一种基于非模态实例分割的图像非可见区域补全方法
本发明涉及计算机视觉,尤其涉及一种基于非模态实例分割的图像非可见区域补全方法。
背景技术:
1、利用计算机视觉技术进行场景理解,会存在许多物体被遮挡甚至物体之间相互遮挡的情况,在物体局部被遮挡的情景下,人类可以根据先验知识感知被遮挡物体的完整形态,描述被遮挡区域的边界信息,具有从可见的物体形态收集先验信息并推断不可见线索的能力,这种能力被称为非模态(amodal)预测。随着深度学习技术的普及,各领域的图像分类、目标检测、图像分割等视觉技术飞速发展,甚至在预测和识别可见物体的能力已超过人类的视觉系统。但上述技术主要用于图像中可见区域的预测,尚缺乏对图像中非可见区域的预测能力。而补全图像中非可见部分形态,有助于将无序的、碎片化的、不完整的对象组成连贯、完整的场景。
2、预测图像中非可见区域形状的能力,可以在实际应用场景中解决许多问题。比如在农业领域,开发适用于植物果实采摘的机器视觉系统时,对非可见区域的预测可以使机器人能够在复杂、杂乱的场景中抓取和操纵隐藏在背后的物体。恢复被遮挡物体的完整形态的最常用的方法是非模态实例分割方法,其核心思想是分割出物体可见区域与非可见区域的联合掩膜。
3、非模态实例分割技术主要分为两种类型:
4、一种为结合目标检测的两阶段实例分割方法,例如mask r-cnn是基于faster r-cnn改进的检测器,在边界框的roi里将实例分割出来生成实例掩膜。基于cnn的两阶段非模态实例分割方法,将faster r-cnn目标检测器预测输出的被遮挡区域边界框,根据分割热图内每个像素成为roi对象的概率大小,更新边界框,又重新计算热图迭代设计边界框。在mask r-cnn和panet中添加判断roi内是否存在遮挡,结合更多特征,适应于分割被遮挡掩膜的任务。bcnet将相同roi的重叠对象解耦为不相交的双层图像,结合图卷积模块(graphconvolutional network),通过两层物体间的遮挡关系来推断非可见区域掩膜。不同于cnn模型,上下文信息感知的复合卷积神经网络集成了符号模型与卷积神经网络的优点,能够对因中重度遮挡而失去上下文信息的实例预测出解释性强的边界框,再使用分割模型输出实例。
5、另一种方法为直接预测实例的被遮挡区域的掩膜,而不借助目标检测预测出的边界框。可以使用图形学的数学曲线三次贝赛尔曲线并完成进行被遮挡区域的形态补全。orcnn算法在mask r-cnn上设计了两个分割分支对可见掩膜和不可见掩膜同时展开预测,计算两者之间的差值,从而输出被遮挡区域掩膜的预测。sln为图像中的所有实例提供语义感知距离图,并在roi-align层中产生了不可见对象的边界框提议,以获取实例级和全局级的特征联系。
6、以上方法都是基于有监督学习模式的,都需要大量的像素级实例掩膜标签参与模型训练,而适用于遮挡区域的标签注释成本非常高。因此,研究人员尝试降低对人工标签的依赖,例如pcnet用自监督方式训练分割网络获得被遮挡区域掩膜的补全能力,只需要给出可见区域的掩膜作为输入,在可见掩膜上设置遮挡器,可以恢复之前的可见掩膜,并在补全过程中依赖图像中实例的遮挡顺序优化分割结果。asbunet使用遮挡边界代替pcnet中遮挡器的掩膜,抛弃了遮挡顺序的介入。变分自动编码器采用概率估计模糊的预测被遮挡区域掩膜,生成多样的非模态掩膜,进行提案决议从而不需要真值标注的掩膜标签。csdnet通过真实图像生成伪非模态掩膜,通过将图像分为许多实例层,对图层的遮挡建模,估测图层的遮挡顺序,它将在图像的每一层上检测到的完全可见的物体实际上是下一层的遮挡物。
技术实现思路
1、本发明要解决的技术问题是针对上述现有技术的不足,提供一种基于非模态实例分割的图像非可见区域补全方法,基于弱监督深度学习、非模态预测等像素预测、图像实例分割技术实现图像非可见区域的形态补全。
2、为解决上述技术问题,本发明所采取的技术方案是:一种基于非模态实例分割的图像非可见区域补全方法,建立基于swin transformer的弱监督学习的非模态实例分割模型,在改进的swin transformer unet分割网络上训练出非可见区域补全网络,从而无需人工注释被遮挡区域的掩膜;同时引入asbunet中的遮挡边界估计,重新设计在遮挡区域和可见区域的预测权重,引入对抗式生成学习的思想,将预测的非可见区域掩膜送入鉴别器中,添加对抗生成的鉴别器损失函数,改良鉴别器输出的掩膜形状。具体包括以下步骤:
3、步骤1:获取rgb图像数据集,并进行图像预处理;
4、获取rgb图像数据;根据获取的图像,采用计算余弦相似度的方式去除重复度大于设定阈值的图片,计算图片拉普拉斯变换的方差值来去除模糊程度大于设定阈值的图片,然后筛选出含有杂乱背景和拍摄角度不佳的图片从而删除;
5、步骤2:对图像数据集中的图像进行标注,构建训练集和验证集;
6、采用labelme工具注释图像语义标签,结合场景结构,对图像中可见和不可见部分均进行语义标注;针对未被遮挡的对象,采用长度掩膜标注方式;而针对被遮挡的对象,则采用分层级标注方式,第一层标注可见部分的区域,第二层标注出不可见部分的区域,第三层标注可见区域与非可见区域的联合区域,得到非模态真值标签;
7、按照9:1比例构建训练集和验证集,经过水平翻转,平移和随机裁剪,将训练集增强到2430张。
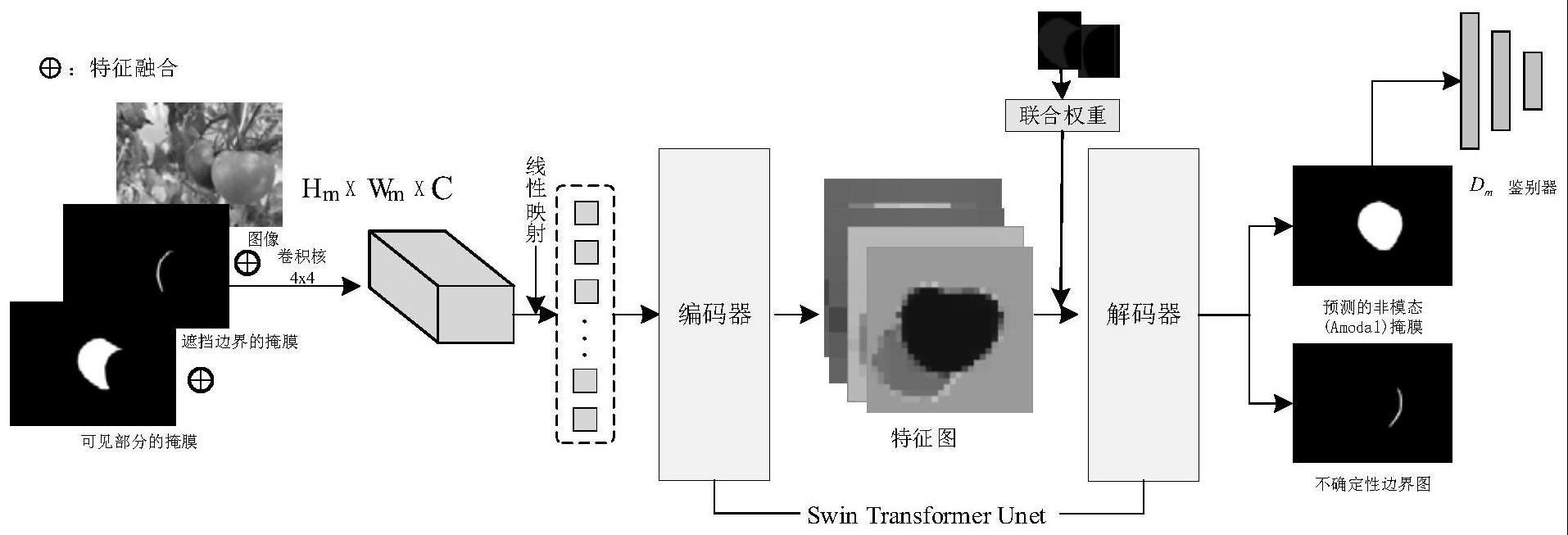
8、步骤3:构建基于swin transformer的弱监督学习的非模态实例分割模型;所述非模态实例分割模型包括4×4卷积核、线性层、编码器、解码器和鉴别器;
9、使用图像的遮挡边界和可见部分的掩膜作为模型的输入;首先使用4×4卷积核对图像行卷积操作,得到一个包含96个通道的张量;然后,在模型中应用线性层进行维度转换;经过线性层后,图像就变成了一系列被分割的特征,这些特征将被进一步输入编码器;所述编码器和解码器均采用了基于改进的swin transformer unet对称架构的swintransformer block;改进的swin transformer unet作为整个非模态实例分割模型的分割网络主干,编码器通过四个采样层收集浅层特征;然后,这些浅层特征通过跳转连接与解码器收集的深层特征融合;解码器中加入对可见区域掩膜和非可见区域掩膜预测的联合权重,用于对模型损失函数进行调整;鉴别器中引入对抗式生成学习思想,对解码器预测出来的不可见区域掩膜判断并改善掩膜形态;
10、非模态实例分割模型采用边界估计的方法将遮挡物与被遮挡物的接触边界以掩膜的形式输入到模型中,模型会输出被遮挡部分的另一边的具有不确定性的边界图;在两部分边界中的内容会得到像素填充,以得到合理的形状;
11、非模态实例分割模型采用部分补全的算法实现非模态掩膜补全的弱监督学习过程;基于让模型自主学习恢复不可见掩膜的思想,在训练阶段,对图像进行处理,随机采样出遮挡实例和被遮挡实例,并且只使用它们的可见掩膜进行模型训练,具体为:随机选择两张存在遮挡关系的图像,将含有实例a的图像记为ia,另一含有实例b的图像记为ib,并将图像中标记的两个实例的可见掩膜分别记为ma,mb;
12、第一种情况为实例a被实例b遮挡,将遮挡贴合的掩膜图记为ma/mb,再联合a实例的图像imagea被掩膜mb遮挡的图像,记为ia/mb,一起作为输入送入沙漏结构的分割网络中分割,恢复完成的目标为实例a的可见掩膜;同时为了防止模型过度补全其他实例的像素,第二种情况为实例b被实例a遮挡,将遮挡贴合的掩膜图记为mb/ma,联合输入ia/mb/ma,恢复完成的目标同样为实例a的可见掩膜,从而让非模态实例分割模型中的补全网络学习判断是否应该补全目标像素,达到正则化学习过程的目的;随后引入一个鉴别器dm,改善恢复完成的掩膜质量;
13、成对遮挡关系的排序,是由两个可见掩膜相连的实例组成相邻的实例对来表征它们之间的遮挡关系;使用成对的遮挡顺序矩阵来表示对象关系,并绘制出有向图可视化对象关系;
14、将遮挡顺序有向图表示为g=(y,t),y为图片中的所有对象集合,其数量为n,t为一个n×n的矩阵,ti,j表示相邻成对的两个对象i与j的遮挡关系,表达式如下:
15、
16、上式中,与代表对象i、j的补全后的非模态掩膜,mi与mj表示对象i、j的可见掩膜,与分别表示两个可见掩膜补全后的非模态掩膜的像素值增量;若i、j两个对象经过掩膜补全网络产生的增量相等且都为0,说明两者不存在遮挡,处在同一个图层,矩阵中ti,j的值为0,若前者增量小于后者,说明对象i遮挡了对象j,ti,j的值为1,若前者增量不小于后者,说明说明对象j遮挡了对象i,ti,j的值为-1;根据成对产生的遮挡顺序,逐渐推理出整个场景的对象间的遮挡顺序,对非模态掩膜补全提供了明确的先验信息支撑和可解释性;
17、步骤4:通过三个阶段训练非模态实例分割模型,确定最优模型参数;
18、步骤5:测试非模态实例分割模型补全能力和遮挡顺序预测能力;
19、非模态实例分割模型在经过训练之后,使用测试集对模型的非模态补全能力和顺序预测能力进行测试;用成对的遮挡顺序精度和补全后掩膜与地面真值的交并比来评估非模态对象分割模型;并且可视化补全后的非模态掩膜的结果,判断其形状是否合理且规则;随后将所有的非模态补全结果作为伪非模态注释标签,馈送进mask r-cnn上训练获取相应的对象分割结果;可视化对象分割结果图,采用coco数据集的评估指标评估非模态对象分割模型分割出的掩膜精度和准确度。
20、采用上述技术方案所产生的有益效果在于:本发明提供的一种基于非模态实例分割的图像非可见区域补全方法,构建的非模态对象分割模型可以在图像中只有可见区域的前提下进行掩膜标注和训练,让模型利用遮挡顺序、对象形体等先验信息对对象可见部分进行特征提取,最终实现对图像中对象不可见区域的信息预测,最终达到被遮挡对象的形体补全。该技术可以显著降低训练样本的标注难度和成本,以弱监督学习的方式实现对图像中对象的不可见区域进行形态信息恢复,这有助于提升采摘机器人视觉系统定位精度、采摘场景深度恢复精度等。
21、采用弱监督学习的方式,极大的减少实际应用中样本的遮挡注释成本,同时解决非模态(amodal)数据集稀少的问题。补全网络能有效的让具有真值的非模态(amodal)掩膜的图像数据在补全学习中学习有监督像素补全的信息,从而产生像素补全能力,在基于准确的遮挡顺序下,能够产生的伪注释标签可以替代真值标签参与模型训练。
22、模型的分割网络使用transformer unet,选用swin-tiny主干网络提升收敛速度,通过引入相邻对象间的遮挡边界,将较规则的番茄形态不确定性图作为形状先验,通过定义掩膜形状的边界来完成目标对象的像素。形状先验在预测对象完整形态时显著的提升了模型性能,先验使得模型在非模态掩膜补全的精确度达到了,适用于处理遮挡预测这样复杂的视觉任务。
- 还没有人留言评论。精彩留言会获得点赞!