基于数字孪生和演化博弈的众包物流方法
本发明涉及物联网中车辆众包物流,特别是一种基于数字孪生和演化博弈的众包物流方法。
背景技术:
1、随着计算机应用和互联网技术的飞速发展,每秒都会产生大量的数据,我们已经进入了大数据时代。这些年出现了很多在线数据交易系统。众包数据交易是一种结合移动众感的新型数据交易范式,利用人群收集数据,解决销售数据源的稀缺性。众包是一种结合众包思想和移动设备感知能力的新型数据获取模式,它是物联网的一种形式。物联网通过众包感知系统提供更大、更复杂、更全面的感知服务,影响到灾害监测、交通管理、公共安全、物流管理、社会服务等生活的方方面面。在此背景下,有学者提出众包物流来优化物流管理,众包物流是结合互联网技术和传统物流运营模式的新型行业,外包公司机构得知用户事务要求后,根据用户需求找到最适方案。找到相应的互联网机构之后,外包公司机构将相应的物流工作分配到相应的运营部门,服务于用户以满足需求。
2、众包物流系统中有三个主要的利益相关者、即任务发布者、平台和众包工人。在现实中,由于他们自私的特性,总是希望最大化自己的利益,如果不进行干预,就会阻碍众包物流系统的健康持续发展。数字孪生(dt)是一种信息镜像模型,是物理实体的数字复制品。它通过连接物理世界和虚拟世界实现数据的无缝传输,从而允许虚拟实体与物理实体同时存在。数字孪生技术强调了两个重要特征。首先,每个定义都强调物理模型与相应的虚拟模型或虚拟对应物之间的联系。其次,通过使用传感器生成实时数据来建立连接。因为dt的实时性,可以帮助众包参与者及时了解众包物流系统的发展结果,使参与者及时发现系统可能发生的风险,有效地引导其选择更改策略,促进众包系统的健康发展。
3、目前如何使用演化博弈对众包参与方的行为进行分析来优化众包系统已成为研究热点,现有出现了一些相关的研究成果:yingjie wang等(the truthful evolution andincentive for large-scale mobile crowd sensing networks,2018,51187-51199)提出了一个演化博弈模型来预测移动众包系统的演化趋势,通过声誉机制解决虚假报告和搭便车问题,并使用k匿名来保护众包工人的信息;chuanxiu chi等(multistrategy repeatedgame-based mobile crowdsourcing incentive mechanism for mobile edge computingin internet of things,2019,2294-2307)提出了基于一种多策略重复博弈的激励机制用于引导工人长期参与和提供高质量的数据,并用演化博弈论和wright-fisher模型分析参与者策略的演化过程;zihao shao等(a method of user revenue selection based on apublisher-user evolutionary game model for mobile crowdsensing,2019,19(13))提出了一种基于非合作进化博弈论的发布者-用户进化博弈模型和收益选择方法来解决进化稳定均衡问题;fuxing li等(three-party evolutionary game model of stakeholdersin mobile crowdsourcing,2021,974-985)在任务发布者,平台和众包工人之间构建了一个三方演化博弈模型,用复制动力学方法分析演化博弈策略的稳定性,并给出策略避免搭便车和虚假报告问题。
4、但现有的方法大多仅使用了演化博弈进行理论分析,并没有对如何将演化博弈结果效率地引导作用于现实做出解决方案;因此,结合数字孪生的特点,设计出能够将演化博弈结果效率及时地引导众包参与方正确地对决策做出调整亟待解决的技术问题。
技术实现思路
1、为解决现有技术中存在的问题,本发明的目的是提供一种基于数字孪生和演化博弈的众包物流方法,本发明能够促进众包物流系统的健康发展。
2、为实现上述目的,本发明采用的技术方案是:一种基于数字孪生和演化博弈的众包物流方法,其特征在于,包括以下步骤:
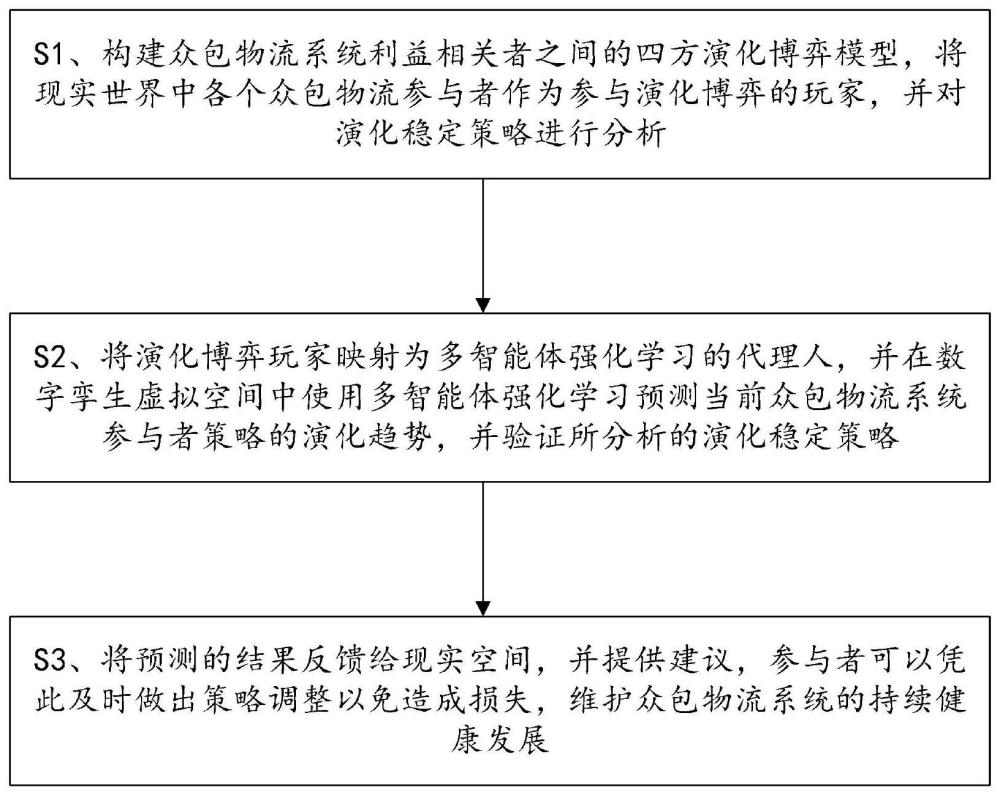
3、s1、构建众包物流系统利益相关者之间的多方演化博弈模型,将现实世界中各个众包参与者映射为数字孪生虚拟空间里参与演化博弈的玩家,分析演化稳定策略;
4、s2、将演化博弈的玩家映射为多智能体强化学习的代理人,并在数字孪生虚拟空间中使用多智能体强化学习预测当前众包物流系统参与者策略的演化趋势;
5、s3、将预测的结果反馈给现实空间,并提供建议,参与者凭此及时做出策略调整。
6、作为本发明的进一步改进,在步骤s1中,所述多方演化博弈模型包括四个玩家:临时工人,合同工人,基于区块链的平台和任务发布者。
7、作为本发明的进一步改进,所述步骤s1具体包括以下步骤:
8、s10、定义玩家的博弈策略,每个玩家包括诚实和不诚实两个策略,众包物流系统各个参与方之间的博弈策略共有十六种,其具体如下:
9、a)临时工人,合同工人,平台和任务发布者都采取诚实策略,用u代表临时工人的报酬比例,v代表临时工人的奖惩比例,λ代表众包工人的报酬比例,t代表众包工人的奖惩比例,pi代表任务发布者给众包工人和平台的报酬,chi代表众包工人按时运输的成本,r代表给予众包工人和平台的声望奖励,mp代表平台监管所需的成本,cp为平台区块链运行成本,oij为发布者在完成任务后能得到的收益,rq为给予发布者的声望奖励,此时博弈四方的收益表示为
10、b)合同工人选择不诚实策略,其他三方选择诚实策略,用cli代表众包工人没有按时运输时的成本,此时四方的收益表示为
11、c)发布者选择不诚实策略,其他三方选择诚实策略,用sq代表给予发布者的声望惩罚,此时四方的收益表示为
12、d)合同工人和发布者选择不诚实策略,而临时工人和平台选择诚实策略,此时四方的收益表示为
13、e)临时工人选择不诚实策略,其他参与方选择诚实策略,此时四方的收益表示为
14、f)所有众包工人都选择不诚实策略,平台和发布者选择诚实策略,此时四方的收益表示为(-cli,-cli,0,0);
15、g)合同工人和平台选择诚实策略,临时工人和发布者选择不诚实策略,此时四方的收益表示为
16、h)平台选择诚实策略,其他三方都选择不诚实策略,此时四方的收益表示为(-cli,-cli,0,0);
17、i)平台选择不诚实策略,其他三方都选择诚实策略,此时四方的收益表示为
18、j)平台和合同工人选择不诚实策略,临时工人和发布者选择诚实策略,用bt表示众包工人与平台合谋所需的成本,ag表示发布者由于运输不及时而造成的损失,cpi代表平台伪造物流报告所需的成本,此时四方的收益表示为
19、k)平台和发布者选择不诚实策略,众包工人都选择诚实策略,此时四方的收益表示为
20、l)临时工人选择诚实策略,其他三方都选择不诚实策略,此时四方的收益表示为
21、m)临时工人和平台都选择不诚实策略,合同工人和发布者选择诚实策略,此时四方的收益表示为
22、n)发布者选择诚实策略,其他三方都选择不诚实策略,此时四方的收益表示为
23、o)合同工人选择诚实策略,其他三方都选择不诚实策略,此时四方的收益表示为
24、p)所有众包参与方都选择不诚实策略,此时四方的收益表示为
25、其中,众包工人的诚实策略表示按要求配送货物,不诚实策略表示没有按要求配送,平台的诚实策略为监管工人配送过程,并拒绝与工人合谋骗取发布者的支付,不诚实策略为平台不进行监管,并与工人合谋,发布者的诚实策略表示给众包和工人真实的报酬,不诚实策略为不提供真实的报酬甚至不支付报酬;
26、s11、根据公式(1)得出临时工人策略的复制动态方程:
27、f(x)=dx/dt=x(1-x)(ux-u1-x)=x(1-x){[u+(1-y)(1-u)]zrλpi+vtr-(1+z-yz)chi+(1-z)(vts+bt)+cli} (1);
28、其中,ux为临时工人选择诚实策略时的期望收益、u1-x为临时工人选择不诚实策略时的期望收益;
29、s12、根据公式(2)得出合同工人策略的复制动态方程:
30、f(y)=dy/dt=y(1-y)(uy-u1-y)=y(1-y){[(1-u)+(1-y)u]zrλpi+(1-v)tr-(1+z-xz)chi+(1-z)[(1-v)ts+bt]+cli} (2);
31、其中,uy为合同工人选择诚实策略时的期望收益、u1-y为合同工人选择不诚实策略时的期望收益;
32、s13、根据公式(3)得出平台策略的复制动态方程:
33、f(z)=dz/dt=z(1-z)(uz-u1-z)=z(1-z){(x+y-xy-1)r(1-λ)pi-(2-x-y)(bt-cpi)+(x+y-xy)[-mp+(1-t)r]-(x+y-xy-1)cp+(1-t)s} (3);
34、其中,uz为平台选择诚实策略时的期望收益、u1-z为平台选择不诚实策略时的期望收益;
35、s14、根据公式(4)得出发布者策略的复制动态方程:
36、f(r)=dr/dt=r(1-r)(ur-u1-r)=r(1-r)(xz-xyz+yz-z+1)(rq+sq-pi) (4);
37、其中,uz为任务发布者选择诚实策略时的期望收益、u1-z为任务发布者选择不诚实策略时的期望收益;
38、s15、根据各博弈主体的复制动态方程,得到复制动态系统的雅可比矩阵:
39、
40、s16、令公式(1),公式(2),公式(3),公式(4)同时等于0,得到有利于众包物流系统健康发展的均衡点(1,1,1,1),(1,1,0,1),(0,1,1,1),并讨论其稳定性。
41、作为本发明的进一步改进,所述步骤s11还包括:
42、所述临时工人在选择诚实策略和不诚实策略时期望收益的计算如下:
43、
44、作为本发明的进一步改进,所述步骤s12还包括:
45、所述合同工人在选择诚实策略和不诚实策略时期望收益的计算如下:
46、
47、作为本发明的进一步改进,所述步骤s13还包括:
48、所述平台在选择诚实策略和不诚实策略时期望收益的计算如下:
49、
50、作为本发明的进一步改进,所述步骤s14还包括:
51、所述发布者在选择诚实策略和不诚实策略时期望收益的计算如下:
52、
53、作为本发明的进一步改进,所述步骤s16具体如下:
54、当系统满足chi-cli-uλpi-vtr<0,chi-cli-(1-u)λpi-(1-v)tr<0,mp-(1-t)(s+r)<0,pi-rq-sq<0时,均衡点(1,1,1,1)能保持稳定,即所有参与方都选择诚实策略;
55、当系统满足chi-cli-vt(r+s)-bt<0,chi-cli-(1-v)t(r+s)-bt<0,(1-t)(s+r)-mp<0,pi-rq-sq<0时,均衡点(1,1,0,1)能保持稳定,即尽管平台放弃监管,由于其他三方的诚信策略,众包物流系统也能健康发展;
56、当系统满足uλpi+vtr-chi+cli<0,2chi-cli-(1-u)λpi-(1-v)tr<0,mp-(1-t)(s+r)+bt-cpi<0,pi-rq-sq<0时,(0,1,1,1)为稳定点,即合同工人能完全接管临时工人完成众包物流任务;
57、作为本发明的进一步改进,所述步骤s2具体包括以下步骤:
58、s20、初始化t=0,q1t(s,a1,a2,a3,a4)=0,q2t(s,a1,a2,a3,a4)=0,q3t(s,a1,a2,a3,a4)=0,q4t(s,a1,a2,a3,a4)=0。a1∈a1,a2∈a2,a3∈a3,a4∈a4,并初始化当前状态;
59、s21、通过矩阵博弈(q1t(s),q2t(s),q3t(s),q4t(s))计算混合策略纳什均衡(σ1(s),σ2(s),σ3(s),σ4(s)),并根据σ1(s)选择一个动作a1,观察奖励r1t,r2t,r3t,r4t,对手的动作a2,a3,a4和下一个状态s';
60、s22、计算博弈(q1t+1(s'),q2t+1(s'),q3t+1(s'),q4t+1(s'))中的混合策略纳什均衡(σ1(s'),σ2(s'),σ3(s'),σ4(s')),并更新q1,q2,q3,q4;
61、s23、转回步骤s21,设置t=t+1,重复直到所有状态已被搜索。
62、作为本发明的进一步改进,所述步骤s20还包括:
63、所述代理人i在t轮的q值的计算如下:
64、qit(s,a1,a2,a3,a4)=ri(s,a1,a2,a3,a4)+γσp(s'|s,a1,a2,a3,a4)qit(s,a1,a2,a3,a4) (10);
65、其中t为重复博弈次数,γ为q-learning的折扣因子,ai为代理人i在状态s时选择的动作,ri(s,a1,a2,a3,a4)为代理人i的奖励函数,p(s'|s,a1,a2,a3,a4)为状态s'的转移概率;
66、所述代理人i在t+1轮的q值计算如下:
67、q1t+1(s,a1,a2,a3,a4)=(1-αt)q1t(s,a1,a2,a3,a4)+αt[r1t+γσ1(s') σ2(s') σ3(s')σ4(s')q1t(s')] (11);
68、其中αt为q-learning的学习率,σi(s')为代理人i在s'状态的混合博弈纳什均衡。
69、本发明的有益效果是:
70、1、本发明通过构建临时工人,合同工人,基于区块链的平台和任务请求者之间的四方演化博弈模型,将各个现实世界众包参与者映射为dt虚拟空间里参与演化博弈的玩家,并将系统数据通过服务器实时传入dt中,然后在dt虚拟空间中使用多智能体强化学习方法预测当前众包物流系统参与者策略的演化趋势,然后将预测的结果反馈给现实空间,并给出建议,为避免造成损失,各个参与方可以凭此及时做出策略调整,也可以维护众包物流系统的持续健康发展,有助于更好的理解现实中众包物流系统中各个参与方的行为;
71、2、从行为预测分析:本发明应用于物联网背景下的众包物流领域,在众包物流过程中,由于作为众包系统的利益相关者都是有限理性的个体,都具有自私的特征,可能会使众包物流系统的效率降低,阻碍众包物流系统的可持续发展,因此,本发明使用演化博弈方法对众包物流系统参与方进行建模,建立临时工人,合同工人,基于区块链的平台和任务发布者四方演化博弈模型,将各个参与方映射为演化博弈模型中的玩家,以便有效地分析其策略发展趋势。
72、3、从系统性能分析:本发明中所使用的系统,将博弈玩家映射为虚拟空间中多智能体强化学习的智能体,能够及时预测出策略发展趋势反馈给现实空间,可保持一个较好的系统性能。
- 还没有人留言评论。精彩留言会获得点赞!