一种自适应人脸图像修复方法和装置与流程
本发明涉及图像修复领域,尤其涉及一种自适应人脸图像修复方法和装置。
背景技术:
1、目前对于视频会议等使用越来越频繁,由于硬件设备的限制或者网络等因素,人脸图像往往可能不清晰。
2、现有技术中基于深度学习的人脸高清方法目的是将受到真实噪声污染的低质量人脸图像修复为高质量图像,该方法通常需要低质量和高质量的配对图像来学习两者的映射关系。在真实世界场景人脸修复中,由于很难采集到相同环境下的配对图像,因此常使用高质量图像加上一些退化操作如模糊,高斯噪声,随机上下采样等,来模拟真实世界的噪声以构建低质量图像。将这些配对数据送入已构建好的基于卷积或transformer的神经网络,来学习低质量图像到高质量图像的映射关系,以实现人脸高清的目的。
3、但是在视频会议场景中,由于受到网络带宽,会议设备,会议环境等影响,噪声并不是一成不变。如果按照上述方法制作数据来训练模型,那模型学习到的能力将会比较单一,不能自动的调整人脸清晰度和保真度的平衡。在人脸图像质量比较差的情况下,确实能够恢复细节,提升人脸图像清晰度,但是在人脸图像质量本身比较好的情况下,会对人脸造成一些额外的抹平甚至失真。
技术实现思路
1、本发明提供了一种自适应人脸图像修复方法和装置,以解决当前无法在视频会议中根据人脸图像的质量不同自适应实现人脸高清的问题。
2、第一方面,本技术提供了一种自适应人脸图像修复方法,包括:
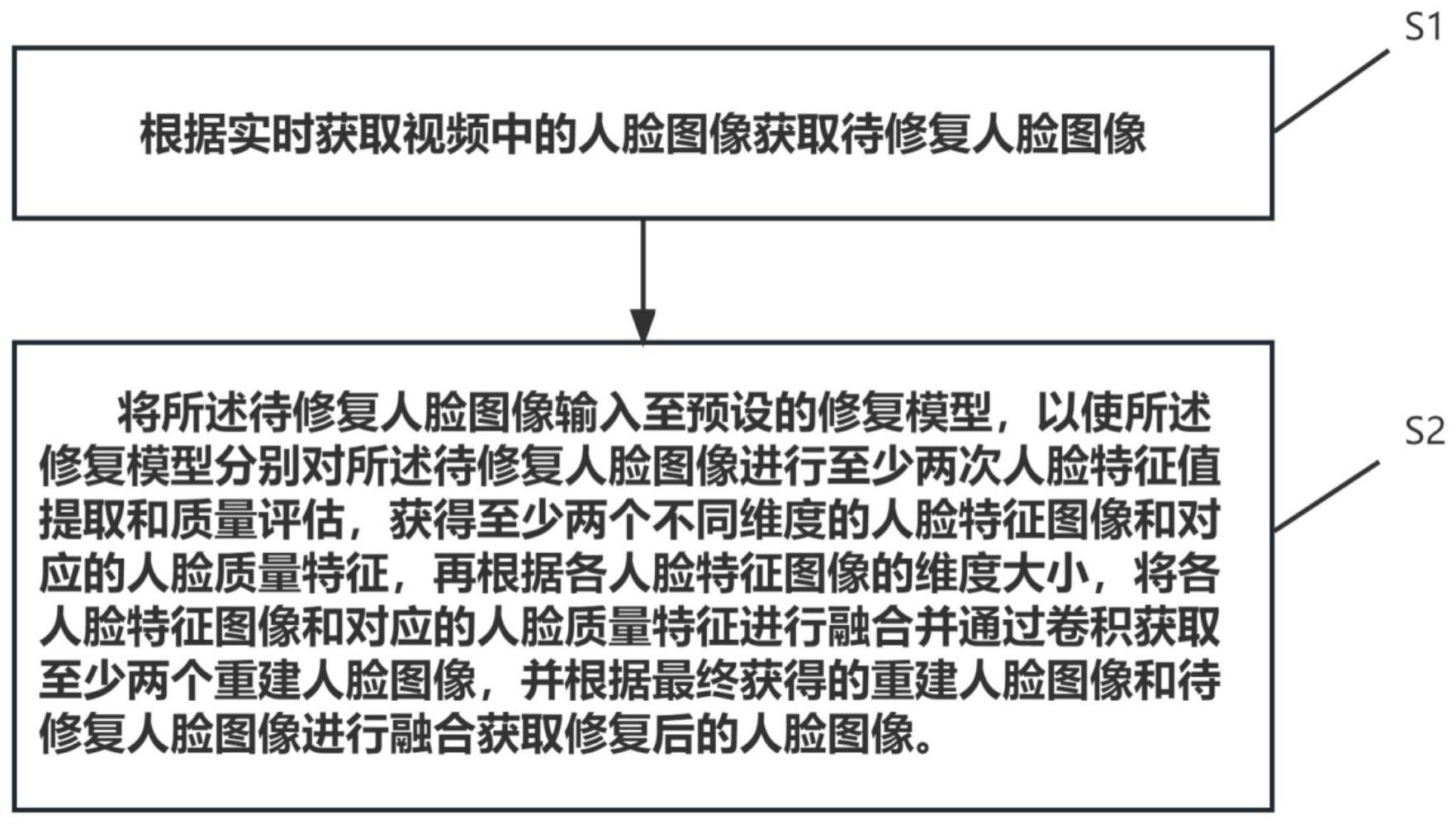
3、根据实时获取视频中的人脸图像获取待修复人脸图像;
4、将所述待修复人脸图像输入至预设的修复模型,以使所述修复模型分别对所述待修复人脸图像进行至少两次人脸特征值提取和质量评估,获得至少两个不同维度的人脸特征图像和对应的人脸质量特征,再根据各人脸特征图像的维度大小,将各人脸特征图像和对应的人脸质量特征进行融合并通过卷积获取至少两个重建人脸图像,并根据最终获得的重建人脸图像和待修复人脸图像进行融合获取修复后的人脸图像。
5、其中,上一次进行升维卷积获取的重建人脸图像用于在下一次进行升维卷积时获取下一个重建人脸图像。
6、这样通过预设的修复模型获取待修复人脸图像的多个人脸特征图像和人脸质量特征,根据所有人脸特征图像和人脸质量特征进行升维卷积对人脸进行重建。实现根据待修复人脸图像的图像质量针对性的评估,并根据评估后得到的人脸质量特征恢复人脸特征图像,从而根据图像质量有区别的消除噪声的影响,实现视频中不同质量的人脸图像获取修复后的人脸图像。
7、进一步的,所述修复模型分别对所述待修复人脸图像进行至少两次人脸特征值提取和质量评估,具体为:
8、通过所述修复模型的主分支对待修复人脸图像进行至少两次特征值提取,并通过所述修复模型的子分支对待修复人脸图像进行至少两次质量评估;
9、其中,每次特征值提取后的人脸特征图像作为下一次特征值提取的待提取图像,且每次特征值提取后会减小人脸特征图像的维度并增加所述人脸特征图像的图像通道数。
10、这样通过修复模型对待修复人脸图像进行特征值提取,可以在减少图像特征图尺寸的基础上加深网络通道数,这样既可以保留图像的信息也可以减少后续计算的计算量。
11、进一步的,所述通过所述修复模型的子分支对待修复人脸图像进行至少两次质量评估,具体为:
12、所述修复模型的子分支中包括至少两个卷积层用于对待修复人脸图像进行至少两次质量评估获取至少两个人脸质量特征;
13、其中,将所述待修复人脸图像输入卷积层获得人脸质量特征,再将所述人脸质量特征作为输入下一个卷积层的待评估特征用于获取下一个人脸质量特征;
14、其中,卷积层的数量和特征值提取的次数相同且各个卷积层的步长均相同。
15、进一步的,所述预设的修复模型是根据通过对高清人脸图像随机添加噪声获取的模糊图像作为训练数据,由相对应的损失函数迭代训练获得。
16、进一步的,所述修复模型是根据对高清人脸图像随机添加噪声获取的模糊图像,根据相对应的损失函数而迭代训练获得,具体为:
17、获取至少两高清人脸图像,根据至少一种噪声生成函数对所述高清人脸图像添加噪声获取对应的模糊人脸图像,由所述至少两高清人脸图像和对应的模糊人脸图像组成所述训练数据;
18、每次迭代训练时,根据所述训练数据,由修复模型计算每次迭代训练时的损失函数值;
19、当所述损失函数值满足预设要求或者达到迭代次数后,确定所述修复模型训练完成。
20、进一步的,所述根据至少一种噪声生成函数对所述高清人脸图像添加噪声获取模糊人脸图像,具体为:
21、lq=[rs(rc(blur,noise,jpeg,resize))]hq;
22、其中,lq为模糊人脸图像、hq为高清人脸图像、blur为高斯模糊函数、noise为高斯噪声函数、jpeg为压缩噪声函数、resize为随机上下采样函数、rc为随机选择至少一种噪声生成函数,rs为将选择到的噪声生成函数进行随机排序。
23、进一步的,所述每次迭代训练时,根据所述训练数据,由修复模型计算每次迭代训练时的损失函数值,具体为:
24、根据当前迭代训练的训练数据中模糊人脸图像,由所述修复模型获取所述模糊人脸图像对应的人脸质量特征;
25、获取所述模糊人脸图像在本地模型上得出的本地质量分数;
26、由质量分数、本地质量分数、本次迭代获取的修复后人脸图像和所述模糊人脸图像对应的高清图像获取本次迭代的损失函数值。
27、进一步的,所述由质量分数、本地质量分数、本次迭代获取的修复后人脸图像和所述模糊人脸图像对应的高清图像获取本次迭代的损失函数值,具体为:
28、
29、其中,out为本次迭代获取的修复后人脸图像;hq为模糊人脸图像对应的高清图像;net(lq)为模糊人脸图像在本地模型上得出的本地质量分数;q为所述模糊人脸图像对应的质量分数;lp为感知损失;λ1为感知损失的权重系数;lg为gan损失;λ2为gan损失的权重系数;lq为质量分数损失,λ3为质量分数损失的权重系数。
30、第二方面,本技术提供了一种自适应人脸图像修复装置,包括:待修复图像获取模块和修复图像获取模块;
31、所述待修复图像获取模块用于根据实时获取视频中的人脸图像获取待修复人脸图像;
32、所述修复图像获取模块用于将所述待修复人脸图像输入至预设的修复模型,以使所述修复模型分别对所述待修复人脸图像进行至少两次人脸特征值提取和质量评估,获得至少两个不同维度的人脸特征图像和对应的人脸质量特征,再根据各人脸特征图像的维度大小,将各人脸特征图像和对应的人脸质量特征进行融合并通过卷积获取至少两个重建人脸图像,并根据最终获得的重建人脸图像和待修复人脸图像进行融合获取修复后的人脸图像;
33、其中,上一次进行升维卷积获取的重建人脸图像用于在下一次进行升维卷积时获取下一个重建人脸图像。
34、进一步的,所述修复图像获取模块包括:分支单元;
35、所述分支单元用于通过所述修复模型的主分支对待修复人脸图像进行至少两次特征值提取,并通过所述修复模型的子分支对待修复人脸图像进行至少两次质量评估;
36、其中,每次特征值提取后的人脸特征图像作为下一次特征值提取的待提取图像,且每次特征值提取后会减小人脸特征图像的维度并增加所述人脸特征图像的图像通道数。
37、进一步的,所述分支单元包括:子分支单元;
38、所述子分支单元用于通过将所述第一人脸特征图像输入卷积层,获取所述第一人脸特征图像的人脸质量特征;
39、还用于重复将上一次通过卷积层获取的所述人脸质量特征输入卷积层,获取新的人脸质量特征,直到所述人脸质量特征的数量和除去第一人脸特征图像后人脸特征图像的数量相同。
40、进一步的,所述修复图像获取模块包括:训练模块;
41、所述训练模块用于根据通过对高清人脸图像随机添加噪声获取的模糊图像作为训练数据,由相对应的损失函数迭代训练获得预设的修复模型。
42、进一步的,所述训练模块包括:训练集生成单元、损失函数计算单元和训练停止单元;
43、所述训练集生成单元用于获取至少两高清人脸图像,根据至少一种噪声生成函数对所述高清人脸图像添加噪声获取对应的模糊人脸图像,由所述至少两高清人脸图像和对应的模糊人脸图像组成所述训练数据;
44、所述损失函数计算单元用于每次迭代训练时,根据所述训练数据,由质量评估模型计算每次迭代训练时的损失函数值;
45、所述训练停止单元用于当所述损失函数值满足预设要求或者达到迭代次数后,确定修复模型训练完成。
46、进一步的,所述训练集生成单元包括模糊人脸生成单元,具体为:
47、lq=[rs(rc(blur,noise,jpeg,resize))]hq;
48、其中,lq为模糊人脸图像、hq为高清人脸图像、blur为高斯模糊函数、noise为高斯噪声函数、jpeg为压缩噪声函数、resize为随机上下采样函数、rc为随机选择至少一种噪声生成函数,rs为将选择到的噪声生成函数进行随机排序。
49、进一步的,所述损失函数计算单元包括:质量分数生成单元,本地质量分数获取单元和损失函数生成单元;
50、所述质量分数生成单元用于根据当前迭代训练的训练数据中模糊人脸图像,由所述质量评估模型,获取所述模糊人脸图像对应的质量分数;
51、所述本地质量分数获取单元用于获取所述模糊人脸图像在本地模型上得出的本地质量分数;
52、所述损失函数生成单元用于由质量分数、本地质量分数、本次迭代获取的修复后人脸图像和所述模糊人脸图像对应的高清图像获取本次迭代的损失函数值。
53、进一步的,所述损失函数生成单元具体为:
54、
55、其中,out为本次迭代获取的修复后人脸图像;hq为模糊人脸图像对应的高清图像;net(lq)为模糊人脸图像在本地模型上得出的本地质量分数;q为所述模糊人脸图像对应的质量分数;lp为感知损失;λ1为感知损失的权重系数;lg为gan损失;λ2为gan损失的权重系数;lq为质量分数损失,λ3为质量分数损失的权重系数。
56、这样通过预设的修复模型获取待修复人脸图像的多个人脸特征图像和人脸质量特征,根据所有人脸特征图像和人脸质量特征进行升维卷积对人脸进行重建。实现根据待修复人脸图像的图像质量针对性的评估,并根据评估后得到的人脸质量特征恢复人脸特征图像,从而根据图像质量有区别的消除噪声的影响,实现视频中不同质量的人脸图像获取修复后的人脸图像。
- 还没有人留言评论。精彩留言会获得点赞!