一种基于ISSA-RF算法的光伏发电系统故障分类方法
本发明属于光伏发电系统故障检测和分类,特别是涉及一种基于issa-rf算法的光伏发电系统故障分类方法。
背景技术:
1、太阳能光伏发电是技术成熟、产业化程度高的太阳能利用方式,具有广阔的发展前景。但是光伏发电具有随机性、间歇性输出特点,同时其通常工作在复杂的户外环境中,受到各种环境因素的影响,容易出现组件损坏、开路、局部阴影等各种故障,故障的发生会严重影响电力系统安全运行。故在此背景下,对光伏阵列故障的识别与诊断显得尤为重要,准确得出故障类型能有效根据知识图谱得出详细的处理方法,能大大提高故障处理的效率。
2、光伏阵列故障分类方法主要包括红外图像检测法、接地电容测量法和时域反射分析法等传统方法,还有人工神经网络、随机森林、模糊c均值聚类法、支持向量机和极限学习机等智能方法,传统方法往往存在故障检测精度不足、实时性差,检测结构复杂和诊断精度有限等缺陷,在具有一定规模的光伏阵列应用中难以推广。在实际工程中的故障诊断问题往往较难得到很大量的样本,因此故障样本的缺乏成为制约人工神经网络在光伏发电阵列故障诊断和分类中的瓶颈问题。
3、目前,在利用智能算法进行光伏阵列故障分类方面已有部分相关研究。例如申请公布号为cn104753461b的专利所公布的一种基于粒子群优化支持向量机的光伏发电阵列故障诊断与分类方法,将故障检验转化为二分类的问题,以光伏发电阵列最大功率点的电压和电流值作为特征向量实现其工作状态的判别,采用粒子群算法优化支持向量机中的参数c和g,再加上光伏发电阵列最大功率点的电压和电流值作为特征向量实现其工作状态的判别,但是由于支持向量机算法是借助二次规划来求解支持向量,当样本数目很大时该矩阵的存储和计算将耗费大量的机器内存和运算时间,同时此算法对缺失数据敏感。申请公布号为cn108665112a的专利所公布的一种基于改进粒子群优化elman网络的光伏故障检测方法,采用改进的粒子群算法获取神经网络最优权值,克服了elman神经网络陷于局部最优解的缺陷来得到光伏阵列故障分类模型,但是当数据样本不足时分类精度较差。因此本发明提出基于改进麻雀搜寻算法结合随机森林算法的光伏发电系统故障分类方法,对上述问题进行改进。
技术实现思路
1、有鉴于此,本发明的目的是提供一种基于issa-rf算法的光伏发电系统故障分类方法,通过改进后的麻雀搜索算法对随机森林算法里面的决策树数目和特征数进行寻优,基于光伏阵列和光伏系统元件的故障实验电气参数构造随机森林分类模型,进而实现对光伏发电系统故障的精准分类。
2、为实现上述目的,本发明所采用的技术方案包括以下内容:
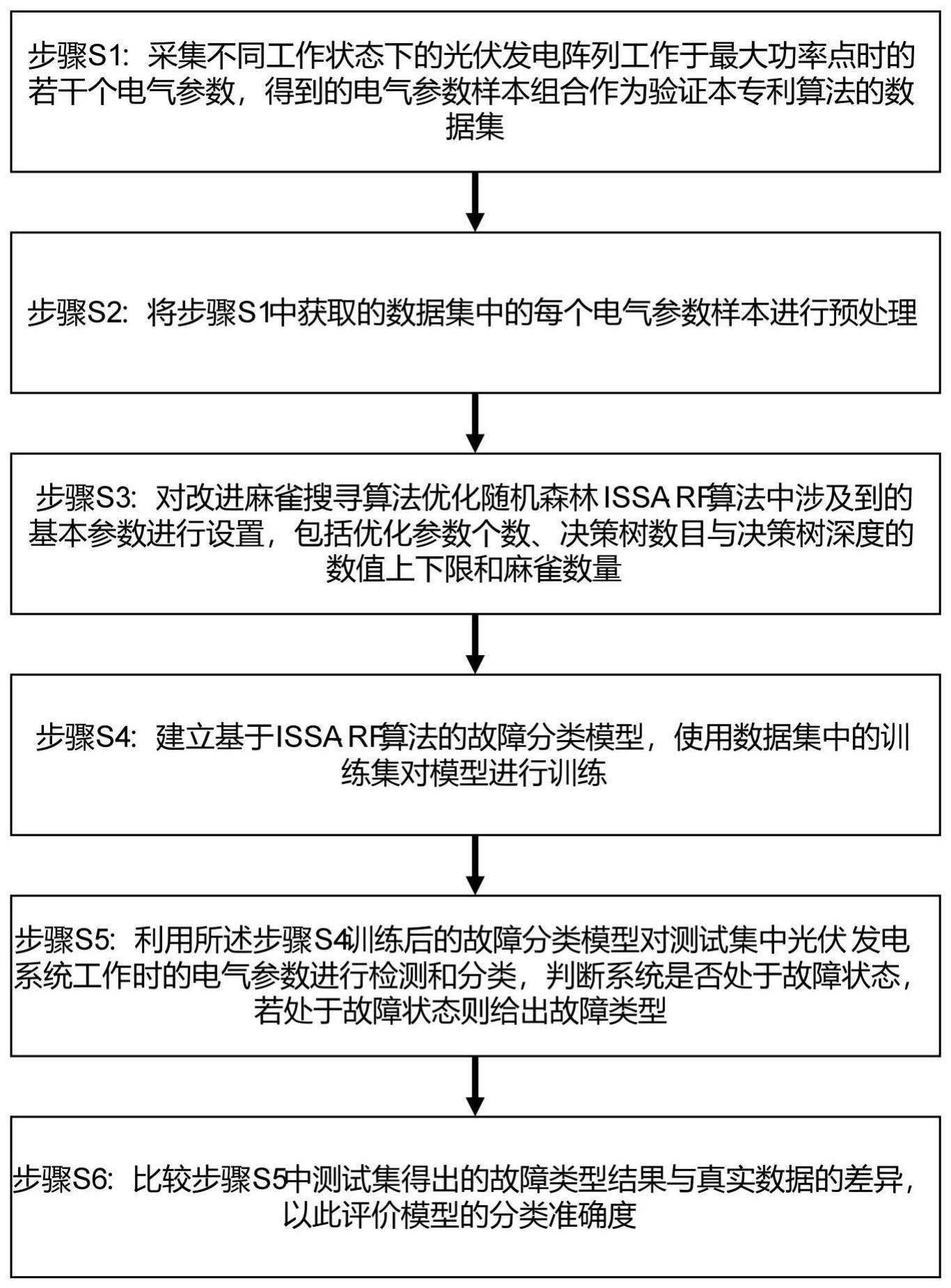
3、本发明提供了一种光伏发电系统故障分类方法,其具体包括如下步骤:
4、获取不同工作状态下的若干个电气参数,所述电气参数采集于光伏发电阵列工作于最大功率点时,将所述电气参数的样本组合作为数据集;
5、对所述数据集的电气参数进行预处理;
6、设置issa-rf算法中涉及到的基本参数并以此建立基于issa-rf算法的故障分类模型,使用所述数据集中的训练集对该故障分类模型进行训练;
7、利用训练后的故障分类模型对该测试集中光伏发电系统工作时的电气参数进行检测和分类,判断光伏发电系统是否处于故障状态,若处于故障状态则输出故障类型。
8、进一步地,所述不同工作状态,具体包括:正常状态、逆变器故障、反馈传感器故障、电网异常故障、局部阴影故障、单支路开路故障、mppt控制器故障和升压转换器控制器故障,然后分别对上述故障类型从1到8进行编号。
9、进一步地,所述电气参数,具体包括:光伏阵列电流、光伏阵列电压、直流电压、a相电流、b相电流、c相电流、a相电压、b相电压、c相电压、交流三相电流大小、交流三相电流频率、交流三相电压大小和交流三相电压频率。
10、进一步地,对所述数据集的电气参数进行预处理,具体包括步骤:
11、识别数据集中的电气参数类别数和样本数并打乱数据集;
12、划分训练集和测试集,根据类别数循环取出不同类别的样本数据并随机放入训练集和测试集,其中设定训练集占数据集数量的75%;
13、对训练集和测试集的样本数据进行归一化处理,即映射到区间[0,1]内。
14、进一步地,设置issa-rf算法中涉及到的基本参数,具体包括:优化参数个数、决策树数目与决策树深度的数值上下限和麻雀数量,其中,
15、优化参数个数=2;
16、决策树数目与决策树深度的数值上限=[500,13];
17、决策树数目与决策树深度的数值下限=[100,01];
18、麻雀数量=10。
19、进一步地,建立基于issa-rf算法的故障分类模型,具体包括步骤:
20、a、首先建立issa模型:
21、a1、对改进麻雀搜寻算法中的基础参数进行设置,其中安全阈值设定为0.5,发现者比例为20%,加入者比例为80%,预警者比例为10%,优化参数为2;
22、a2、精英反向学习优化初始种群,选取最优个体作为最终的初始种群,设当前麻雀种群个体位置的矩阵x和第i只麻雀位置的矩阵xi分别为:
23、
24、xi=[xi,1,…,xi,j,…,xi,d]
25、式中,xi,j表示第i只麻雀在第j维中的位置信息,d是待优化变量的维度,令麻雀的适应度即目标函数表达式如下:
26、f=[f(x)1) … f(xi) … f(xn)]t
27、式中,f(xi)=xi2是第i只麻雀的个体适应度,由以上可得第i只麻雀个体位置的反向解xi*为:
28、xi*=α3[min(xi,j)+max(xi,j)]-xi
29、式中,α3是(0,1]范围的随机数,利用随机生成的α3值可以生成多个反向解,如果生成的反向解超出上下边界值,即上限[500,13]和下限[100,01],则重置反向解,然后对原可行解和反向解的适应度进行评估,选出更优解即精英个体位置作为初始种群的个体位置;
30、a3、计算每只麻雀适应度并排序;
31、a4、判断麻雀位置更新策略:设定转换概率p=0.7,若均匀分布随机数r∈[0,1]小于转换概率p,则使用原始公式更新麻雀发现者、加入者和预警者的位置,并利用自适应t变异公式更新每只麻雀的位置,公式如下:
32、①发现者位置更新:
33、
34、式中,r是当前迭代次数,rmax是最大迭代次数,α1是(0,1]范围均匀分布的随机数,q是服从正态分布的随机数,l是各元素都为1的1行多维矩阵,ra∈[0,1]和rs∈[0.5,1]分别代表预警值和安全阈值;
35、②加入者位置更新:
36、
37、式中,xb和xw分别表示全局最优位置和最劣位置,a表示一个1×d即一行多维的矩阵,其中每个元素随机赋值为1或-1;
38、③预警者位置更新,预警者在种群中随机地产生且占种群数量的10-20%:
39、
40、式中,β1是步长控制参数,是服从均值为0,方差为1的正态分布随机数;α2是[-1,1]范围均匀分布的随机数;β2是避免当fn=fb时,分母为0的情况发生的最小常数;fn、fb和fw分别代表当前适应度、最佳适应值和最劣适应度;
41、④利用自适应t变异公式更新每只麻雀的位置,第i个麻雀的原位置xi变异公式如下:
42、
43、式中,代表t变异后麻雀的位置,ζ代表自适应因子,t(r)为以当前迭代次数r为
44、参量的t分布函数,其中自适应t分布的概率密度函数如下:
45、
46、式中,为第2类欧拉积分,这里取迭代次数r作为x参量,k为自由度参量;
47、另外,若均匀分布随机数r∈[0,1]大于等于转换概率p,则应用精英反向策略更新发现者位置,应用萤火虫算法扰动加入者位置,应用原式更新预警者的位置,公式如下:
48、①精英反向策略更新发现者位置:
49、第i只发现者个体位置更新的原式为:
50、
51、式中,r是当前迭代次数,rmax是最大迭代次数,α1是(0,1]范围均匀分布的随机数,q是服从正态分布的随机数,l是各元素都为1的1行多维矩阵,ra∈[0,1]和rs∈[0.5,1]分别代表预警值和安全阈值,在此基础上采用精英反向策略,则第i只发现者个体位置更新的反向解xi(r+1)*为:
52、xi(r+1)*=α3[min(xi,j(r+1))+max(xi,j(r+1))]-xi(r+1)
53、式中,α3是(0,1]范围均匀分布的随机数,利用随机生成的α3值可以生成多个反向解,如果生成的反向解超出上下边界值,即上限[500,13]和下限[100,01],则重置反向解,然后对原可行解和反向解的适应度进行评估,选出更优解即精英个体位置作为发现者的个体位置;
54、②萤火虫算法扰动加入者位置:
55、第i只加入者个体位置更新的原式为:
56、
57、式中,xb和xw分别表示全局最优位置和最劣位置,a表示一个1×d即一行多维的矩阵,其中每个元素随机赋值为1或-1,在此基础上采用萤火虫算法扰动策略,则第i只发现者个体位置xi(r+1)'的更新公式为:
58、xi(r+1)'=xi(r+1)+λ(α4-0.5)
59、式中,λ∈[0,1]为步长因子,α4是(0,1]范围均匀分布的随机数,此策略在一定程度上避免过早陷入局部最优;
60、③应用原式更新预警者的位置;
61、a5、计算并更新每只麻雀的适应度值,对步骤(a4)越界的麻雀位置做越界处理,比较新适应度值和上一次迭代过程中的原适应值,若新适应度值优于原值则更新位置和适应度值,反之则保留;
62、a6、判断当前迭代次数r是否达到最大迭代次数,若是,则循环结束,输出麻雀全局最优位置结果,反之,返回步骤a4;
63、a7、把步骤a6中改进麻雀搜寻算法中的全局最优位置的二维坐标值输出到随机森林程序中分别作为决策树数目ntree的最优值和指定节点中用于二叉树的变量个数也叫决策深度mtry的最优值;
64、b、最后建立随机森林模型:
65、b1、首先从原始数据集中通过有放回的抽样方式,即每抽取一个样本后再将它放回总体的方式来进行样本的随机抽取;
66、b2、再利用子数据集构建决策树,假设一个子数据集有x个属性,在决策树的每个节点需要分裂时,从这些属性中随机抽选出y个属性,其中y<<x,再通过如信息增益等方式从y个属性中选择一个作为该节点的分裂属性,不断重复这个步骤,直到达到决策深度值mtry为止;
67、b3、按照步骤b1-b2来构建若干的决策树直到达到决策树数目值ntree为止,这些决策树就会构成随机森林;
68、b4、将数据集输入到不同的决策树中会得到不同的判断结果,占比最大的判断结果则被选择为随机森林的最佳分类方案。
69、进一步地,输出故障类型之后,还包括步骤:
70、根据输出的所述故障类型和真实数据的差异,以此评价所述故障分类模型的分类准确度。
71、进一步地,评价所述故障分类模型的分类准确度采用如下设定评价指标:
72、
73、其中,simtype为故障类型结果,type为真实数据,n为样本数量。
74、本发明与现有技术相比,其有益效果在于:本发明使用了基于精英反向的改进型t分布麻雀算法(issa),能有效加强麻雀粒子之间的交流,加快算法收敛速度,同时使用精英反向学习策略保证麻雀种群均匀性并且增强全局搜索的能力,引入t分布算法前期增加全局搜索能力,后期增加局部寻优能力,采用萤火虫算法,进一步增加种群多样性;此改进麻雀搜索算法对基本随机森林算法进行了优化,以全局适应度最佳为目标,进行决策树数目和特征数的动态寻优,避免了人为指定算法参数可能带来的误差。进一步地,在样本有限的情况下具有良好的泛化能力,有效提高光伏发电系统故障分类的准确性,通过matlab程序进行仿真证明本专利提出的方法对于故障分类准确率可达98%。
- 还没有人留言评论。精彩留言会获得点赞!