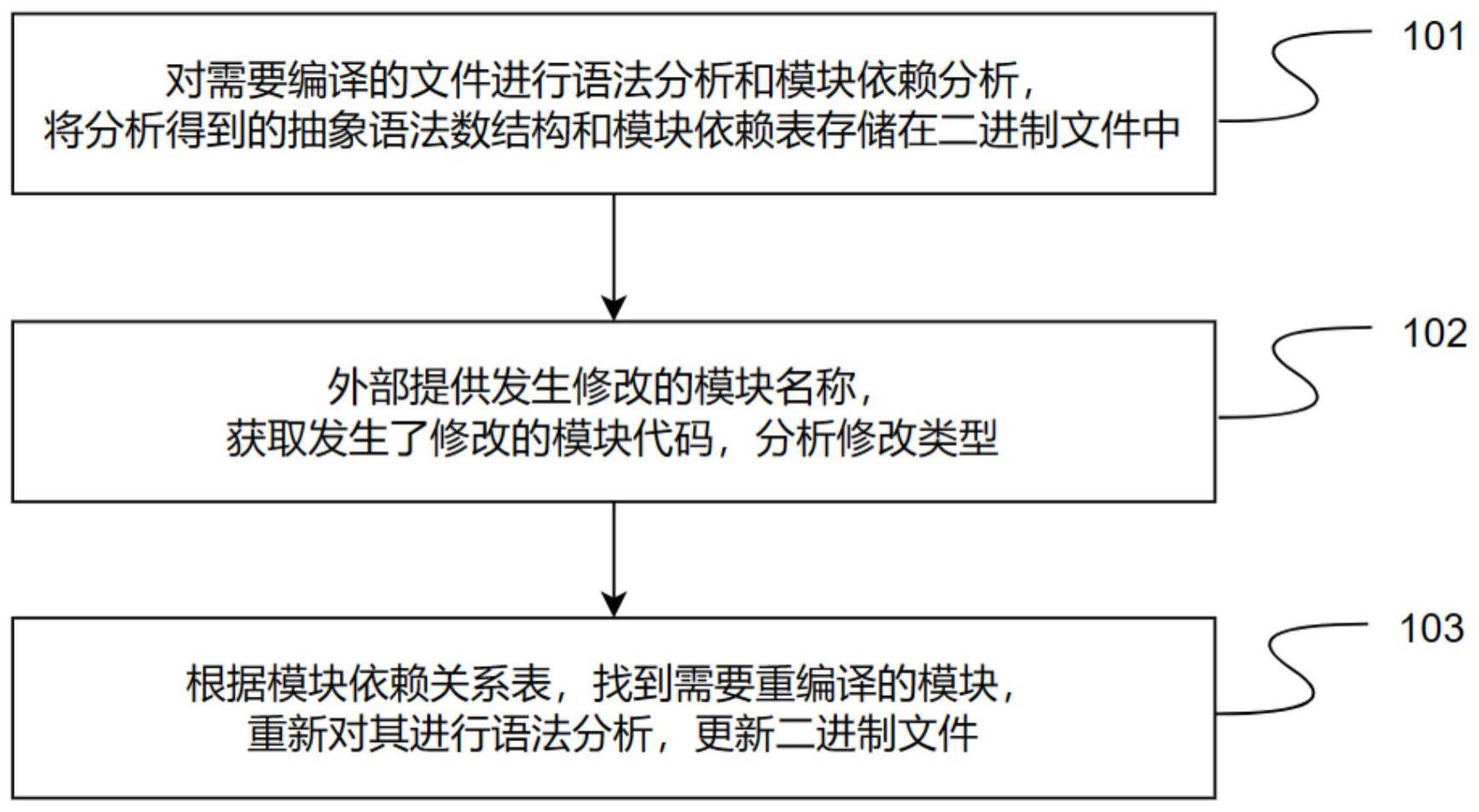
2、技术方案:本发明所述的一种基于增量编译的verilog语法分析方法,包括首次编译和再编译两个阶段;
3、首次编译阶段对verilog文件全部模块进行语法分析,包括以下步骤:
4、(1)获取待分析的verilog文件代码,以模块为单位读入;
5、(2)对读入模块代码进行预处理,主要进行宏定义替换,并删除代码中的宏定义部分;
6、(3)对预处理后的模块代码进行语法分析,得到该模块对应的抽象语法树结构,将抽象语法树结构存储到二进制文件中;
7、(4)分析抽象语法树结构内部的模块依赖关系,获得模块依赖集合,存储到全局模块依赖关系表中;
8、(5)当verilog文件中所有模块都编译完毕,将得到的模块依赖关系表结构写入二进制文件开头。
9、进一步的,再编译阶段对verilog文件中用户指定模块重新进行语法分析,包括以下步骤:
10、(s1)获取用户指定需要重编译的模块名称;
11、(s2)根据用户指定模块名获取相应代码,对其进行语法分析,并分析修改类型,若是外向型修改则根据模块依赖关系得到需要重新进行语法分析的模块集合,否则将当前模块的语法分析结果直接存储到新二进制文件中,其余模块的语法分析结果从步骤(3)二进制文件中获取;
12、(s3)以模块为单位读入代码,判断当前模块是否存在于需要重新进行语法分析的模块集合中,若存在则对该模块重新进行预处理、语法分析以及模块依赖分析操作,并将得到的抽象语法树结构输出到新的二进制文件中,若不存在则从步骤(3)的二进制文件获取当前模块上一次语法分析结构存入新的二进制文件;
13、(s4)当verilog文件中所有模块处理完毕,将更新后的模块依赖关系表结构写入新的二进制文件开头,并删除旧的二进制文件。
14、进一步的,所述步骤(4)包括:分析抽象语法树结构内部是否存在模块实例化相关语句,若存在则向全局模块依赖关系表中添加相应的模块依赖关系,若不存在则继续读取下一模块代码。
15、进一步的,所述步骤(s1)获取用户指定需要重编译的模块名称包括:获取verilog文件首次编译得到的二进制文件头部的模块依赖关系表;根据模块依赖关系表获取依赖用户指定模块的所有模块,这些模块同用户指定模块一同构成需要重新进行语法分析的模块集合。
16、进一步的,所述模块实例化相关语句包括:在当前模块中对其他模块进行实例化;在当前模块中直接使用其他模块名进行层次调用。
17、进一步的,向全局模块依赖关系表中添加相应的模块依赖关系包括:从模块实例化相关语句中获得被实例化的模块名;从全局模块依赖关系表中查找被实例化的模块的依赖模块集合,将当前模块添加到该依赖集合中。
18、进一步的,所述根据模块依赖关系表获取依赖用户指定模块的所有模块具体如下:以用户指定模块名为键,在模块依赖关系表中检索其对应的值,得到依赖用户指定模块的所有模块构成的集合。
19、本发明所述的一种基于增量编译的verilog语法分析系统,包括:
20、输入单元,包括命令行指令读取和待分析的verilog代码读取,其中verilog代码的读取以模块为单位进行;
21、选项处理单元,用于解析命令行指令中的选项参数;
22、预处理单元,用于对verilog文件进行宏定义替换等预处理操作;
23、模块依赖关系分析单元,根据模块内部实例化相关语句分析verilog文件的模块依赖关系;
24、语法分析单元,分析修改类型,根据用户输入的模块名,在模块依赖表中查找所有依赖于该模块的模块,这些模块同用户指定模块一起构成需要重新进行语法分析的模块集合,再编译时,仅对该模块集合中的模块重新进行语法分析;
25、本发明所述的一种设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的程序,其特征在于,所述处理器执行所述程序时实现任一项所述的一种基于增量编译的verilog语法分析方法中的步骤。
26、本发明所述的一种存储介质,存储有计算机程序,其特征在于,所述计算机程序被设计为运行时实现根据任一项所述的一种基于增量编译的verilog语法分析方法中的步骤。
27、有益效果:与现有技术相比,本发明具有如下显著优点:以模块为单位读入代码进行编译,解决了超大规模verilog设计代码一次性读取会突破内存限制导致语法分析程序崩溃的问题;根据模块语句获取模块间的依赖关系,并将模块依赖关系表和语法分析得到的抽象语法树结构存储在二进制文件中,代码发生修改时,根据模块修改类型和模块依赖关系表,得到需要重新进行语法分析的模块所组成列表,只对该列表中的模块重新进行语法分析,其余模块则保留二进制文件中存储的结果,有效缩短了硬件代码语法分析简短迭代的时间,提高了开发的效率;将抽象语法树结构作为中间结果保存在二进制文件中,可以更具通用性地支持后续其他eda工具开发,显著提高了eda工具开发的快捷性。
- 还没有人留言评论。精彩留言会获得点赞!