一种基于时间序列特征的伪标签生成视频显著性检测方法
本发明涉及计算机视觉的,尤其涉及一种基于时间序列特征的伪标签生成视频显著性检测方法。
背景技术:
1、视频显著性检测是计算机视觉领域的一个重要研究方向,旨在自动地识别视频中最具有吸引力的区域,为视频分析、编辑和压缩等应用提供基础性支持。视频显著性检测已经广泛应用于视频广告、视频监控、视频摄像等领域。视频显著性检测是针对视频中最具吸引力区域(如运动物体、场景变化、光照变化等)进行识别和分析的技术,可以帮助计算机自动识别视频中最具吸引力的区域,从而提高视频分析、编辑、压缩等应用的效率和准确性。以下是一些比较重要的视频显著性检测技术:(1)基于深度学习的视频显著性检测:深度学习技术已经成为视频显著性检测的主流方法。其中,基于卷积神经网络(cnn)的方法是目前最常用的方法之一。通过使用cnn等深度学习模型,可以自动地学习视频中最具有吸引力的区域的特征,并进行显著性检测。(2)基于时空注意力机制的视频显著性检测:时空注意力机制是一种可以对视频中物体的运动和场景变化进行建模的方法,该方法通过引入时空注意力机制,来提高视频显著性检测的准确性和鲁棒性。(3)基于图像分割的视频显著性检测:该方法通过使用图像分割算法对视频帧进行分割,然后使用分割结果来进行显著性检测。这种方法可以提高视频显著性检测的准确度,并且对于一些复杂的场景也有较好的适应性。总之,视频显著性检测是一个涉及多个领域的交叉学科,其中涉及的技术和方法也非常多样化。随着技术的不断发展,视频显著性检测的研究和应用将会越来越深入和广泛。
2、传统的视频显著性检测方法主要基于手工特征提取和浅层模型,如颜色、纹理和边缘等特征,这些方法往往对噪声和光照变化敏感,且在处理复杂场景和动态背景时表现较差。针对传统方法的不足,研究人员提出了基于深度学习的视频显著性检测方法。其中,以sod(salient object detection)任务为代表的方法,使用卷积神经网络(cnn)提取图像特征,并通过后续处理得到视频显著性检测结果。然而,这些方法仍然存在一些问题。首先,它们对标注数据的需求量很大,而手动标注数据非常耗时且成本较高。此外,标注数据往往存在噪声和主观性问题,影响了模型的泛化性能。最近,基于循环神经网络(rnn)的方法,如长短时记忆网络(lstm)等,能够对时间序列信息进行建模,有效地提高视频显著性检测的准确性和稳定性。
技术实现思路
1、针对现有的视频显著性检测方法的检测精度不高、稳定性差的技术问题,本发明提出一种基于时间序列特征的伪标签生成视频显著性检测方法,在现有的基于lstm的方法上,通过lstm模型可以有效利用视频序列中的时间序列信息生成伪标签,结合伪标签的引入,能够充分利用视频中的多种特征,能够提高视频显著性检测的准确性和稳定性。
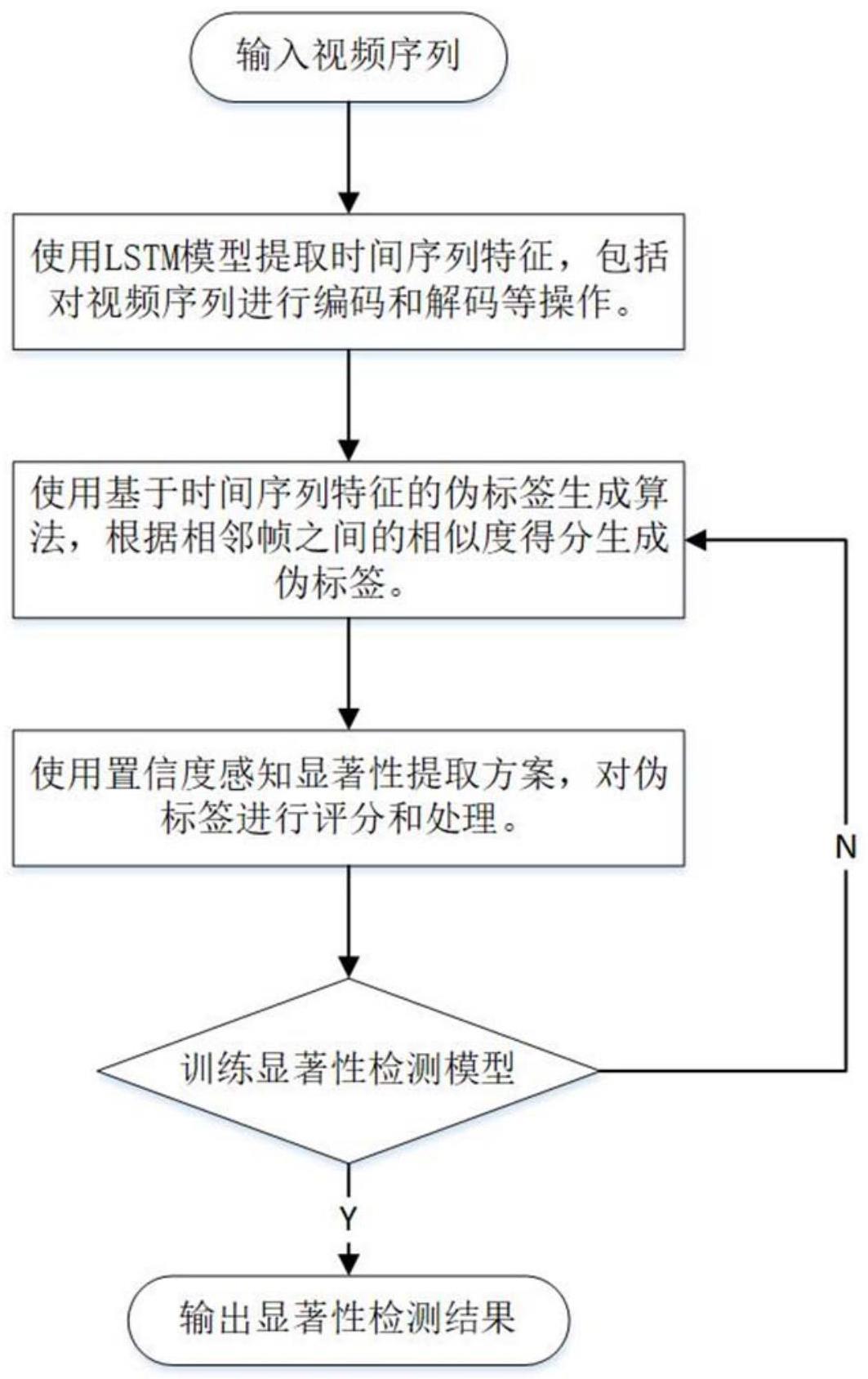
2、为了达到上述目的,本发明的技术方案是这样实现的:一种基于时间序列特征的伪标签生成视频显著性检测方法,其步骤如下:
3、s1:将数据集中的视频序列输入到lstm模型中进行编码和解码,提取视频序列的时间序列特征;
4、s2:基于时间序列特征的伪标签生成算法根据视频序列中相邻帧之间的相似度生成伪标签,将生成的伪标签和真实标签放在一起作为一个训练数据集训练lstm模型;
5、s3:利用置信度感知显著性提取方案根据样本的置信度和训练进度对带有噪声标签的样本进行评分,选择置信度高的样本作为新的伪标签;
6、s4:采用一种评分机制来引导lstm模型逐步从简单到困难地提取显著性知识;
7、s5:用新的伪标签和数据集中每一帧标注的图像组成新训练数据集,利用新训练数据集反复训练lstm模型,得到显著性检测模型;
8、s6:将待检测的新训练数据集输入到显著性检测模型中,得到新训练数据集中每一帧图像的显著性检测结果,得到待检测视频序列的显著图。
9、优选地,将每个视频序列中的每一帧图像输入到一个预训练的卷积神经网络中,卷积神经网络将每一帧图像转换为具有固定维度的特征向量,得到每一帧图像的特征表示;将每一帧图像特征表示输入到lstm模型中,提取时间序列特征。
10、优选地,所述数据集为davis数据集,davis数据集的每个视频序列提供了像素级别的注释,包括前景目标分割和边界框注释;在训练时,使用随机裁剪、水平翻转和调整亮度的数据增强技术来处理davis数据集的视频序列;
11、所述卷积神经网络是经典的resnet网络,使用davis数据集进行预训练,使用预训练的权重初始化resnet网络,通过反向传播和梯度下降算法微调resnet网络参数。
12、优选地,所述lstm模型包括依次连接的输入层、编码器、解码器和输出层,输入层接收输入的视频序列,编码器对视频序列进行编码和提取时间序列特征,解码器使用全连接层将编码器的时间序列特征映射到所需的输出空间,输出层输出时间序列的特征向量。
13、优选地,所述编码器包括依次连接的多个lstm层和bi-lstm层,lstm层通过学习时间依赖关系捕捉视频序列的短期依赖关系;bi-lstm层则通过同时处理正向和反向的视频序列,捕捉更全面的上下文信息。
14、优选地,所述编码器包括依次连接的第一lstm层、第二lstm层、bi-lstm层、第三lstm层和第四lstm层,第一lstm层接收输入的视频序列并学习其时间依赖关系,捕捉视频序列的短期依赖关系,并传递给下一层;第二lstm层进一步学习输入的视频序列的长期依赖关系,记忆更长的时间间隔内的信息,并将信息传递给下一层;bi-lstm层的正向lstm层处理输入序列的顺序,bi-lstm层的反向lstm层处理输入序列的逆序;第三lstm层进一步提取输入序列中的时间依赖关系,并捕捉更抽象的特征;第四lstm层在较高的抽象层次上编码输入序列,并生成最终的时间序列特征表示。
15、优选地,所述生成伪标签的方法为:计算前后相邻帧图像的特征向量之间的相似度得分,根据相似度得分的值生成伪标签;
16、相似度得分高的帧图像标记为1作为伪标签,相似度得分低的帧图像标记为0并过滤掉;
17、将前一帧图像的伪标签检测结果投影到当前帧图像中,生成一组候选伪标签,并利用前后帧的相似度得分计算选择最佳的伪标签;
18、所述相似度得分的计算方法为:预测值与真实值之间差的平方的平均值:
19、mse=(1/n)*σ(actual-prediction)2
20、其中,∑为求和符号;n为像素总数,即前后帧中像素的个数;actual为前一帧中的像素灰度值,看作是实际数据值;prediction为后一帧中的像素灰度值,看作是预测数据值。
21、优选地,所述选择置信度高的样本的方法为:
22、对于伪标签和真实标签组成的训练数据集中的每个样本,利用标签噪声的信息计算置信度得分;置信度计算公式为:
23、c=p(1-p)/m
24、其中,c表示置信度得分,p表示带有噪声标签的样本值也就是置信度值,它的值的范围是0~1,m表示样本总量。
25、优选地,所述步骤s4的实现方法为:引入一个因子ρ来动态调整样本的梯度;随着训练的进行,将因子ρ从0线性增加到1;在训练过程中,对于具有高置信度得分的样本,将因子ρ设置为1;
26、损失函数lcsd为:
27、
28、其中,n为像素个数,φ(xi)为像素xi的显著性预测值;
29、lcsd/φ(xi)的偏导数为:
30、
31、其中,符号函数sign(ki)属于{-1,1}分别为负值和正值,ki表示样本的索引值,sign(ki)根据索引值ki来决定输出的符号。
32、优选地,还包括步骤s7:根据显著性检测结果生成新的伪标签,循环执行步骤s5和步骤s6,直到将lstm模型训练充分且稳定;每一帧图像的显著性检测结果为每个像素的显著性得分。
33、与现有技术相比,本发明产生的有益效果为:
34、1)基于时间序列特征的伪标签生成:利用lstm网络对视频中的时间序列信息进行建模,并结合图像特征和语义信息,自动化生成伪标签进行训练。相比于现有方法需要手动标注大量数据的方式,本发明能够显著减少标注数据的需求量和成本,同时还能减少标注数据中的噪声和主观性问题,提高了lstm模型的泛化性能。本发明通过增加伪标签和置信度感知显著性提取,提高困难样本的检测精度,进一步优化骨干网络生成的预测图像,使其内部更加均匀,边界更加清晰。
35、2)提高检测精度和稳定性:本发明能够有效地提高视频显著性检测的准确性和稳定性。相比于传统方法和现有基于lstm的方法,本发明在复杂场景和动态背景下表现更为出色。
- 还没有人留言评论。精彩留言会获得点赞!