基于SMOTE过采样与Autogluon模型结合的岩爆智能预测方法
本发明属于岩土工程领域,也涉及计算机领域,尤其是一种岩爆智能预测方法。
背景技术:
1、随着地下空间和矿产资源的不断开发利用,越来越多的地下岩石项目建设在越来越深的。岩爆通常是由储存在处于高应力状态的硬、脆性岩石的弹性能突然释放,从而产生岩石剥落、碎化、弹射的动力失稳灾害,是一种深层岩体的动态地质灾害。由于岩爆造成巨大破坏,不仅对施工人员与机械设备造成严重的威胁,同时也会造成较大经济损失。目前,众多学者对岩爆的预测方法进行了较多的研究。并且提出了大量的岩爆预测模型和智能算法。然而,传统预测模型仅含有单指标因素,对特定实例工程建立岩爆预测判别式,其预测结果受人为因素影响可能带来误差。近年来多指标岩爆预测方法研究相对较多,如模糊数学综合评判方法、多维云模型等、物元模型。多指标岩爆预测方法逐渐取代了单指标预测方法,其预测效果明显好于单指标岩爆预测法。
2、随着大数据和机器学习的发展,越来越多的学者利用机器学习预测岩爆,避免了人为主观因素带来的误差和影响,岩爆预测结果更加真是可靠,但它们仍然存在一些缺点,如训练时间长和预测准确率有待提高等问题。
技术实现思路
1、本发明的目的在于针对现有技术中的不足,提供一种基于smote过采样与autogluon模型结合的岩爆智能预测方法。
2、为了解决上述的问题,本发明的方案如下:
3、基于smote过采样与autogluon模型结合的岩爆智能预测方法,其特征在于,包括以下步骤:s1.收集岩爆案例数据,构建岩爆案例数据库;s2.使用smote过采样方法平衡数据库,将数据库分为训练集和测试集;s3.利用步骤s2分好的训练集对autogluon模型进行训练,得到最优训练模型;s4.根据步骤s3中训练好的最优模型对步骤s2分好的测试集进行预测。
4、进一步的,所述岩爆案例数据库的数据集包括以下参数:最大切应力,单轴抗拉强度,单轴抗压强度,最大切应力与单轴抗拉强度之比,单轴抗拉强度与单轴抗压强度之比,弹性能指数。
5、进一步的,步骤s2中,smote过采样方法将所有类别样本平衡至同等数量,并在样本数量达到均衡后,随机打乱,以4比1的比例将数据库分为训练集和测试集。
6、另外,本发明还提供一种基于smote过采样与autogluon模型结合的岩爆智能预测系统,包括岩爆数据库模块、smote过采样模块、autogluon模型训练模块和预测模块。
7、所述岩爆数据库模块建立有岩爆数据集,所述岩爆数据集的初始数据为文献检索整理所得;
8、所述smote过采样模块,通过smote过采样方法对岩爆数据库进行数据过采样处理,得到平衡数据集。
9、所述autogluon模型训练模块和预测模块,利用数据集对autogluon模型进行训练以及结果验证。
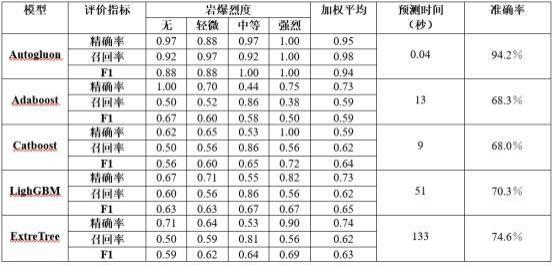
10、 采用以上技术方案,本发明的准确率达到了94.2%,在岩爆预测方面具有优异的性能。与adaboost(ab)、catboost(cb)、lightgbm(lgbm)和extretree(et)模型相比, 本发明的准确率分别提高了25.9%、26.2%、23.9%、19.6%。另外本发明的预测时间为0.04秒,快于其他所有模型的预测时间(ab模型的预测时间为13秒,cb模型的预测时间为9秒,lgbm模型的预测时间为51秒,et模型的预测时间为133秒)。
11、实施方式
12、 应该理解,以下详细说明都是例示性的,旨在对本发明提供进一步说明,并非对本发明的限定。
13、实施例一
14、本发明基于smote过采样与autogluon模型结合的岩爆智能预测方法,包括以下步骤:s1.收集岩爆案例数据,构建岩爆案例数据库;s2.使用smote过采样方法平衡数据库,将数据库分为训练集和测试集;s3.利用步骤s2分好的训练集对autogluon模型进行训练,得到最优训练模型;s4.根据步骤s3中训练好的最优模型对步骤s2分好的测试集进行预测。
15、具体的,在步骤s1岩爆数据库的构建中,通过文献检索整理搜集岩爆数据,组成含有246个示例工程的岩爆数据的岩爆数据库。
16、 本发明选取与岩爆活动密切相关的6个岩石力学参数作为参数指标,分别为最大切应力(mts),单轴抗拉强度(ucs),单轴抗压强度(uts),最大切应力与单轴抗拉强度之比(sc),单轴抗拉强度与单轴抗压强度之比(bc),弹性能指数(eei)。通过选取的6个指标,建立岩爆数据库,如表1所示。岩爆烈度按照常规的分级方式分为四级,分别为无岩爆、轻微岩爆、中等岩爆和强烈岩爆(用数字0至3来表示)。
17、表1
18、建立好岩爆数据库后,需要在步骤s2中,利用smote过采样方法对数据库进行预处理。具体如下:在岩爆数据库中,无岩爆样本43例、轻微岩爆79例、中等岩爆80例、强烈岩爆44例。 现有搜集的数据库存在样本数量不平衡的情况,无岩爆和强烈岩爆为少类数据,弱岩爆和中等岩爆为多类数据,在机器学习分类算法训练过程中,处理不均衡数据集会更多地关注多类数据,从而导致少类数据在预测占比的权重降低,影响机器学习算法预测性能。为了减少不均衡数据集的影响,采用smote过采样方法增加无岩爆样本与弱岩爆样本边界处的无岩爆样本数量和中等岩爆样本与强烈岩爆样本边界处的强烈岩爆样本数量,并且让各类样本数量达到均衡。
19、经过smote过采样方法预处理数据库后,所有类别样本数量达到平衡,对处理后的数据进行分割,基于前人对数据分割经验,随机选取80%的数据用于训练机器学习模型的训练集,剩余20%的数据用于测试训练后模型准确性的测试集。
20、当数据库预处理好后,在步骤s3中,autogluon模型将自动对步骤s2分好的训练集进行特征工程选择,最优模型选择以及超参数优化,从而得到最优模型,并对步骤s2分好的测试集进行预测。
21、不同于传统机器学习模型利用超参数优化算法代替人工调参,autogluon模型的基本思想则是融合多个无需超参数搜索的模型来提高最终模型的预测性能。autogluon模型依赖于stacking技术、k-则交叉bagging技术和多层stacking技术来提高预测性能,即利用stacking技术在同一数据集上独立训练出多个不一样的模型,对这些模型输出做加权和可以得到线性模型并利用k-则交叉bagging将多个同类别的训练模型输出做平均来降低预测的方差,最后利用多层stacking技术将多个模型的输出和数据合并起来再做一次stacking。此方法具有优秀的简单性和鲁棒性。
22、 在得到训练好的最优autogluon模型后,为了进一步验证基于smote过采样与autogluon模型结合的岩爆智能预测方法的预测性能,本发明与不同的岩爆预测模型对本发明建立的数据库进行预测的结果进行对比分析。本发明选用adaboost(ab)、catboost(cb)、lightgbm(lgbm)和extretree(et)模型进行对比。这4个模型的构建同样都是基于步骤s2预处理后的数据库。模型建立完成后带入测试集,得到相应的评估指标的值,如表2所示。
23、表2
24、
25、其中准确率(accuracy)、精确度、召回率和f1值计算公式如下。
26、
27、
28、
29、
30、式中:tp为被模型预测为正类的正样本,tn为被模型预测为负类的负样本,fp为被模型预测为正类的负样本,fn为被模型预测为负类的正样本。
31、 从表2可以看出,本发明基于smote过采样与autogluon模型结合的岩爆智能预测方法的准确率达到了94.2%,在岩爆预测方面具有优异的性能。与adaboost(ab)、catboost(cb)、lightgbm(lgbm)和extretree(et)模型相比, 本发明的准确率分别提高了25.9%、26.2%、23.9%、19.6%。另外本发明的预测时间为0.04秒,快于其他所有模型的预测时间(ab模型的预测时间为13秒,cb模型的预测时间为9秒,lgbm模型的预测时间为51秒,et模型的预测时间为133秒)。
32、以上仅对本发明的具体实施例作了详细说明,但是本发明并不限于上述实施例,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!