告警日志推送方法、装置、计算机设备及存储介质与流程
本发明涉及告警信息处理,具体涉及告警日志推送方法、装置、计算机设备及存储介质。
背景技术:
1、为了保证服务器等系统运维和故障排查的顺利进行,通常会将系统运行过程中记录的大量告警日志存储在数据库中,如果这些告警日志得不到及时处理,庞大的告警日志就会长期累积在数据库,占用大量的存储空间,对存储空间、电路和传输网络带宽带来难以想象的沉重负担,也会影响系统性能。
2、目前,对告警日志的处理仍然依赖于运维工程师的人工分析判别。运维工程师在处理告警日志的过程中,通常定义相关规则从海量的告警日志中选取相同故障的告警,进行批量处理。然而,手动定义关联规则很难覆盖告警日志之间的所有关联,导致告警日志的处理效率较低。
技术实现思路
1、有鉴于此,本发明提供了一种告警日志推送方法、装置、计算机设备及存储介质,以解决告警日志的处理效率较低的问题。
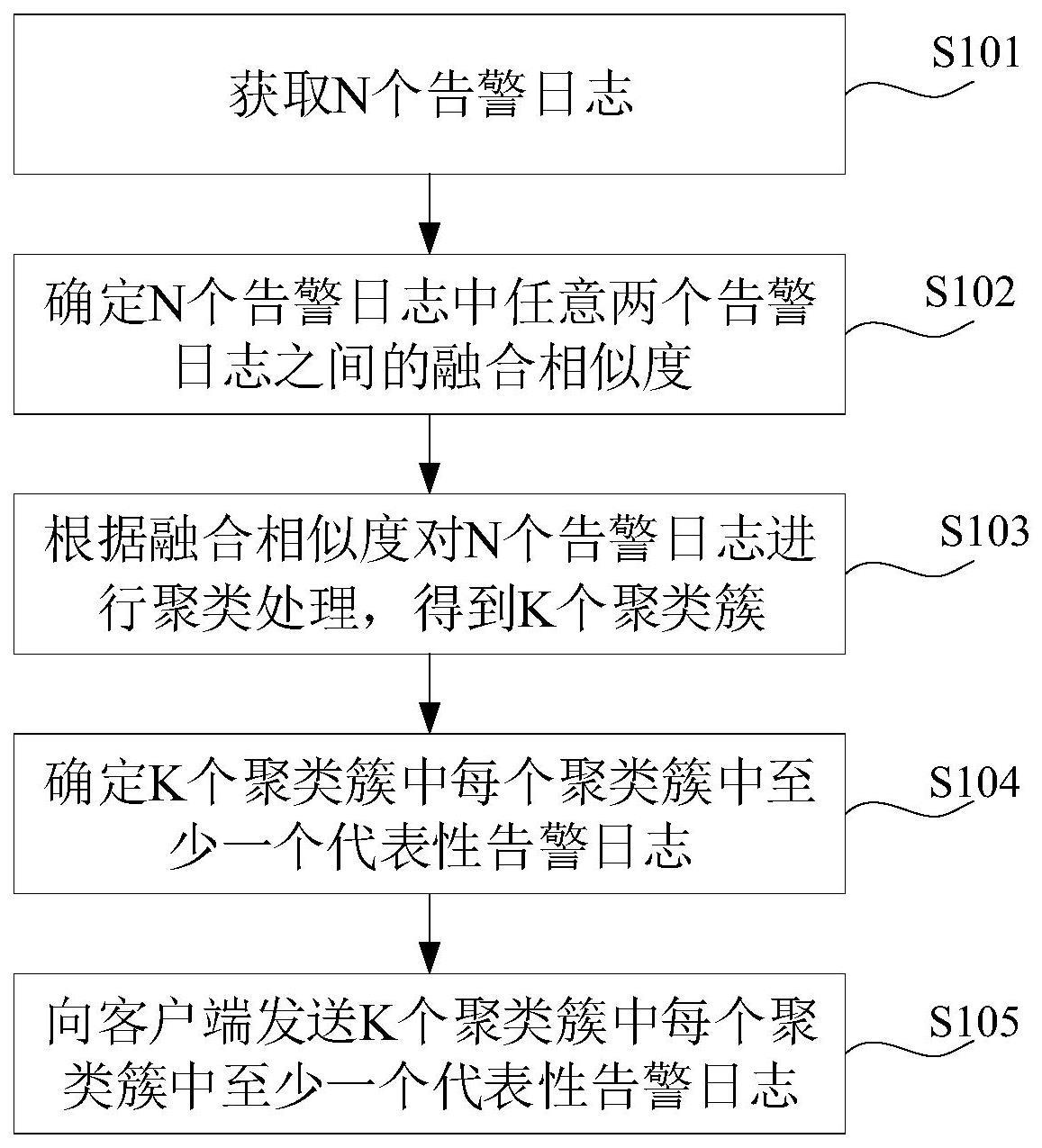
2、第一方面,本发明提供了一种告警日志推送方法,所述方法应用于存储设备,所述方法包括:获取n个告警日志,n为大于或者等于2的整数;确定所述n个告警日志中任意两个告警日志之间的融合相似度,所述融合相似度用于表征所述任意两个告警日志之间的相似程度;根据所述融合相似度对所述n个告警日志进行聚类处理,得到k个聚类簇,k为整数,且1≤k<n,所述聚类簇中所述任意两个告警日志之间的所述融合相似度大于预设阈值;确定所述k个聚类簇中每个聚类簇中至少一个代表性告警日志,所述代表性告警日志为所述聚类簇中与其他告警日志的平均融合相似度最大的告警日志;向客户端发送所述k个聚类簇中每个聚类簇中所述至少一个代表性告警日志。
3、本实施例提供的告警日志推送方法,在获取多个告警日志之后,首先确定多个告警日志中任意两个告警日志之间的融合相似度。其次,根据融合相似度对多个告警日志进行聚类处理,能够准确对反映故障的不同方面的告警日志进行归类。然后确定多个聚类簇中每个聚类簇中至少一个代表性告警日志,向客户端发送多个聚类簇中每个聚类簇中至少一个代表性告警日志,减少运维人员需要分析的告警日志的数量。即通过上述步骤,存储设备能够识别相似或具有关联关系的告警日志,对告警日志进行归类,并且能够减少运维人员需要分析的告警日志的数量,减轻运维人员的工作负担,提高告警信息的处理效率和准确性。
4、在一种可选的实施方式中,在所述确定所述n个告警日志中任意两个告警日志之间的融合相似度之前,所述方法还包括:对所述n个告警日志进行预处理,得到所述n个告警日志中每个告警日志的有效词元集合,所述有效词元集合包括至少一个有效词元,所述预处理包括日志排序、日志去重、日志清洗、日志分词、去停用词、词元标准化中的至少一项;所述确定所述n个告警日志中任意两个告警日志之间的融合相似度,包括:根据所述有效词元集合确定所述n个告警日志中任意两个告警日志之间的所述融合相似度。
5、本实施例提供的告警日志推送方法,在确定n个告警日志中任意两个告警日志的融合相似度之前,先对n个告警日志进行预处理,能够减少原始告警日志中的噪声,降低确定融合相似度的难度,提高对告警日志的处理效率。
6、在一种可选的实施方式中,所述根据所述有效词元集合确定所述n个告警日志中任意两个告警日志之间的所述融合相似度,包括:将第i个告警日志的所述有效词元集合中每个有效词元输入连续词袋模型,得到每个有效词元的词元向量,i=1,2,……,n;根据词频-逆文档频率模型确定所述第i个告警日志的所述有效词元集合中每个有效词元的词频特征;根据所述有效词元集合中每个有效词元的所述词元向量和所述词频特征确定所述第i个告警日志的语义特征;根据第一告警日志的语义特征和第二告警日志的语义特征确定所述第一告警日志和所述第二告警日志的文本相似度,所述第一告警日志为所述任意两个告警日志中的其中一个告警日志,所述第二告警日志为所述任意两个告警日志中的另一个告警日志;根据用于描述所述存储设备的架构的软件拓扑图和硬件拓扑图确定所述第一告警日志和所述第二告警日志的拓扑相关度;根据所述文本相似度和所述拓扑相关度确定所述第一告警日志和所述第二告警日志的所述融合相似度。
7、本实施例通过连续词袋模型挖掘有效词元的词义特征,基于词频-逆文档频率模型分析有效词元的词频特征,然后融合词义特征和词频特征能够更准确的分析告警日志的语义,再通过告警对象字段将告警日志与存储设备的软件和硬件拓扑联系起来,以空间维度分析告警日志之间的相关性,能够更准确的确定融合相似度,进而提高聚类的准确性。另外,本实施基于连续词袋模型和词频-逆文档频率模型得到的文本相似度确定融合相似度,并通过聚类算法对n个告警日志进行聚类处理,无需运维专家针对不同的场景和条件配置不同的规则,对运维领域知识要求低,能降低聚合规则条数,同时适应新场景的能力强,新增故障日志也不需要额外再配置新的聚合规则。
8、在一种可选的实施方式中,所述根据所述文本相似度和所述拓扑相关度确定所述第一告警日志和所述第二告警日志的所述融合相似度,包括:根据权重系数、所述文本相似度和所述拓扑相关度,通过如下公式确定所述融合相似度:
9、similarity(a,b)=α×texual(a,b)+(1-α)×correlation(a,b)
10、其中,a表示所述第一告警日志,b表示所述第二告警日志,similarity(a,b)表示所述第一告警日志和所述第二告警日志的所述融合相似度,α表示所述权重系数,texual(a,b)表示所述第一告警日志和所述第二告警日志的所述文本相似度,correlation(a,b)表示所述第一告警日志和所述第二告警日志的所述拓扑相关度。
11、在一种可选的实施方式中,所述根据所述有效词元集合中每个有效词元的所述词元向量和所述词频特征确定所述第i个告警日志的语义特征,包括:
12、根据所述有效词元集合中每个有效词元的所述词元向量和所述词频特征,通过如下公式确定所述第i个告警日志的语义特征:
13、
14、其中,si为第i个告警日志的语义特征,为wji的词元向量,为wji的词频特征,wji为第i个告警日志的所述有效词元集合中的第j个有效词元,l为所述有效词元集合中词元的总数量。
15、在一种可选的实施方式中,所述根据第一告警日志的语义特征和第二告警日志的语义特征确定所述第一告警日志和所述第二告警日志的文本相似度,包括:
16、根据第一告警日志的语义特征和第二告警日志的语义特征,通过如下公式确定所述文本相似度:
17、
18、其中,a为所述第一告警日志,b为所述第二告警日志,texual(a,b)为所述第一告警日志和所述第二告警日志之间的所述文本相似度,sa为所述第一告警日志的语义特征,sb为所述第二告警日志的语义特征,t表示向量的转置,‖·‖2表示l2范数。
19、在一种可选的实施方式中,所述根据所述融合相似度对所述n个告警日志进行聚类处理,得到k个聚类簇,包括:根据基于密度的聚类算法,以所述融合相似度为距离度量对所述n个告警日志进行聚类处理,得到所述k个聚类簇。
20、由于基于密度的聚类算法可以不用指定类别数,本实施通过基于密度的聚类算法对n个告警日志进行聚类处理,能够提高n个告警日志的聚类速度。
21、在一种可选的实施方式中,所述确定所述k个聚类簇中每个聚类簇中的至少一个代表性告警日志,包括:
22、通过如下公式确定所述k个聚类簇中每个聚类簇的所述代表性告警日志:
23、
24、其中,centroid为所述代表性告警日志,n表示对应聚类簇中告警日志的总数量,c和d为对应聚类簇中任意两个不相同的告警日志,1≤c≤n,1≤d≤n。
25、在一种可选的实施方式中,在所述确定所述k个聚类簇中每个聚类簇中的至少一个代表性告警日志之后,所述方法还包括:删除冗余告警日志,所述冗余告警日志为所述k个聚类簇中每个聚类簇中除所述至少一个代表性告警日志之外的告警日志。
26、本实施通过删除冗余日志能够节省存储设备的空间。
27、在一种可选的实施方式中,所述获取n个告警日志,包括:从轻量级采集客户端获取所述n个告警日志。
28、第二方面,本发明提供了一种告警日志的推送装置,所述装置包括:获取模块,用于获取n个告警日志,n为大于或者等于2的整数;第一处理模块,用于确定所述n个告警日志中任意两个告警日志之间的融合相似度,所述融合相似度用于表征所述任意两个告警日志之间的相似程度;第二处理模块,用于根据所述融合相似度对所述n个告警日志进行聚类处理,得到k个聚类簇,k为整数,且1≤k<n,所述聚类簇中所述任意两个告警日志之间的所述融合相似度大于预设阈值;第三处理模块,用于确定所述k个聚类簇中每个聚类簇中至少一个代表性告警日志,所述代表性告警日志为所述聚类簇中与其他告警日志的平均融合相似度最大的告警日志;发送模块,用于向客户端发送所述k个聚类簇中每个聚类簇中所述至少一个代表性告警日志。
29、在一种可选的实施方式中,所述装置还包括:第四处理模块,用于对所述n个告警日志进行预处理,得到所述n个告警日志中每个告警日志的有效词元集合,所述有效词元集合包括至少一个有效词元,所述预处理包括日志排序、日志去重、日志清洗、日志分词、去停用词、词元标准化中的至少一项;所述第一处理模块包括:第一处理单元,用于根据所述有效词元集合确定所述n个告警日志中任意两个告警日志之间的所述融合相似度。
30、在一种可选的实施方式中,所述第一处理单元包括:第一处理子单元,用于将第i个告警日志的所述有效词元集合中每个有效词元输入连续词袋模型,得到每个有效词元的词元向量,i=1,2,……,n;第二处理子单元,用于根据词频-逆文档频率模型确定所述第i个告警日志的所述有效词元集合中每个有效词元的词频特征;第三处理子单元,用于根据所述有效词元集合中每个有效词元的所述词元向量和所述词频特征确定所述第i个告警日志的语义特征;第四处理子单元,用于根据第一告警日志的语义特征和第二告警日志的语义特征确定所述第一告警日志和所述第二告警日志的文本相似度,所述第一告警日志为所述任意两个告警日志中的其中一个告警日志,所述第二告警日志为所述任意两个告警日志中的另一个告警日志;第五处理子单元,用于根据用于描述所述存储设备的架构的软件拓扑图和硬件拓扑图确定所述第一告警日志和所述第二告警日志的拓扑相关度;第六处理子单元,用于根据所述文本相似度和所述拓扑相关度确定所述第一告警日志和所述第二告警日志的所述融合相似度。
31、在一种可选的实施方式中,所述第六处理子单元包括:第一计算单元,用于根据权重系数、所述文本相似度和所述拓扑相关度,通过如下公式确定所述融合相似度:
32、similarity(a,b)=α×texual(a,b)+(1-α)×correlation(a,b)
33、其中,a表示所述第一告警日志,b表示所述第二告警日志,similarity(a,b)表示所述第一告警日志和所述第二告警日志的所述融合相似度,α表示所述权重系数,texual(a,b)表示所述第一告警日志和所述第二告警日志的所述文本相似度,correlation(a,b)表示所述第一告警日志和所述第二告警日志的所述拓扑相关度。
34、在一种可选的实施方式中,所述第二处理模块包括:第二处理单元,用于根据基于密度的聚类算法,以所述融合相似度为距离度量对所述n个告警日志进行聚类处理,得到所述k个聚类簇。
35、在一种可选的实施方式中,所述装置还包括:删除模块,用于删除冗余告警日志,所述冗余告警日志为所述k个聚类簇中每个聚类簇中除所述至少一个代表性告警日志之外的告警日志。
36、在一种可选的实施方式中,所述获取模块还包括:第一获取单元,用于从轻量级采集客户端获取所述n个告警日志。
37、第三方面,本发明提供了一种计算机设备,包括:存储器和处理器,存储器和处理器之间互相通信连接,存储器中存储有计算机指令,处理器通过执行计算机指令,从而执行上述第一方面或其对应的任一实施方式的方法。
38、第四方面,本发明提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机指令,计算机指令用于使计算机执行上述第一方面或其对应的任一实施方式的方法。
- 还没有人留言评论。精彩留言会获得点赞!