一种软件缺陷数据生成方法和系统
本发明涉及数据生成,尤其是指一种软件缺陷数据生成方法和系统。
背景技术:
1、软件缺陷预测(software defect prediction,sdp)涉及预测软件中可能会出现的缺陷。有效的缺陷预测有助于及时识别软件中软件缺陷的区域。在软件开发生命周期的早期阶段,识别软件缺陷并消除软件缺陷对产生具有成本效益和高质量的软件产品至关重要。通常,sdp的数据集具有数量不平衡现象,具体指非缺陷(多数类)样本的数量较多,缺陷(少数类)样本的数量很少。在不平衡数据上训练模型会产生偏差学习,从而导致不准确的预测。因此,有效处理不平衡数据对于成功开发有效的缺陷预测模型至关重要。
2、过采样方法是一种通过增加少数类样本的方法来解决数据分布不平衡问题。smote(synthetic minority oversampling technique)是现有最经典的过采样方法,它通过随机选择少数类样本点来进行线性插值,以此来增加少数类样本点的数量。但是,smote忽略了噪音样本点与无用样本点对分类结果的影响,可能会导致生成新的噪音样本点或者无用样本点,从而产生过拟合现象。cluster-smote(cluster synthetic minorityoversampling technique)是对smote方法的一种改进,通过对少数类样本进行聚类,可以更好地保留数据的局部结构,减少过度拟合的风险。但是该方法可能会生成新的噪声点,使得分类器难以学习到有区分度的信息。
技术实现思路
1、为此,本发明所要解决的技术问题在于克服现有技术中软件缺陷预测数据中缺陷数据和非缺陷数据不平衡、且现有方法构造的新数据存在噪声的问题。
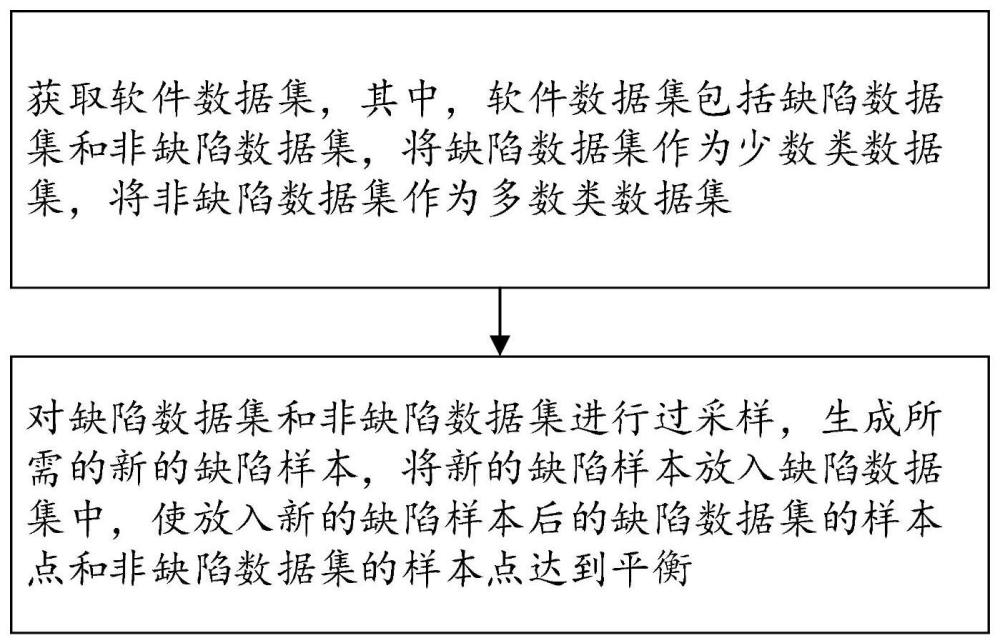
2、为解决上述技术问题,本发明提供了一种软件缺陷数据生成方法,包括:
3、步骤s1:获取软件数据集,其中,所述软件数据集包括缺陷数据集和非缺陷数据集,将所述缺陷数据集作为少数类数据集,将所述非缺陷数据集作为多数类数据集;
4、步骤s2:对所述缺陷数据集和非缺陷数据集进行过采样,生成所需的新的缺陷样本,将新的缺陷样本放入缺陷数据集中,使放入新的缺陷样本后的缺陷数据集的样本点和非缺陷数据集的样本点达到平衡。
5、在本发明的一个实施例中,所述步骤s1还包括:根据获取的软件数据集,计算所需生成的新的缺陷样本个数的方法,具体为:
6、获取软件数据集d={(xi,yi)|xi∈rd,yi∈{0,1},i=1,...,n},其中,n表示软件数据的个数,d表示软件数据的特征数,xi表示第i条软件数据,yi是xi的标签,若yi=0,则xi为非缺陷数据;若yi=1,则xi为缺陷数据;
7、令d=dmin∪dmaj,其中,dmaj为多数类数据集,其样本数记为nmaj;dmin为少数类数据集,其样本数记为nmin,并且nmaj>nmin;
8、令所需生成的新的缺陷样本个数表示为nnew=nmaj-nmin。
9、在本发明的一个实施例中,所述步骤s2中对所述缺陷数据集和非缺陷数据集进行过采样,生成所需的新的缺陷样本个数,方法包括:
10、对所述少数类数据集dmin进行预处理,得到安全样本危险样本和去掉噪声样本后的少数类数据集d′min;
11、对所述多数类数据集dmaj进行预处理,得到去掉噪声后的多数类数据集d′maj,并基于d′maj生成非缺陷边界数据集合bmaj;
12、根据所述非缺陷边界数据集合bmaj,计算所述安全样本中被选取作为所需生成的新的缺陷样本点的选择概率;
13、对所述危险样本聚类生成聚类子簇,并对所述聚类子簇分配权重wc;
14、根据安全样本的数量、危险样本的数量、非缺陷边界数据集合bmaj、选择概率和权重wc生成所需的新的缺陷样本个数。
15、在本发明的一个实施例中,所述对所述少数类数据集dmin进行预处理,得到安全样本危险样本和去掉噪声样本后的少数类数据集d′min,方法包括:
16、在所述软件数据集d中寻找每个样本xi∈dmin的k个近邻样本,k为预设参数;
17、对于每个样本xi∈dmin,统计其k个近邻样本中多数类样本的个数m1,并设定阈值k1,若k=m1,则xi被认为是噪声样本;若m1<k1,则xi被认为是安全样本,否则xi被认为是危险样本;
18、由所有安全样本构成的集合记为其样本点个数记为由所有危险样本构成的集合记为其样本点个数记由关于xi所有噪声样本构成的集合记为
19、令为去掉噪声样本后的少数类数据集,并且记为d′min中样本的个数。
20、在本发明的一个实施例中,所述对所述多数类数据集dmaj进行预处理,得到去掉噪声后的多数类数据集d′maj,并基于d′maj生成非缺陷边界数据集合bmaj,方法包括:
21、在所述软件数据集d中寻找每个样本xj∈dmaj的k个近邻样本,统计k个近邻样本中少数类样本的个数m2;
22、对于每个样本xj∈dmaj,若m2=k,则xj被认为是噪声样本;
23、由关于xj所有噪声样本构成的集合记为其样本点个数记为令为去掉噪声样本后的多数类数据集,且其样本点个数为
24、在数据集合d′maj中寻找每个样本的k2个近邻样本,并将其都放入到非缺陷边界数据集合bmaj中。
25、在本发明的一个实施例中,所述根据所述非缺陷边界数据集合bmaj,计算所述安全样本中被选取作为所需生成的新的缺陷样本点的选择概率,方法包括:
26、对每个样本计算其选择概率sp(xi),公式为:
27、
28、其中,sw(xi)表示样本xi的相对重要程度,公式为:
29、sw(xi)=f(xi)×g(xi)
30、f(xi)表示样本xi与非缺陷边界数据集bmaj的接近程度,公式为:
31、
32、其中,f(xi,xj)表示样本xi与xj∈bmaj的接近程度,公式为:
33、
34、d(xi,xj)表示样本xi与xj之间的欧氏距离;
35、g(xi)表示样本xi相对于非缺陷边界数据集bmaj的密度,公式为:
36、
37、g(xi,xj)表示样本与xj∈bmaj的距离,公式为:
38、
39、其中,m是用户自定义的参数。
40、在本发明的一个实施例中,所述对所述危险样本聚类生成聚类子簇,并对所述聚类子簇分配权重wc,方法包括:
41、将危险样本进行k-means聚类,生成nc个聚类子簇;
42、计算每个聚类子簇在危险样本中的相对权重,公式为:
43、
44、其中,表示第c个聚类子簇的样本数量。
45、在本发明的一个实施例中,所述根据安全样本的数量、危险样本的数量、非缺陷边界数据集合bmaj、选择概率和权重wc生成所需的新的缺陷样本个数,方法包括:
46、根据所述安全样本和危险样本的数量,计算安全样本和危险样本分别需要生成新的样本数量和公式为:
47、
48、
49、根据每个聚类子簇在中的相对权重wc,计算每个聚类子簇需要生成新的样本数量其中,表示第c个聚类子簇需要生成新的样本数量,公式为:
50、
51、对于安全样本的新样本生成:先根据选择概率在集合中选择一个少数类安全样本,设为xi;然后从非缺陷边界数据集合bmaj中随机选择一个多数类边界样本,设为xj;对这两个样本进行特征插值,公式为:
52、
53、其中,表示生成新样本的第k个特征值,插值系数α∈(0,1)是随机生成的,重复该步骤直到安全样本点的新生成样本数量达到令安全样本新生成样本集合为
54、对于危险样本的新样本生成:对缺陷危险数据集合的第c个聚类子簇进行如下操作:在该聚类子簇中随机选择两个样本点xi、xj,按照公式进行特征插值;重复此过程,直到该聚类子簇中新生成的样本个数达到令危险样本新生成样本集合为
55、最终,获得新生成的缺陷数据样本集合
56、在本发明的一个实施例中,若则无论nc的值为多少,都只能生成1个聚类子簇。
57、为解决上述技术问题,本发明提供了一种软件缺陷数据生成系统,包括:
58、获取模块:用于获取软件数据集,其中,所述软件数据集包括缺陷数据集和非缺陷数据集,将所述缺陷数据集作为少数类数据集,将所述非缺陷数据集作为多数类数据集;
59、过采样模块:用于对所述缺陷数据集和非缺陷数据集进行过采样,生成所需的新的缺陷样本,将新的缺陷样本放入缺陷数据集中,使放入新的缺陷样本后的缺陷数据集的样本点和非缺陷数据集的样本点达到平衡。
60、本发明的上述技术方案相比现有技术具有以下优点:
61、本发明通过构造出的新的缺陷数据集,能够将软件数据集中的缺陷数据集(少数类数据集)和非缺陷数据集(多数类数据集)达到平衡,并去除了噪声的影响,保证后期模型训练及预测的有效性;
62、本发明构造出的新的缺陷数据集能够使得用于软件缺陷预测的模型学习到有区分度的信息,保证模型的高效性。
- 还没有人留言评论。精彩留言会获得点赞!