文本处理方法、装置、计算设备、以及计算机程序产品与流程
本公开涉及计算机,具体地,涉及一种文本处理方法、装置、计算设备、计算机可读存储介质以及计算机程序产品。
背景技术:
1、随着计算机技术和互联网的不断发展,各行各业的从业人员越来越多地转向数字化办公,与此同时,海量数据的产生使得相应从业人员越来越难以获取其感兴趣或对其有价值的信息。例如,在投研领域(即,投资银行、证券公司等金融机构的业务相关领域),随着相关机构的工作范围不断扩大,为了帮助做出合理的投资决策,相关投资人员需要阅读和分析大量相关文档(例如,关于公司、行业的研究调查报告),在此过程中,投资人员往往需要对某个行业(例如,新能源行业)的关键数据进行统计分析,由于相关行业可能存在来自不同机构(例如,证券公司、智库、行业公司等)的大量文档,投资人员需要通过阅读和整理每个相关文档进行分析、总结,这会耗费投资人员的大量时间。
2、在相关技术中,经常使用一种分布式的数据分析引擎elasticsearch,用户需要将相关文档提交到elasticsearch数据库中,然后由elasticsearch通过分词控制器将文档中相应的语句分词,进而将其权重和分词结果一并存入elasticsearch数据库,当用户查询数据的时候,由elasticsearch根据权重将结果进行排名和打分,最后将结果返回并呈现给用户。然而,由于该技术采用传统的字词查询方法,其准确性受到用户输入的查询语句的较大影响,例如,在查询语句不包含关键词语的场景下,可能得到较多的无关内容,从而影响查询结果的准确性。
技术实现思路
1、有鉴于此,本公开提供了一种文本处理方法、装置、计算设备、计算机可读存储介质以及计算机程序产品,以缓解、减轻、甚至消除上述问题。
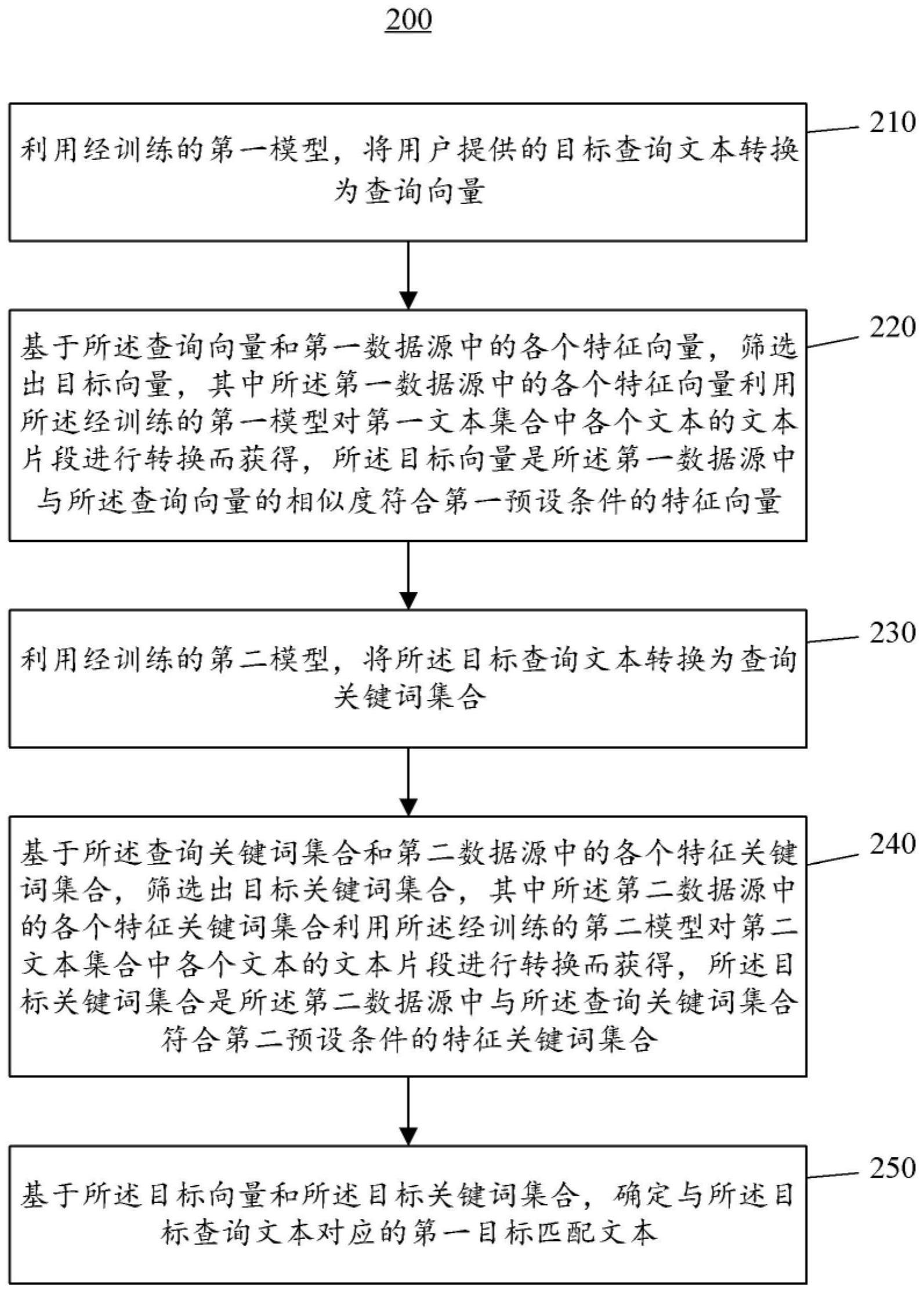
2、根据本公开的一个方面,提供了一种文本处理方法,其包括:利用经训练的第一模型,将用户提供的目标查询文本转换为查询向量;基于所述查询向量和第一数据源中的各个特征向量,筛选出目标向量,其中所述第一数据源中的各个特征向量利用所述经训练的第一模型对第一文本集合中各个文本的文本片段进行转换而获得,所述目标向量是所述第一数据源中与所述查询向量的相似度符合第一预设条件的特征向量;利用经训练的第二模型,将所述目标查询文本转换为查询关键词集合;基于所述查询关键词集合和第二数据源中的各个特征关键词集合,筛选出目标关键词集合,其中所述第二数据源中的各个特征关键词集合利用所述经训练的第二模型对第二文本集合中各个文本的文本片段进行转换而获得,所述目标关键词集合是所述第二数据源中与所述查询关键词集合符合第二预设条件的特征关键词集合;以及基于所述目标向量和所述目标关键词集合,确定与所述目标查询文本对应的第一目标匹配文本。
3、根据本公开的一些实施例,所述经训练的第一模型通过以下步骤训练得到:将多个样本文本对输入待训练的第一模型,以获取与所述多个样本文本对一一对应的多个样本向量对,其中各个样本文本对均包括样本文本片段和样本查询文本,各个样本向量对均包括第一向量和第二向量,所述第一向量与相应样本文本对中的样本文本片段对应,所述第二向量与相应样本文本对中的样本查询文本对应;基于各个样本向量对中的第一向量和第二向量,确定相应样本文本对的预测结果;基于各个样本文本对的预测结果和相应的样本结果,确定第一损失函数;以及调整所述待训练的第一模型的参数,使得所述第一损失函数最小化。
4、根据本公开的一些实施例,所述经训练的第二模型通过以下步骤训练得到:将多个样本文本片段输入待训练的第二模型,以获取与所述多个样本文本片段一一对应的多个预测关键词集合,其中各个预测关键词集合均包括与所述多个样本文本片段中的相应样本文本片段对应的多个预测关键词;基于各个样本文本片段的预测关键词集合和相应的样本关键词集合,确定第二损失函数;以及调整所述待训练的第二模型的参数,使得所述第二损失函数最小化。
5、根据本公开的一些实施例,所述第一预设条件包括:所述目标向量和所述查询向量的相似度大于第二阈值。
6、根据本公开的一些实施例,所述第二预设条件包括:所述目标关键词集合中属于所述查询关键词集合中的元素的目标关键词的数量大于第三阈值。
7、根据本公开的一些实施例,所述第一文本集合和所述第二文本集合相同,并且所述第一文本集合由所述用户从预设文本集合中选取或者由所述用户提供。
8、根据本公开的一些实施例,所述第一文本集合和所述第二文本集合中各个文本的文本片段通过以下策略中的至少一种而获取:根据标点符号,对所述第一文本集合和所述第二文本集合中的各个文本进行切分,以获取相应文本的文本片段,所述标点符号包括句号、封号、问号、感叹号中的任一种;根据段落标记,对所述第一文本集合和所述第二文本集合中的各个文本进行切分,以获取相应文本的文本片段;以及按照预设文本长度,对所述第一文本集合和所述第二文本集合中的各个文本进行切分,以获取相应文本的文本片段。
9、根据本公开的一些实施例,所述基于所述目标向量和所述目标关键词集合,确定与所述目标查询文本对应的第一目标匹配文本,包括:将与所述目标向量对应的文本片段以及与所述目标关键词集合对应的文本片段作为所述第一目标匹配文本。
10、根据本公开的一些实施例,所述方法还包括:利用数据查询系统,获取与所述目标查询文本对应的第二目标匹配文本,其中所述数据查询系统包括以下中的任一种:elasticsearch、mongodb;以及将所述第一目标匹配文本和所述第二目标匹配文本作为所述目标查询文本的查询结果而提供给所述用户。
11、根据本公开的一些实施例,所述方法还包括:将所述第一目标匹配文本输入经训练的第三模型,以获取与所述第一目标匹配文本对应的目标总结文本,所述经训练的第三模型是基于transformer构建的生成模型;以及将所述目标总结文本作为所述目标查询文本的查询结果而提供给所述用户。
12、根据本公开的另一个方面,提供了一种文本处理装置,其包括:第一转换模块,被配置为利用经训练的第一模型,将用户提供的目标查询文本转换为查询向量;第一筛选模块,被配置为基于所述查询向量和第一数据源中的各个特征向量,筛选出目标向量,其中所述第一数据源中的各个特征向量利用所述经训练的第一模型对第一文本集合中各个文本的文本片段进行转换而获得,所述目标向量是所述第一数据源中与所述查询向量的相似度符合第一预设条件的特征向量;第二转换模块,被配置为利用经训练的第二模型,将所述目标查询文本转换为查询关键词集合;第二筛选模块,被配置为基于所述查询关键词集合和第二数据源中的各个特征关键词集合,筛选出目标关键词集合,其中所述第二数据源中的各个特征关键词集合利用所述经训练的第二模型对第二文本集合中各个文本的文本片段进行转换而获得,所述目标关键词集合是所述第二数据源中与所述查询关键词集合符合第二预设条件的特征关键词集合;以及文本匹配模块,被配置为基于所述目标向量和所述目标关键词集合,确定与所述目标查询文本对应的第一目标匹配文本。
13、根据本公开的又一个方面,提供了一种计算设备,包括:存储器,其被配置成存储计算机可执行指令;处理器,其被配置成当所述计算机可执行指令被处理器执行时执行根据本公开的前述方面提供的任一方法。
14、根据本公开的又一个方面,提供了一种计算机可读存储介质,其存储有计算机可执行指令,当所述计算机可执行指令被执行时,执行根据本公开的前述方面提供的任一方法。
15、根据本公开的又一个方面,提供了一种计算机程序产品,包括计算机可执行指令,其中所述计算机可执行指令被处理器执行时执行根据本公开的前述方面提供的任一方法。
16、根据本公开提供的文本处理方法,可以利用经训练的第一模型,将用户提供的目标查询文本转换为查询向量,然后筛选出第一数据源中与查询向量的相似度符合第一预设条件的目标向量,其中第一数据源中的各个向量利用经训练的第一模型对第一文本集合中各个文本的文本片段进行转换而获得;然后,利用经训练的第二模型,将目标查询文本转换为查询关键词集合,并且筛选出第二数据源中与查询关键词集合符合第二预设条件的目标关键词集合,其中第二数据源中的各个关键词集合利用经训练的第二模型对第二文本集合中各个文本的文本片段进行转换而获得;最后,基于目标向量和目标关键词集合,确定与目标查询文本对应的第一目标匹配文本。分别利用经训练的第一模型和第二模型将目标查询文本转换为查询向量和查询关键词集合,能够在文本匹配过程中充分利用查询向量的语义特征和查询关键词集合的多个查询关键词,从而覆盖更多的查询场景。此外,由于可以将目标向量和目标关键词集合对应的文本片段作为与目标查询文本对应的第一目标匹配文本,可以进一步提高查询结果的准确性。
17、根据在下文中所描述的实施例,本公开的这些和其他方面将是清楚明白的,并且将参考在下文中所描述的实施例而被阐明。
- 还没有人留言评论。精彩留言会获得点赞!