一种基于人机共驾的自动驾驶安全训练方法
本发明属于智能交通控制,主要涉及了一种基于人机共驾的自动驾驶安全训练方法。
背景技术:
1、在传统的深度强化学习训练中,智能体往往通过与环境的大量交互来获取经验并得到一个近似的最优策略。在训练过程中,智能体的动作随着训练时间的增加逐渐由随机变得智能。深度强化学习的本质是在错误中学习,当遇到不理想的结果时,环境返回一个负奖励来否认当前策略。在自动驾驶领域,危险的动作往往会引发碰撞等严重的后果,为了解决这个问题,许多技术在训练过程中引入人类专家经验来辅助智能体进行训练。
2、然而,一旦人类专家参与了训练过程,探索的策略就变成了人机混合策略,而且,人类的策略实际上是以样本的形式体现的,是隐式的,无法直接被用来指导智能体的训练。
3、深度q网络作为一种经典的值方法,被广泛地运用,目前在深度q网络的训练过程中添加人类专家的样本参与训练的方法主要有2种:
4、1.将人类示范动作当成一般的探索样本进行训练,即将人类示范动作及其相应的状态、后继状态和奖励值当成普通的四元组经验参与训练,与智能体的探索样本相比,人类的样本不会更新。这个方案在训练过程中确保了贝尔曼方程,但对人类样本的利用是不足的。
5、2.与模仿学习相结合,用人类的示范动作来进行训练,在训练的过程中抽取一部分探索样本和一部分人类的示范动作共同计算损失值并更新网络参数。这样的方法进一步利用了人类的示范动作,但是却忽略了人类所拒绝的危险动作同样是有价值的,同时人类示范动作的次优性可能影响最终的结果。
技术实现思路
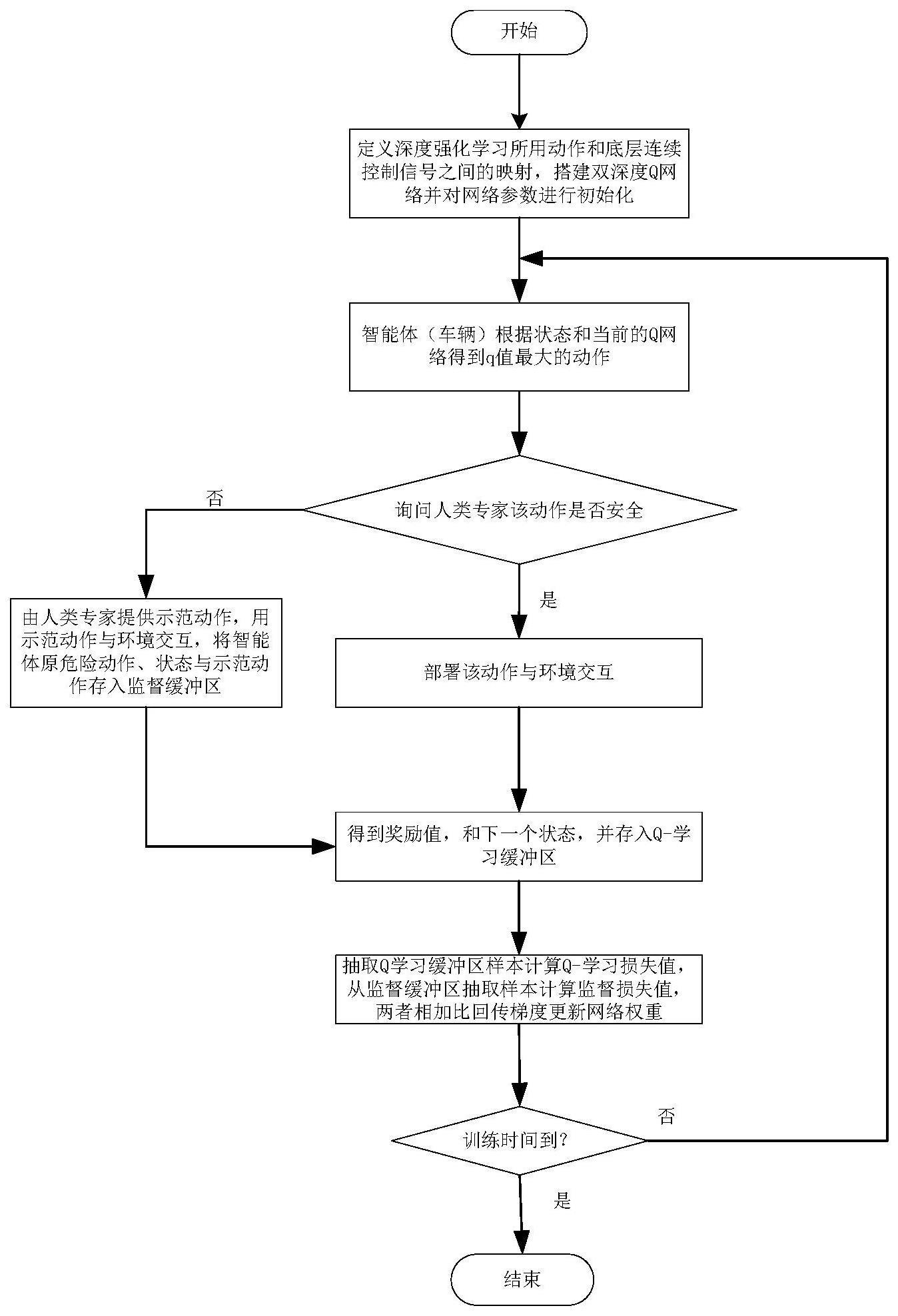
1、本发明正是针对现有技术中,在基于值方法的深度强化学习训练下,无法充分利用人类专家样本中的所有信息的问题,提供了一种基于人机共驾的自动驾驶安全训练方法,首先将上层的离散控制动作映射成底层的物理控制信号;设置超参数,搭建双深度q网络,基于搭建的网络模型,对受控车辆进行基于人机共驾的深度强化学习训练;训练中,先将受控车辆的动作经过人类专家判断,如果动作被判断为安全,则直接被使用;如果动作被判断为危险,由人类专家提供示范动作,并将状态、危险动作和人类专家的示范动作存到监督缓冲区;设计奖励函数,将经过人类专家评判之后的动作部署到环境中,与环境交互,得到状态、动作和奖励值对,并存到q-学习缓冲区;从q-学习缓冲区中获取状态、动作和奖励值对,按照q-学习的标准形式计算q-学习损失值,从监督缓冲区得到状态、危险动作和人类专家的示范动作对,并计算监督损失值,两者相加并回传更新网络权重;重复步骤,直到训练时间结束。本方法可以确保安全的训练过程,并提高训练速度和效果。
2、为了实现上述目的,本发明采取的技术方案是:一种基于人机共驾的自动驾驶安全训练方法,包括如下步骤:
3、s1:定义上层的离散控制器对应车辆底层的控制信号,将上层的离散控制动作映射成底层的物理控制信号;所述上层的离散控制动作确定目标值,底层的物理控制信号由比例控制器获得;
4、s2:设置超参数,搭建双深度q网络,对网络参数进行初始化;
5、s3:基于步骤s2搭建的网络模型,对受控车辆进行基于人机共驾的深度强化学习训练;所述训练中,先将受控车辆的动作经过人类专家判断,如果动作被判断为安全,则直接被使用;如果动作被判断为危险,由人类专家提供示范动作,并将状态、危险动作和人类专家的示范动作存到监督缓冲区;
6、s4:设计奖励函数,将经过人类专家评判之后的动作部署到环境中,与环境交互,得到状态、动作和奖励值对,并存到q-学习缓冲区;
7、s5:从q-学习缓冲区中获取状态、动作和奖励值对,按照q-学习的标准形式计算q-学习损失值,从监督缓冲区得到状态、危险动作和人类专家的示范动作对,并计算监督损失值,两者相加并回传更新网络权重;
8、s6:重复步骤s3-s5,直到训练时间结束。
9、作为本发明的一种改进,所述步骤s1中,离散控制器的控制周期为h,在t∈[kh,(k+1)h)内,加速度控制信号a(t)由以下比例控制器得到:
10、a(t)=kp(vr(k)-v(t)),
11、其中,vr(k)是期望速度,v(t)是当前速度,kp是控制器增益;
12、在t∈[kh,(k+1)h)内,前轮转向控制信号δ(t)的具体表达式为:
13、
14、
15、ψr(t)=ψl(t)+δψr(t),
16、
17、vlat,r(t)=-kp,latδlat(k),
18、其中,ψ(t)是当前受控车辆的航向角,ψl(t)是车道朝向,vlat,r(t)是横向速度指令,δψr(t)是受控车辆对应所需的航向变化,kp,lat和kp,ψ是控制器增益,δlat(k)是车辆相对于车道中心线的横向位置;
19、离散控制器通过深度强化学习进行训练,包含左变道、保持、右变道、加速、减速五个动作指令;在控制时刻k,定义最左侧车道中心线的纵坐标为0,指令左变道使得δlat(k)=max{0,δlat(k-1)-l},其中,l是车道宽度;指令右变道使得δlat(k)=min{(n-1)*l,δlat(k-1)+l},其中,n是车道数;指令保持意味着δlat(k)=δlat(k-1)和vr(k)=vr(k-1);指令加速意味着vr(k)=min{vmax,vr(k-1)+δv},其中vmax表示车辆的最大速度,δv表示每次速度变化的幅度;指令减速意味着vr(k)=max{cmin,vr(k-1)-δv},其中,cmin是车辆的最小速度。
20、作为本发明的一种改进,所述步骤s3具体为:将受控车辆视为一个智能体进行深度强化学习的训练,智能体根据状态得到离散动作的q值,选择q值最大的动作作为智能体当前时刻决策的动作,对该动作进行判断。
21、作为本发明的另一种改进,所述步骤s4中的奖励函数为:
22、
23、其中,λ是的权重系数,是激励车辆保持高速行驶的奖励,它的表达式是
24、
25、其中,裁剪函数clip(x,xl,xu)的作用是将变量x的值裁剪到区间[xl,xu],vx(k)是受控车辆的速度在车道纵向即车辆前进方向上的投影,是对危险动作的惩罚,它的表达式为:
26、
27、作为本发明的另一种改进,所述步骤s5中的损失函数为:
28、
29、其中,q是q(s,a;θ)的简写,q(s,a;θ)表示用参数θ拟合的动作-价值函数,jdq(q)标准的q-学习损失值,je(q)和分别表示专家示范动作和被专家拒绝的危险动作的监督损失,jl2(q)是l2正则化损失,λ1、λ2和λ3均为权重因子。
30、作为本发明的又一种改进,所述jdq(q)使用q-学习缓冲区的样本进行计算,并具有以下形式
31、jdq(q)=(r(s,a)+γq(s′,a′max;θ′)-q(s,a;θ))2,
32、其中,γ∈[0,1]是折扣因子,q(s,a;θ′)是目标网络,它周期性地从主网络q(s,a;θ)中复制参数,s′是s的后继状态,q(s′,a′max;θ′)是以目标状态当前的参数计算,后继状态s′的最大价值动作a′max对应的q值;
33、je(q)和均用监督缓冲区的样本计算,它们分别表示专家示范动作和被专家拒绝的危险动作的监督损失,je(q)的表达式为
34、
35、其中,ae表示专家针对状态s提供的示范动作,l1(s,ae,a)是边界函数,在a=ae时取0,在a为其他数时取δ1(δ1>0);
36、的表达式为:
37、
38、其中,aa表示被专家标记的危险动作,l2(s,aa,a)是一个边界函数,在a=aa时取0,在a为其他数时取-δ2(δ2>0)。
39、作为本发明的更进一步改进,所述λ1被设计成随着训练迭代而逐渐减小的系数,第n+1次迭代时,λ1(n+1)=0.999*λ1(n)。
40、与现有技术相比,本发明具有的有益效果:
41、(1)本发明通过人类专家的判断,确保了智能体与环境交互时采用的是安全的动作,确保了安全的训练过程,避免因为危险动作所导致的严重后果。
42、(2)本发明充分利用了人类专家干预的样本信息,将人类的示范动作和人类所标记的危险动作引入到损失值的计算中,参与了梯度回传和网络参数的更新,用人类干预样本来提高训练速度和效果。
43、(3)本发明在损失值计算上采用了时变的权重参数,避免了人类示范动作的次优性影响的最终训练效果。
- 还没有人留言评论。精彩留言会获得点赞!