基于公共空间服务的数据采集和项目运营分析系统的制作方法
本发明属于项目运营分析领域,具体是指一种基于公共空间服务的数据采集和项目运营分析系统。
背景技术:
1、线下公共空间服务项目运营活动的竞争越来越激烈,激烈的竞争促进了数据采集和项目运营分析系统的发展,如何采集线下公共空间服务项目运营活动的相关数据并进行业务层面所需要的数据分析也受到越来越多的关注。
2、现有的项目运营分析系统基本都是针对线上运营活动,线上运营活动通常使用网站埋点的方法获取用户的行为数据。但线下公共空间服务项目运营活动与线上运营活动不同,线下公共空间服务项目运营活动缺少针对现场部署并采集特定数据的硬件设备系统;
3、现有的数据采集和项目运营分析系统依托于前置获得的直接输入,数据较为原始,格式杂乱,有空数据、脏数据和重复数据的存在。原始数据没有经过统一的整合与清洗,难以保证每次线下公共空间服务项目运营活动收集到的信息种类和详细条目是规范的且能被数据存储层所接受的;
4、数据分析经常需要对比之前线下公共空间服务项目运营活动的历史数据,针对本次线下公共空间服务项目运营活动的数据指标的效果评估,可以在排除每次线下公共空间服务项目运营活动不确定性和不可复现的基础上,确认此次针对线下公共空间服务项目运营活动的优化修改方案是否对线下公共空间服务项目运营活动举办的效果产生了影响,是否具有正面作用,是否获得了正面增益等问题仅凭单次活动的数据对比或者个人积累的活动经验来做出一个主观性的判决是不准确的;
5、大量的数据流使人感到疲惫,文字承载的信息有限,人不必可避免地产生视觉疲劳,抵触单纯的文本数据,导致决策管理人员无法获取准确的数据信息并做出项目决策。
技术实现思路
1、针对上述情况,为克服现有技术的缺陷,本发明提供了一种基于公共空间服务的数据采集和项目运营分析系统。
2、本发明采用人体感应模块和人脸识别模块别相结合的方式,科学部署终端节点设备,提供一种基于公共空间的人流量数据采集方法。本发明采用python生态第三方库对原始数据进行清洗,采用了一种基于统计学原理的ab测试方案,提供一种借助power bi的信息流可视化方案,有效提高决策者输入输出信息的体验。
3、本发明采取的技术方案如下:本发明提供了一种基于公共空间服务的数据采集和项目运营分析系统,采用电商指标分析方法进行数据采集和项目运营分析,所述基于公共空间服务的数据采集和项目运营分析系统包括数据采集层、数据处理层、数据存储层、数据分析层和数据展示层。
4、所述数据采集层采用终端节点设备进行数据采集,数据采集层的数据包括终端节点设备采集的数据信息和后台订单记录,终端节点设备包括以线下公共空间服务项目运营活动为中心、预设距离为半径的边界设置的多对人体感应模块a、线下公共空间服务项目运营活动的内场入口处设置的人体感应模块b和线下公共空间服务项目运营活动的内场入口处设置的人脸识别模块。
5、将人体感应模块a采集到的原始数据定义为数据a,数据a即以项目运营活动为中心、预设距离为半径的边界人流量;将人体感应模块b采集到的原始数据定义为数据b,数据b即内场入口处人流量;将人脸识别模块采集到的原始数据定义为数据c,数据c包括用户id_a,人脸信息、进入进出标记和记录时间;将后台订单记录定义为数据d,数据d包括编号、订单id、用户id_b、下单时间、品类号、件数和订单总价。
6、终端节点设备采集的数据a、数据b、数据c和数据d和后台订单记录通过ieee802.15.1传递给网关,网关采用tcp/ip协议链接网络服务器;
7、所述数据处理层整合数据a、数据b、数据c和数据d为连续用户行为数据,对连续用户行为数据进行清洗和预处理操作,得到初步观测指标;
8、所述数据存储层由网关和网络服务器组成,网络服务器设有数据库,存储连续用户行为数据和初步观测指标;
9、所述数据分析层调用并分析连续用户行为数据和初步观测指标形成高级观测指标,使用rfm模型对用户进行分类,形成用户分类数据;
10、所述数据展示层采用power bi数据分析工具与数据库建立连接,完成可视化展示;
11、所述电商指标分析方法包括以下步骤:
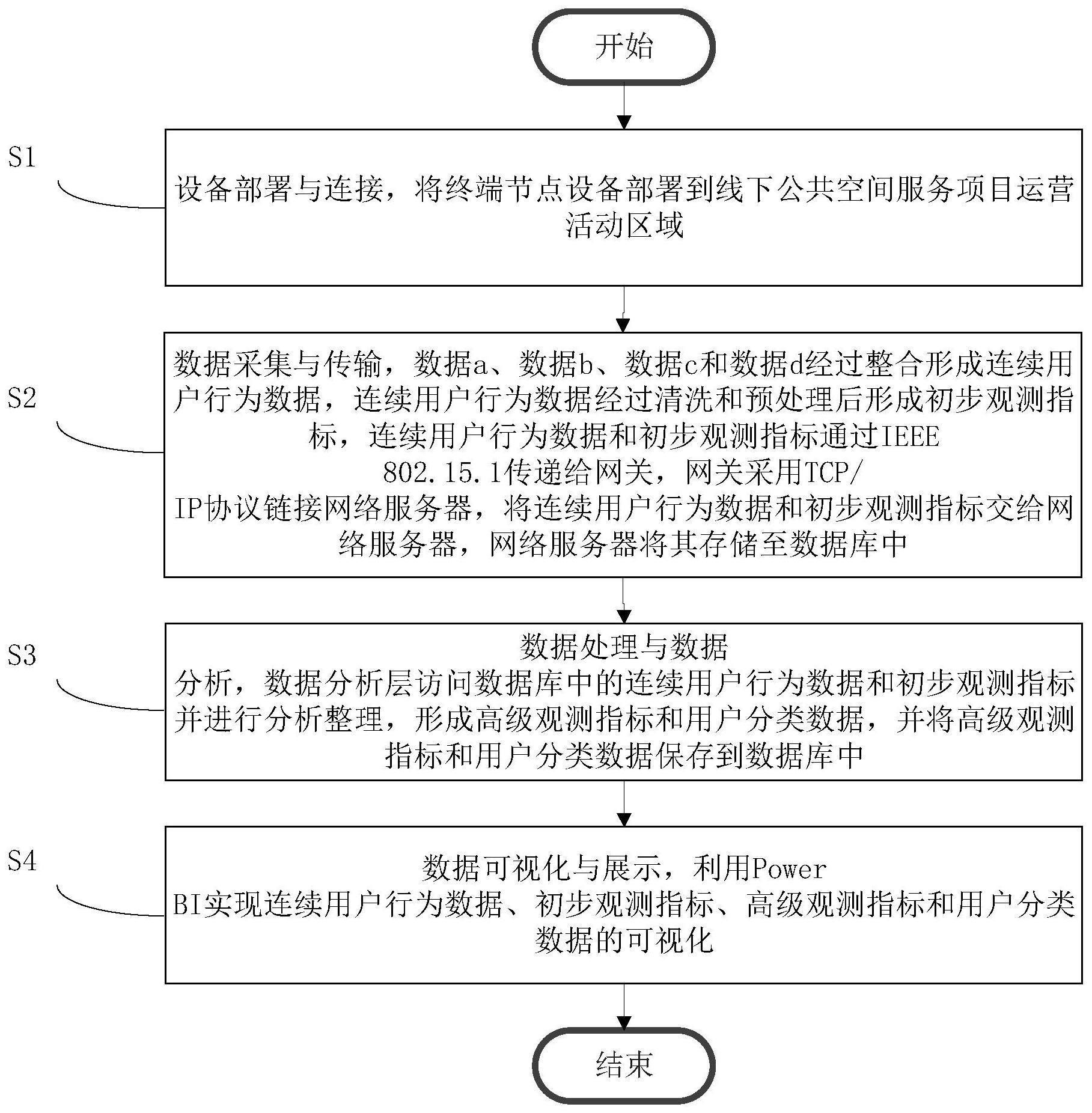
12、步骤s1:设备部署与连接,将终端节点设备部署到线下公共空间服务项目运营活动区域;
13、步骤s2:数据采集与传输,数据a、数据b、数据c和数据d经过整合形成连续用户行为数据,连续用户行为数据经过清洗和预处理后形成初步观测指标,连续用户行为数据和初步观测指标通过ieee 802.15.1传递给网关,网关采用tcp/ip协议链接网络服务器,将连续用户行为数据和初步观测指标交给网络服务器,网络服务器将其存储至数据库中;
14、步骤s3:数据处理与数据分析,数据分析层访问数据库中的连续用户行为数据和初步观测指标并进行分析整理,形成高级观测指标和用户分类数据,并将高级观测指标和用户分类数据保存到数据库中;
15、步骤s4:数据可视化与展示,利用power bi实现连续用户行为数据、初步观测指标、高级观测指标和用户分类数据的可视化。
16、作为本方案的进一步改进,在步骤s1中,设备部署与连接具体包括以下步骤:
17、步骤s11:在线下公共空间服务项目运营活动辐射范围区域设置人体感应模块a,采集数据a;
18、步骤s12:在线下公共空间服务项目运营活动的内场入口处设置人体感应模块b和人脸识别模块,采集数据b和数据c;
19、作为本方案的进一步改进,在步骤s11和s12中,为了获得更多用户行为数据,将数据a、数据b、数据c和数据d整合关联,作为多个独立用户在线下公共空间服务项目运营活动的连续用户行为数据进行分析;
20、步骤s13:将连续用户行为数据传递给数据处理层。
21、作为本方案的进一步改进,在步骤s2中,为了减小数据存储层和数据分析层的压力,只有经过清洗的连续用户行为数据才能传递给网关并存储至网络服务器的数据库中,清洗方法包括以下步骤:
22、步骤s21:使用python生态科学计算第三方库pandas、numpy和scipy对连续用户行为数据进行清洗,有效去除空数据、脏数据和重复数据,提高数据的规范性和统一性;
23、步骤s22:经过清洗的连续用户行为数据导出为csv格式,方便数据存储层存储和数据分析层读取等后续处理。
24、作为本方案的进一步改进,在步骤s22中,为了减小数据存储层和数据分析层的压力,在连续用户行为数据文件导出csv格式并存储至网络服务器之前,采用分布式计算,在连续用户行为数据经过清洗后,直接进行预处理操作,预处理包括以下步骤:
25、步骤s221:初步分析计算经过清洗后的连续用户行为数据,形成初步观测指标,初步观测指标包括付费人数、消费总量gmv、最终成单量、运营转化率、访问时长、pv访问量和uv独立访客;
26、步骤s222:计算运营转化率、访问时长、pv访问量和uv独立访客,所用公式如下:
27、
28、式中,ocr代表运营转化率,pf_entrance代表线下公共空间服务项目运营活动的内场入口处人流量,pf_range代表以线下公共空间服务项目运营活动为中心、预设距离为半径的边界人流量;
29、
30、式中,lov代表访问时长,dt代表内场入口离开时间,et代表内场入口进入时间;
31、pv访问量:对一段时间内的所有访问线下公共空间服务项目运营活动的客户总数;
32、uv独立访客:对一段时间内的所有访问线下公共空间服务项目运营活动的客户去重后的总数。
33、作为本方案的进一步改进,在步骤s3中,优化修改方案是对历史项目运营活动的效果提出优化建议所形成的方案,本发明提出在数据分析和数据处理前增加ab测试作为判定优化修改方案是否有效可信的前置条件;在本发明中,将清洗后的连续用户行为数据作为样本,将清洗后的连续用户行为数据的数量作为样本量;在本发明中,最小样本量是指科学有效地表达优化修改方案对项目运营活动举办的效果产生了影响所需要的最少数量;只有经过ab测试,确定样本量大于或等于最小样本量,才允许数据分析层调用该线下公共空间服务项目运营活动的连续用户行为数据和初步观测指标,优化修改方案获得的结论才是可信的;ab测试具体方法包括以下步骤:
34、步骤s31:收集调用优化修改方案前的样本,作为对照组;
35、步骤s32:分析优化修改方案前的样本,作出优化改进的假设,提出优化建议;
36、步骤s33:确定绩效指标,绩效指标包括消费总量gmv、复购率、arpu人均消费价格和arppu每付费用户平均收益;
37、步骤s34:将连续用户行为数据和初步观测指标记为资源,将绩效指标记为奖励,采用基于ucb和条件推理树的ab测试资源动态分配算法进行优化修改方案;
38、作为本方案的进一步改进,在步骤s34中,基于ucb和条件推理树的ab测试资源动态分配算法具体包括以下步骤:
39、步骤s341:在活动开始前,将历史项目运营活动收集的资源作为训练集;条件推理树的目的是正确地识别出哪些资源和奖励之间的联系是类似的;首先对训练集的因变量(奖励)和每个自变量(资源)进行卡方检验,计算p值公式如下:
40、p=1-p(χ2>χ02)
41、其中,χ2是卡方统计量;χ02是理论值;p(χ2>χ02)是卡方分布的概率密度函数;
42、步骤s342:选择p值小于阈值的自变量进入条件推理树模型;
43、步骤s343:确定最佳预测变量;在进入条件推理树模型的自变量中,选择与因变量的相关性最高的那个自变量作为第一次执行二进制拆分的自变量,即最佳预测变量,用置换检验来确定最佳预测变量;置换检验步骤如下:
44、步骤s3431:首先计算出自变量和因变量的均值和标准差,将自变量中的部分值替换为来自因变量相应的部分值,计算出置换后的均值和标准差;
45、步骤s3432:比较自变量的均值和标准差与置换后的因变量的均值和标准差之间的差异,如果这些差异显著,那么就认为自变量和因变量分布不同,相关性差;如果差异不显著,则认为自变量和因变量相关性强;
46、步骤s344:重复步骤s342至步骤s343,建立细分条件推理树模型,模型的每个叶节点就是创建的多个识别同构组,简称组;
47、步骤s345:每个组由ucb执行动态分配;在活动开始后,将本次项目运营活动收集的资源作为测试集,对每个识别同构组分配一个ucb,每个ucb都是独立的,可以随时停止本识别同构组的资源分配,ucb算法如下:
48、步骤s3451:将第i组得到的资源数记为ni;如果第i组ni为0,则将本次资源分配给该组;如果没有资源数为0的,则将本次资源分配给置信区间上限最大的组,计算置信区间上限最大的识别同构组的公式如下:
49、
50、其中,i为置信区间上限最大的组号,argmax表示该列表中元素最大值的组号;k是组的数量;n是资源分配总量;是第j组的平均奖励;nj是第j组得到的资源数;
51、步骤s3452:更新置信区间上限最大的组号第i组的平均奖励和置信区间上限最大的组号第i组得到的资源数ni,计算公式如下:
52、
53、ni=ni+1
54、其中,r为新获得的奖励;
55、步骤s3453:第i组获得新的奖励后,ucb更新奖励r;
56、步骤s346:重复步骤s345,直至所有资源完成动态分配;
57、基于ucb和条件推理树的ab测试资源动态分配算法可以在资源有限的项目运营活动中,同时实施并检验多个优化修改方案;并且,在项目运营活动进行过程中,该算法能够及时检测并停止为某个正面效果不明显甚至具有负面效果的优化修改方案分配资源,在寻找最佳优化修改方案的过程中避免造成资源浪费。
58、步骤s35:计划并实施应用优化修改方案后的线下公共空间服务项目运营活动,并采集优化修改方案后的样本,作为实验组;
59、步骤s36:每个组的最小样本量计算如下:
60、
61、式中,δ代表的是预期实验组和对照组两组数据的差值,α是犯第一类错误的概率,通常α取值0.05,即置信度是(1-α)是0.95%,β是第二类错误的概率,β取值0.2,即统计功效的取值1-β是0.8,σ代表的是样本的标准差,衡量的是样本的波动性,可以由计算样本的标准差计算得到;
62、当绩效指标为绝对值/比率指标时,样本的标准差σ2的计算公式:
63、σ2=pa(1-pa)+pb(1-pb)
64、式中,pa是对照组的观测数据;pb为实验组的观测数据;
65、步骤s37:判断优化修改方案效果的可信性和有效性,即判断样本量是否已经大于或等于所需要的最小样本量:如果样本量大于或等于所需要的最小样本量,则能够以1-α的置信度得出优化修改方案对项目运营活动的效果产生影响的结论;如果样本量小于所需要的最小样本量,则得出优化修改方案对项目运营活动的效果产生影响的结论是不准确的,样本量需要大于或等于最小样本量才允许接下来数据分析层的操作。
66、进一步地,在步骤s37中,所述数据处理与数据分析,数据分析层访问网络服务器收集到的连续用户行为数据和初步观测指标,并对其进行分析整理,形成高级观测指标,高级观测指标的生成包括以下步骤:
67、步骤s371:高级观测指标包括不同时间区间内的场内留存人数、弹出率、复购率、arpu人均消费价格和arppu每付费用户平均收益,所用公式如下:
68、弹出率:判断符合访问时长小于设定时长阈值的记录总数与内场入口处人流量的比值;
69、复购率:在某时间窗口内重复消费用户(消费两次及以上的用户)在总消费用户中所占比;
70、
71、式中,arpu代表每用户平均收益,gmv代表消费总量,pv代表访问量;
72、
73、式中,arppu代表每付费用户平均收益,gmv代表消费总量,nop代表付费人数;
74、步骤s372:统计高级观测指标与历史高级观测指标的时间环比和时间同比,采用rfm模型对用户进行分类获得用户分类数据,并将分析统计后的高级观测指标和用户分类数据传输到数据展示层。
75、作为本方案的进一步改进,在步骤s372中,使用rfm模型对用户进行分类,对连续用户行为数据和初步观测指标进行分析实现用户画像,有效识别客户,合理分配运营资源,达到用户价值和产品目标的最大化,具体包括以下步骤:
76、步骤s3721:统计所有用户数据,按照最近一次消费时间间隔、消费频率、消费金额分类统计,统计原则如下:
77、对于最近1次消费时间间隔,即r,上一次消费离得越近,也就是r的值越小,用户价值越高;
78、对于消费频率,即f,购买频率越高,也就是f的值越大,用户价值越高;
79、对于消费金额,即m,消费金额越高,也就是m的值越大,用户价值越高;
80、比如:一位客户最近消费时间间隔较近,r=0;最近消费频率较高,f=1;消费金额较高,m=1,则这位客户属于重要保持客户;
81、
82、表一
83、步骤s3722:归类整理所有用户分类的后台订单记录和用户数量,形成用户分类数据,并传输至数据展示层;
84、作为本方案的进一步改进,在步骤s3721中,使用基于k-means++聚类算法对普通的rfm模型进行改进,具体包括以下步骤:
85、步骤s37211:将每条连续用户行为数据和初步观测指标标记为一个样本点,随机选择一个样本点作为第一个初始化的聚类质心;
86、步骤s37212:计算每一个样本点与已经初始化的聚类质心之间的欧几里得距离,欧几里得距离计算公式如下:
87、
88、其中,d为欧几里得距离;m为欧氏空间的维度;z为任一样本点;x为聚类质心;表示样本点z的第j个坐标;xj表示聚类质心x的第j个坐标;
89、步骤s37213:使用加权概率分布随机选择一个新的样本点作为新的聚类质心,欧几里得距离较大的点,被选取作为聚类质心的概率较大;
90、步骤s37214:重复上述过程,直到k个聚类质心都被确定;
91、步骤s37215:属于同一个聚类质心的所有样本点的集合称为该聚类质心的点群,所有样本点选择该样本点到k个聚类质心的欧几里得距离最短的聚类质心,则该样本点属于该聚类质心的点群;
92、步骤s37216:更新聚类质心,即移动聚类质心到属于该聚类质心的点群的中心,求新聚类质心z的坐标,所用公式如下:
93、
94、其中,zj为聚类质心z的第j个坐标;n为该聚类质心的点群中所有样本点的数量;为该点群的第i个样本点的第j个坐标;
95、步骤s37217:重复步骤s36215到s36216,直到聚类质心没有移动;
96、步骤s37218:使用轮廓系数对步骤s37211到步骤s37217中得到的k个聚类进行评估,计算轮廓系数计算公式为:
97、
98、其中,s(i)是样本点zi的轮廓系数;a(i)是样本点zi对同一点群其他样本点的平均距离,称为凝聚度;b(i)是样本点zi到最临近簇所有样本点的平均距离,称为分离度;
99、最临近簇就是离zi样本点平均距离c(i)最小的点群,其中最临近簇定义如下:
100、
101、其中,ck是任一点群;c(i)是样本点zi到最临近簇的平均距离;p为点群ck中的任一样本点;n为点群ck的样本点的总量;
102、求出点群个数为k时所有样本点的轮廓系数再求平均值,得到平均轮廓系数,平均轮廓系数的取值在[-1,1],由轮廓系数公式可以观察出,凝聚度a(i)越小,分离度b(i)越大,分类效果越好,平均轮廓系数也越大;
103、步骤s37219:重复步骤s36211到s36218,取分类效果最好的k值,即平均轮廓系数最大时的k值的分类作为最佳聚类,并输出最佳聚类各个点群的样本点集合作为用户分类数据,传输至数据表示层。
104、进一步地,在步骤s4中,所述数据可视化与展示,包括以下内容:
105、步骤s41:将连续用户行为数据、初步观测指标、高级观测指标和用户分类数据以csv的格式导入到power bi中,并利用power bi数据分析工具的power query模块对其进行整理;
106、步骤s42:通过sql server构建由连续用户行为数据、初步观测指标、高级观测指标和用户分类数据组成的数据集,并将所述power bi与所述sql server连接,完成powerbi与sql server的关系建立;
107、步骤s43:利用power bi数据分析工具的power view模块对数据集进行报表绘制,完成可视化展示。
108、采用上述方案本发明取得的有益效果如下:
109、(1)针对项目运营活动缺少针对线下公共空间服务数据采集方案的问题,本发明采用人体感应模块和人脸识别模块相结合的方式,将终端节点设备部署在内场入口处和以线下公共空间服务项目运营活动为中心、预设距离为半径所形成的范围边界,以提供一种基于公共空间服务的人流量数据采集方法,降低企业的投资成本的同时,也方便终端节点设备的部署和回收。
110、(2)针对终端节点设备采集到的数据较为原始,格式杂乱,存在脏数据,空数据,重复性数据,以及原始数据没有经过统一的清洗和优化的问题,采用python生态第三方库对原始数据进行预处理,保证数据的完整性和规范性。
111、(3)针对线下公共空间服务项目运营活动的优化修改方案对线下公共空间服务项目运营活动举办的效果是否产生了影响,是否具有正面作用,是否获得了正面增益等问题,本发明采用了一种基于统计学原理的ab测试方案。有效避免了仅凭单次活动的数据对比或者个人积累的活动经验做出主观判决的可能性,排除所述线下公共空间服务项目运营活动不确定性和不可复现的风险,科学地量化优化修改方案的效果。
112、(4)针对大量的数据流使人感到疲惫,文字承载的信息有限,人不必可避免地产生视觉疲劳,抵触单纯的文本数据,导致决策管理人员无法获取准确的数据信息并做出项目决策的问题。本发明提供了一种借助power bi的信息流可视化方案。有效增加了数据可阅读性,提高了决策者输入输出信息的体验。
- 还没有人留言评论。精彩留言会获得点赞!