基于WT-MEA-BiGRU的话题热度预测方法与流程
本发明涉及时间序列预测,尤其涉及人工智能,具体为基于wt-mea-bigru的话题热度预测方法。
背景技术:
1、目前,话题热度的预测问题已成为国内外诸多学者的研究热点。现有技术针对该问题,已提出如下解决方法:
2、1、基于词频分析的方法,通过查询与总结中国知网内关于知识管理研究领域的论文关键词,分析出该领域内的研究热点、现状、方法和主要学科分布等特征;
3、2、使用lda模型获取文本的主题,并对主题词进行计量分析,计算出主题词的新颖度、发文量和被引量,绘制出新兴主题探测表格与探测曲线,进而实现探测新兴主题词的目标;
4、3、使用平均转发量、平均评论量和平均点赞数,综合衡量话题热度,并通过bp神经网络,以寻找不同时刻话题热度的非线性关联;
5、4、基于emd和eemd分解技术,对话题热度实现四个层次的分解以平衡序列,随后基于分解值的历史变化,采用神经网络、支持向量机和arima方法,进行预测后求和;
6、5、从意见领袖的微博影响力和参与行为两方面进行分析,通过此类指标研究话题舆论热度的发展规律,提出一种具有自适应调节系数的多元线性回归模型,预测微博舆情话题热度;
7、6、将话题热度指标离散化,选取系列特征,通过weka软件,使用支持向量机、决策树分类和logistics回归这三种方法进行预测,其预测结果f1值达77%;但其特征选取与热度指标构建有重合之处,在删除重合特征后,预测结果的f1值出现较大下降。
8、上述方法作为传统的话题热度预测方法,一方面更多的关注了话题过去或当前的发展势态,忽视了热门话题的发展潜力;另一方面,传统方法的预测结果具有一定的滞后性,会导致话题热度衰减。而基于深度学习和机器学习的话题热度预测方法,也存在着特征挖掘的片面性,难以深度挖掘出话题热度数据中的特征信息;或是出现预测目标与特征重合的现象,这使得最终的话题热度预测结果精度不高。
技术实现思路
1、本发明为了解决传统话题预测方法存在滞后性且预测精度不高的问题,提出了一种基于wt-mea-bigru的话题热度预测方法;该方法利用小波变换(wt)对原始话题热度数据进行预处理,随后建立bigru模型,同时利用思维进化算法(mea)来优化bigru模型的超参数,确定最优的超参数组合,实现模型的训练;通过训练好的模型,预测未来话题热度,重构话题热度预测结果。本发明能更加精确地预测话题热度数据的变化趋势。
2、本发明采用了以下技术方案来实现目的:
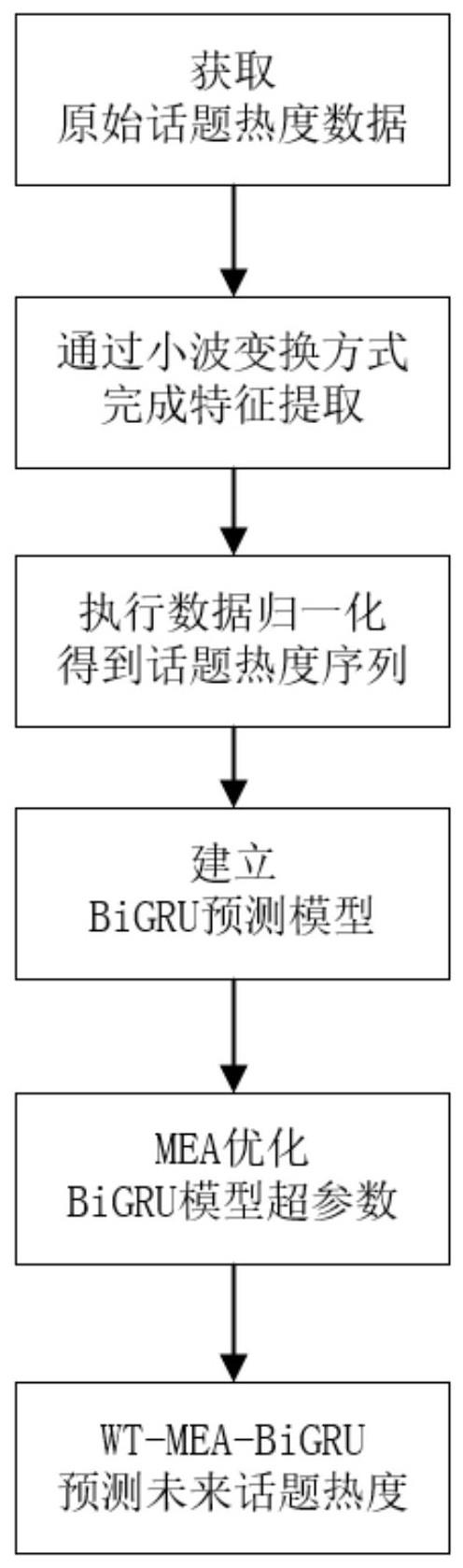
3、一种基于wt-mea-bigru的话题热度预测方法,所述方法包括如下步骤:
4、s1、获取原始话题热度数据,采用小波变换方式进行数据预处理过程,得到话题热度序列数据;
5、s2、依据话题热度序列数据,构建bigru预测模型;
6、s3、bigru预测模型构建完成后,进行模型训练;在话题热度序列数据的基础上,采用思维进化算法,优化bigru预测模型的超参数,完成模型训练过程,得到wt-mea-bigru话题热度预测模型;
7、s4、在实际话题热度数据的基础上,应用wt-mea-bigru话题热度预测模型,对未来的话题热度进行预测,得到话题热度预测结果。
8、具体的,步骤s1中,原始话题热度数据为时间序列数据;数据预处理过程中,采用离散小波分解技术wt,对时间序列数据进行特征提取;特征提取完成后,对提取的特征值数据执行归一化操作,得到话题热度序列数据。
9、进一步的,在离散小波分解技术中,将时间序列数据通过高通滤波器和低通滤波器,产生离散小波系数dwcs,并进一步进行多层分解;具体过程为:对于时间序列数据,进行首次分解,产生2组dwcs,分别为低频高通近似系数和高频细节系数;随后使用相同分解方式对低频高通近似系数进行分解,产生低频高通近似系数和高频细节系数,对每层分解得到的近似系数持续进行下层分解,直至满足分解层数要求;将时间序列数据经过层小波分解后,组合为包括1组近似系数与组细节系数的特征值数据,结构为。
10、具体的,离散小波分解过程采用的分解公式如下:
11、
12、式中,表示离散小波系数,表示时间序列数据,表示的共轭函数,表示选择的小波函数;通过分解公式分别重构低频和高频的离散小波系数,得到时间序列数据的低频近似分量与高频细节分量,组合后作为特征值数据。
13、优选的,特征提取完成后,将提取到的特征值数据映射至相似的尺度范围内,完成归一化操作,得到话题热度序列数据。
14、进一步的,步骤s2中,在构建bigru预测模型时,设置1个前向传播的gru单元和1个反向传播的gru单元,组成双向门控循环单元bigru,从而完成bigru预测模型的构建;在模型训练及实际应用时,使用模型中前向传播的gru单元计算时刻前的特征信息,使用反向传播的gru单元计算时刻后的特征信息;将时刻前后计算分别得到的2类特征信息进行线性叠加,作为bigru预测模型针对时刻的特征信息输出结果。
15、进一步的,步骤s3中,通过思维进化算法mea,优化bigru预测模型的超参数,得到wt-mea-bigru话题热度预测模型的过程,具体包括如下步骤:
16、s31、确定待优化超参数类型与寻优范围;
17、s32、获取训练集与测试集,mea算法参数初始化;在解空间内随机产生若干数量个体,每个个体包含1组超参数组合;依据不同的超参数组合,在训练集与测试集辅助下,对bigru预测模型进行模型训练与测试;
18、s33、模型训练时,选取得分函数,计算每个个体中超参数组合的得分,依据得分产生优胜子群体和临时子群体;
19、s34、分别执行优胜子群体和临时子群体各自内部的趋同操作,确定子群体得分;
20、s35、依据子群体得分计算结果,在优胜子群体和临时子群体之间,执行异化操作;异化操作确定出新的优胜子群体并产生新的临时子群体;
21、s36、循环迭代步骤s34至s35,直至满足迭代结束条件,输出此时优胜子群体中的最优个体及其得分;
22、s37、解码最优个体,将其对应的超参数组合作为bigru预测模型的最优超参数,从而得到wt-mea-bigru话题热度预测模型。
23、综上所述,由于采用了本技术方案,本发明的有益效果如下:
24、本发明顺利解决了传统话题预测方法中的滞后性问题,获得了较高的预测结果精度。在本发明的模型训练时,通过特征提取、算法优化的具体方式,能够克服模型在预测过程中易陷入局部最优解、收敛速度慢和不稳定等缺陷,因此进一步提高了模型的鲁棒性和预测精度,最终实现了对话题热度时间序列数据的高准确率预测并分析,更加精确地预测了话题热度数据的变化趋势。
技术特征:
1.一种基于wt-mea-bigru的话题热度预测方法,其特征在于:所述方法包括如下步骤:
2.根据权利要求1所述的基于wt-mea-bigru的话题热度预测方法,其特征在于:步骤s1中,原始话题热度数据为时间序列数据;数据预处理过程中,采用离散小波分解技术wt,对时间序列数据进行特征提取;特征提取完成后,对提取的特征值数据执行归一化操作,得到话题热度序列数据。
3.根据权利要求2所述的基于wt-mea-bigru的话题热度预测方法,其特征在于:在离散小波分解技术中,将时间序列数据通过高通滤波器和低通滤波器,产生离散小波系数dwcs,并进一步进行多层分解;具体过程为:对于时间序列数据,进行首次分解,产生2组dwcs,分别为低频高通近似系数和高频细节系数;随后使用相同分解方式对低频高通近似系数进行分解,产生低频高通近似系数和高频细节系数,对每层分解得到的近似系数持续进行下层分解,直至满足分解层数要求;将时间序列数据经过层小波分解后,组合为包括1组近似系数与组细节系数的特征值数据,结构为。
4.根据权利要求3所述的基于wt-mea-bigru的话题热度预测方法,其特征在于:对时间序列数据进行3层分解过程,离散小波分解过程采用的分解公式如下:
5.根据权利要求2所述的基于wt-mea-bigru的话题热度预测方法,其特征在于:特征提取完成后,将提取到的特征值数据映射至相似的尺度范围内,完成归一化操作,得到话题热度序列数据;使用的归一化公式如下:
6.根据权利要求1所述的基于wt-mea-bigru的话题热度预测方法,其特征在于:步骤s2中,在构建bigru预测模型时,设置1个前向传播的gru单元和1个反向传播的gru单元,组成双向门控循环单元bigru,从而完成bigru预测模型的构建;在模型训练及实际应用时,使用模型中前向传播的gru单元计算时刻前的特征信息,使用反向传播的gru单元计算时刻后的特征信息;将时刻前后计算分别得到的2类特征信息进行线性叠加,作为bigru预测模型针对时刻的特征信息输出结果。
7.根据权利要求6所述的基于wt-mea-bigru的话题热度预测方法,其特征在于:在构建的bigru预测模型中,采用如下模型计算公式:
8.根据权利要求1所述的基于wt-mea-bigru的话题热度预测方法,其特征在于:步骤s3中,通过思维进化算法mea,优化bigru预测模型的超参数,得到wt-mea-bigru话题热度预测模型的过程,具体包括如下步骤:
9.根据权利要求8所述的基于wt-mea-bigru的话题热度预测方法,其特征在于:步骤s33中,将训练集预测结果的均方误差倒数,选取为得分函数;步骤s34中,趋同操作为:选取子群体中得分最高的个体,作为子群体最优个体,并记录至局部公告板,随后将子群体最优个体的得分作为对应的子群体得分。
10.根据权利要求9所述的基于wt-mea-bigru的话题热度预测方法,其特征在于:步骤s35中,异化操作为:选取优胜子群体和临时子群体中得分最高的子群体,作为新的优胜子群体,并记录至全局公报板,随后丢弃其余子群体,完成1轮迭代过程;下1轮迭代开始时,在解空间内产生新的临时子群体,新的临时子群体个数与上1轮迭代中丢弃的子群体个数相同。
技术总结
本发明提供一种基于WT‑MEA‑BiGRU的话题热度预测方法,属于时间序列预测技术领域,解决了传统方法存在滞后性且预测精度不高的问题;方法包括:S1、获取原始话题热度数据,采用小波变换方式进行数据预处理过程;S2、构建BiGRU预测模型;S3、预测模型构建完成后,进行模型训练;基于话题热度序列数据,采用思维进化算法,优化预测模型的超参数,完成模型训练过程,得到WT‑MEA‑BiGRU话题热度预测模型;S4、基于实际的话题热度数据,使用训练完成的模型,对未来的话题热度进行预测,得到预测结果;本发明能实现较高的话题热度预测精度,预测模型具有高鲁棒性,能对话题热度数据的变化趋势进行精确预测。
技术研发人员:詹杰,王骥,王雨,罗贤宸,李汉文,魏晓凤
受保护的技术使用者:上海新榜信息技术股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!