一种基于深度学习算法的数显仪表数字识别方法与流程
本发明属于数显仪表读数识别领域,具体涉及一种基于深度学习算法的数显仪表数字识别方法。
背景技术:
1、仪表作为一种数据采集和信息反馈的工具,为相关工作人员提供了一种直观的可视化读取数据的方式,因此被广泛应用于工业生产、科学研究和日常生活之中。传统仪表需要人工目测,工作量大,费时费力,不符合集成高效快捷的时代需求。在一些复杂危险的环境,如发电厂、变电站等电力企业,为了保证其安全、可靠地运行,只能使用没有配备数字化接口的传统仪表来显示各个设备的参数,需要专业人员进行巡视抄表,用于检查电站的工作情况。这其中就存在着工作量大,人工抄录主观因素大,存在读取误差等问题。
2、针对这些问题,目前比较常用的方法是通过视觉图像处理方法来采集仪表示数。先利用摄像头采集包含仪表显示区域的图像,再对仪表显示区域进行识别定位,最后识别显示区域示数。将识别算法搭载在配备有摄像头的穿戴式设备中,工作人员穿戴设备后,将摄像头对准仪表采集图像,并通过识别算法读取仪表示数,将其记录为电子数据。利用这种方法可以代替人工读表抄表,减轻工作人员负担,剔除读表中的主观因素影响。
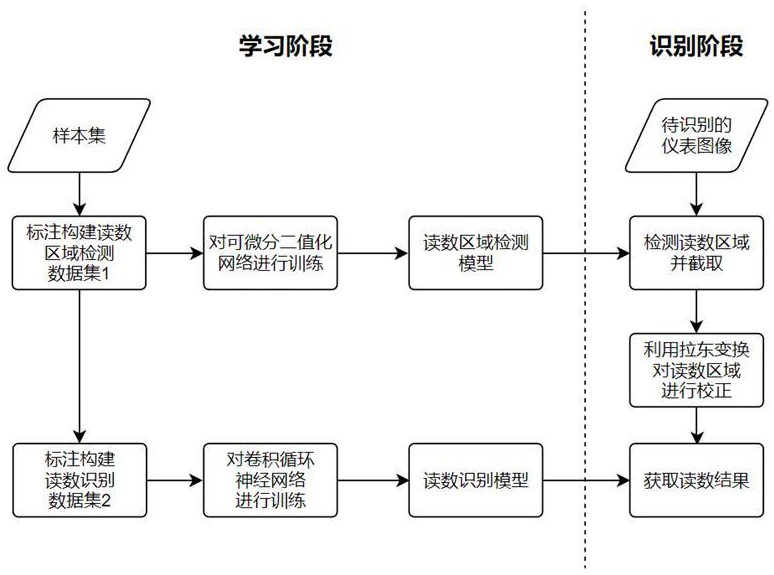
3、仪表读数识别的过程主要包括数字定位和数字识别两部分。
4、数字定位即在图像中框选出仪表示数所在区域,用于进一步进行数字提取和识别。仪表的矩形显示屏特征突出,传统方法一般通过提取图像内的图形特征,利用仪表图形的特点来实现数字定位。2008年,gioi r等人提出了一种局部提取直线的检测算法(vongioi r. g., jakubowicz j., morel j. m., et al. lsd:a fast line segmentdetector with a false detection control[j].ieee transactions on patternanalysis and machine intelligence,2008,32(4):722-732),该方法通过计算每个像素的level-line angle,构成一个level-line场,将误差范围内的像素集合构成一个支持域,通过比较支持域临界矩形的主方向与支持域内像素的level-line angle来判断该支持域是否为一条直线。也可以利用特征点算子针对几何特征进行仪表识别,如利用sift、surf算子对图像进行匹配,识别仪表区域。深度学习是机器学习的一个分支,利用深度学习算法可以直接实现对包含仪表的图像进行特征提取,不再需要像传统方法那样人为设计特征提取方法,避免了设计者先验知识的局限性导致的问题。2017年,zhou x等人提出了一种高效文本检测算法(zhou x., yao c., wen h.,et al. east: an efficient and accuratescene text detector[c].proceedings of the ieee conference on computer visionand pattern recognition.2017:5551-5560),可以快速进行文本行级别的检测,将检测到的文本行框选出来。
5、数字识别过程属于字符类别较少的字符识别。针对字符识别的传统方法大多遵循先分割再识别的思路,可以利用灰度图像投影的方法进行分割,再分别识别每个字符,但传统方法受光线等影响较大,鲁棒性较差。对此,基于深度学习的不定长识别方法应运而生。常用的神经网络如卷积循环神经网络,可以对以段落为单位标注的样本进行训练与识别,相比于传统方法对噪声的抗干扰能力更强,识别效果更加稳定。
技术实现思路
1、针对传统方法存在的不足,本发明目的是提供一种基于深度学习算法的数显仪表数字识别方法,以解决上述背景技术中提出的问题,本发明考虑了在工业环境中不同光照、不同角度下的数显数字仪表检测与读书识别环境,具有很强的抗干扰能力,并提升数显数字仪表检测识别的正确率。
2、为了实现上述目的,本发明是通过如下的技术方案来实现:将识别算法搭载在配备有摄像头的穿戴式设备中,工作人员穿戴设备后,将摄像头对准仪表采集图像,并通过识别算法读取仪表示数,将其记录为电子数据。
3、进一步的,所述一种基于深度学习算法的数显仪表数字识别方法,包括以下步骤:
4、(1) 采集不同数显数字仪表的样本图像,划分训练集和测试集;
5、(2)对训练集和测试集进行打标,将数字区域利用旋转矩形框框选出来,构建用于训练读数区域检测网络的读数区域检测数据集;
6、(3) 将数据集的数字区域截取出来,对每个样本图像的数字内容进行标注,构建用于训练读数识别网络的读数识别数据集,并根据样本中出现的字符种类构建数字识别字典;
7、(4)利用读数区域检测数据集对可微分二值化网络进行训练,获得用于检测读数区域的网络模型,利用读数识别数据集对卷积循环神经网络进行训练,获得用于识别读数区域读数的网络模型;
8、(5)将待识别图像转换为读数区域检测网络输入的标准格式,送入读数区域检测模型中,检测出读数区域位置,并记录对应读数区域的坐标;
9、(6)根据步骤(5)得到的读数区域坐标将读数区域截取下来,对读数区域图像的边缘图像做拉东变换实现数字图像方向的校正,并转换为读数识别网络输入的标准格式,送入读数识别模型中,得到最终的识别结果。
10、上述步骤的特征在于:
11、步骤(1)中采集到的图像包含不同倾斜角度,不同光照条件与不同背景下的仪表图像,用于提高模型在不同条件下的识别准确率。
12、步骤(2)中利用旋转矩形框对样本进行标注,旋转矩形框上下边缘应与读数区域数字方向平行,且矩形框应与读数区域边缘保持一致。
13、步骤(4)中的检测读数区域的网络模型结构如下,先将样本输入特征金字塔中,提取样本的特征图并进行上采样拼接;再将拼接好的特征图经过一次卷积和两次反卷积得到样本的概率图,将拼接好的特征图经过一次卷积和两次反卷积得到样本的自适应阈值图,两次处理过程相同,参数不同;最后对概率图和自适应阈值图进行可微分二值化获得近似二值图,得到检测到的目标结果。
14、步骤(4)中的识别读数区域读数的网络模型结构如下,将识别好的读数区域图像输入到卷积层提取特征图;再转换为特征序列在循环层中对序列特征进行学习,输出预测标签序列;最后在转录层对所得标签序列解码分类预测,给出最终的结果序列。
15、步骤(6)中读数区域角度校正的方法是,对读数区域图像利用加权平均法获得灰度图,再对灰度图像利用canny特征提取算法获取读数区域的边缘图像,对边缘图像做的拉东变换,得到变换后的统计值矩阵。比较得到中的最大值对应的角度,利用该角度旋转图像即可实现对图像的角度校正。
16、本发明的思路为:
17、(1)读数区域检测网络的思路
18、本发明使用了可微分二值化网络的思想构建读数区域检测网络。可微分二值化算法是一种基于分割的文本检测算法,不同于传统分割算法通过设定一个固定的阈值将生成的概率图转换为二值图像的方法,可微分二值化算法提出了将二值化操作插入到分割网络中进行联合优化的后处理方法。在训练过程中网络可以对图像中每个像素点相应地预测出一个自适应阈值,因此可以完全区分目标和背景的像素点。
19、本发明所使用的可微分二值化算法的网络结构表述如下,特征金字塔网络从输入的图像提取4个对应大小为原图像1/4、1/8、1/16、1/32的特征图,并将特征图上采样为原图像大小的1/4,经过合并拼接得到特征图。预测阶段根据特征图预测概率图和自适应阈值图,经过可微分二值化获得近似二值图,最终输出检测到的目标结果。在训练过程中,将对概率图、自适应阈值图和近似二值图同时进行监督训练,因此可以训练得到每个像素对应的自适应阈值。
20、本发明所使用的网络中由特征图获得概率图和自适应阈值图时的过程相同,只是训练过程中分别训练,对应的参数不同。转换中先将特征图经过卷积层,将通道压缩为输入的1/4,然后经过批量归一化(batch normalization,bn)和relu激活,再对得到的结果进行两次卷积核为(2, 2)的反卷积,其中第二次输出的特征值通道为1,最后经过sigmoid函数输出得到概率图和自适应阈值图。
21、本发明中所使用的可微分二值化操作可以表示为:
22、
23、其中为放大因子。若采用标准二值化操作,会导致训练过程中出现梯度不可微的情况。从式子中可以看出该函数可微,在训练阶段不会带来梯度不可微的情况。
24、(2)读数区域图像角度校正的思路
25、本发明在对读数区域图像进行角度校正时,先利用加权平均法获得图像的灰度图,再对灰度图像利用canny特征提取算法获取读数区域的边缘图像,对边缘图像利用拉东变换实现对检测到的读数区域的角度校正。
26、本发明在进行角度校正中,对边缘图像做的拉东变换,得到变换后的统计值矩阵。比较得到中的最大值对应的角度,利用该角度旋转图像即可实现对图像的角度校正。
27、(3)读数识别网络的思路
28、本发明使用了卷积循环神经网络的思想构建读数识别网络。卷积循环神经网络的网络结构主要由三部分组成,输入的图像先经过卷积层提取特征图;再转换为特征序列在循环层中对序列特征进行学习,输出预测标签序列;最后在转录层对所得标签序列解码分类预测,给出最终的结果序列。
29、本发明中网络在卷积层中对图像进行卷积池化,提取对应特征图,并将其转换为特征序列送入循环层。由于字符在图像中按照水平方向分布,我们希望循环层也能按照水平方向序列进行训练和预测,并提取水平方向各序列的相关性。因此crnn对特征图按列提取序列向量,序列向量的顺序与图像水平方向排布顺序相同。将由此得到的每个特征序列作为一个时间步送入循环层进行训练,可以捕捉各列间数据的相关性。
30、本发明中网络的循环层由长短时记忆网络(long short-term memory,lstm)构成。由于lstm只能处理每段序列与前面序列间的相关性,而在文本识别中两个方向的序列是互补的,lstm无法处理后面序列间的相关性。因此crnn中两个长短时记忆网络被反向拼接,可以同时处理前后两个方向的序列,更好地适应文本识别要求。
31、本发明中网络的转录层对循环层中得到的标签序列解码分类预测,将连续的相同预测结果合并为一个字符,并设置空白字符用于区分两个相连的相同字符。训练时,网络先根据给定序列判断所有可能的输出,并对这些输出的概率求和,利用概率的负最大似然函数表示损失值,该损失函数被称为ctcloss。利用该损失函数可以对卷积层和循环层进行联合训练。
32、本发明中网络的具体结构描述如下,在网络的前半部分包含7个卷积池化层,其中最后一个卷积层使用的卷积核,其他卷积层均使用的卷积核。所有层均使用relu激活函数进行非线性变化,并在第三层、第五层和第七层使用批标准化加快深层网络的训练速度,提高分类效果。在网络的后半部分采用了两层lstm拼接的双向lstm进行序列建模,隐藏层参数设置为256,对输入的特征进行处理并输出序列特征。双向lstm层的输出经过log_softmax函数转换为概率分布,以便计算损失和进行预测。
- 还没有人留言评论。精彩留言会获得点赞!