基于spark的分布计算引擎服务的制作方法
本公开涉及大数据计算,尤其涉及一种基于spark的分布计算方法、基于spark的分布计算引擎服务系统和电子设备。
背景技术:
1、随着大数据技术的发展,企业对数据分析的需求越来越旺盛,同时随着数据量的增加和分析需求的复杂化,对于数据计算引擎的扩展性和高可用性也提出了更高的要求。同时spark作为一款广泛使用的开源计算框架,被应用在很多数据分析产品中提供计算服务,如何利用spark提供高可用的计算服务成为一个技术难点。
2、spark作为计算框架,不像传统数据库可以直接提供sql查询服务,而是需要用户自己编程提交代码,或者启动thrift server提供sql服务,但是thrift server是单副本程序,无法提供高可用的服务,一旦程序异常退出则需要人工重启服务,同时thrift server无法做资源隔离及横向扩展,导致很容易被单个用户的请求占满资源,影响其他用的的查询。
3、况且利用spark做数据分析需要用户编程并提交代码,响应过慢且门槛高。
4、此外,thrift server可以基于spark提供sql服务,但是thrift server既是任务接收方又是执行方,所以只能启动单个程序,一旦程序因为某些sql卡住或者崩溃就无法提供服务,同时无法做资源隔离和水平扩展。
技术实现思路
1、为了解决上述问题,本技术提出一种基于spark的分布计算方法、基于spark的分布计算引擎服务系统和电子设备。
2、本技术一方面,提出一种基于spark的分布计算方法,包括如下步骤:
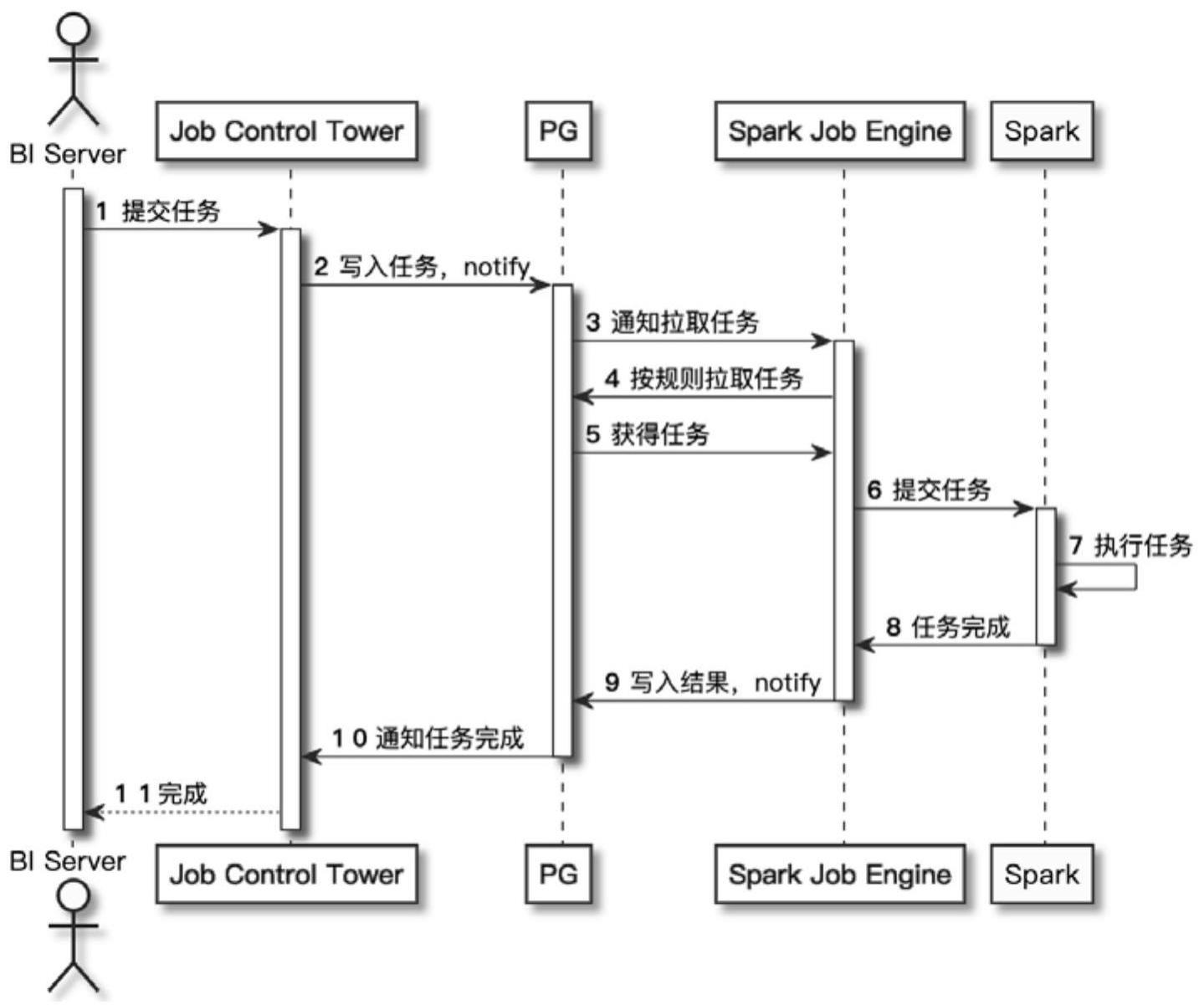
3、s1、用户(bi server)提交数据查询请求的任务到任务分发组件(job controltower);
4、s2、任务分发组件(job control tower)将任务写入并通知到任务队列(pg);
5、s3、任务队列(pg)接收到任务后通知spark中分布式设置的计算组件(spark jobengine)拉取任务;
6、s4、计算组件(spark job engine)从任务队列(pg)拉取任务,并提交任务给spark;
7、s5、spark执行任务。
8、作为本技术的一可选实施方案,可选地,步骤s3中,在通知spark中分布式设置的计算组件(spark job engine)拉取任务之后,还包括:
9、从spark分布式设置的计算组件(spark job engine)中,判断可用的计算组件(spark job engine);
10、将该可用的计算组件(spark job engine)作为目标计算组件(spark jobengine)。
11、作为本技术的一可选实施方案,可选地,步骤s3中,在通知spark中分布式设置的计算组件(spark job engine)拉取任务之后,还包括:
12、判断所述目标计算组件(spark job engine)的数量是否不低于两个:
13、若是,则进入步骤s4;
14、反之放弃,并发出对应的计算服务通知。
15、作为本技术的一可选实施方案,可选地,步骤s4中,在计算组件(spark jobengine)从任务队列(pg)拉取任务,并提交任务给spark之前,还包括:
16、判断是否存在多个所述目标计算组件(spark job engine):
17、若是,则从多个所述目标计算组件(spark job engine)中,选取一个所述目标计算组件(spark job engine)执行任务;若是存在多个任务,则分别随机选择一个所述目标计算组件(spark job engine)执行相应的任务;
18、反之放弃。
19、作为本技术的一可选实施方案,可选地,步骤s5,在spark执行任务之后,还包括:
20、由spark通知所述目标计算组件(spark job engine)任务完成,并将执行任务的计算结果反馈至对应的所述目标计算组件(spark job engine);
21、所述目标计算组件(spark job engine)将所述计算结果写入所述任务队列(pg),同时通知所述任务队列(pg);
22、任务队列(pg)通知所述任务分发组件(job control tower)任务完成;
23、所述任务分发组件(job control tower)获取任务的所述计算结果,并返回用户(bi server)。
24、本技术另一方面,提出一种基于spark的分布计算引擎服务系统,包括:
25、任务分发组件(job control tower),用于接收用户(bi server)提交的数据查询请求的任务,并将任务写入并通知到任务队列(pg);
26、任务队列(pg),用于接收到任务后,通知spark中分布式设置的计算组件(sparkjob engine)拉取任务;
27、计算组件(spark job engine),用于从任务队列(pg)拉取任务,并提交任务给spark;
28、spark,用于执行任务,执行完毕,通知所述目标计算组件(spark job engine)任务完成,并将执行任务的计算结果反馈至对应的所述目标计算组件(spark job engine)。
29、作为本技术的一可选实施方案,可选地,所述任务队列(pg),还用于:
30、在通知spark中分布式设置的计算组件(spark job engine)拉取任务之后,从spark分布式设置的计算组件(spark job engine)中,判断可用的计算组件(spark jobengine);
31、将该可用的计算组件(spark job engine)作为目标计算组件(spark jobengine)。
32、作为本技术的一可选实施方案,可选地所述任务队列(pg),还用于:
33、在计算组件(spark job engine)从任务队列(pg)拉取任务,并提交任务给spark之前,判断所述目标计算组件(spark job engine)的数量是否不低于两个:
34、若是,则进入步骤s4;
35、反之放弃,并发出对应的计算服务通知。
36、作为本技术的一可选实施方案,可选地,
37、所述目标计算组件(spark job engine),还用于:将所述计算结果写入所述任务队列(pg),同时通知所述任务队列(pg);
38、任务队列(pg),还用于:通知所述任务分发组件(job control tower)任务完成;
39、所述任务分发组件(job control tower),还用于:获取任务的所述计算结果,并返回用户(bi server)。
40、本技术另一方面,还提出一种电子设备,包括:
41、处理器;
42、用于存储处理器可执行指令的存储器;
43、其中,所述处理器被配置为执行所述可执行指令时实现所述的一种基于spark的分布计算方法。
44、本发明的技术效果:
45、本技术通过解耦任务分配与任务计算层,使得任务计算层可以由多个计算进程(多个可用的计算组件(spark job engine)共同提供服务,支持启动多个任务,从而避免执行任务过程中宕机而影响整体服务,多个任务计算组件也可以避免单个用户请求占满所有资源而影响服务,同时常驻的spark计算组件可以提供实时的数据查询服务,避免用户编程提交代码的高门槛和高延迟。防止单个查询导致整体不可用。解决原有的thrift server只能由单个服务提供jdbc连接,无法实现高可用,同时执行复杂sql的时候thrift server服务容易卡住或者崩溃的技术缺点。
46、根据下面参考附图对示例性实施例的详细说明,本公开的其它特征及方面将变得清楚。
- 还没有人留言评论。精彩留言会获得点赞!