通过梯度稀疏从祖先选择学习基因构建后代模型的方法
本发明涉及通过梯度稀疏从祖先选择学习基因构建后代模型的方法,属于计算机视觉。
背景技术:
1、深度神经网络在各种计算机视觉任务中取得了巨大进展,但是这些成就离不开大规模数据集和大规模的模型。尤其是在当今这个时代,很多资金雄厚计算资源丰富的公司训练的模型大部分都是十亿级别的参数。对于计算资源有限的中小企业来说,甚至都无法通过微调来使用这些模型来解决特定任务,更不用说计算资源少得多的高校学术研究小组。因此迫切需要找到一种方法,可以帮助这些小公司和高校研究组来通过这些大模型构建一些小模型,以一种更加有效的方式来解决特定任务。在生物的进化过程中,生物可以把祖先们积累的经验和知识存储在基因中,使得继承基因的新生后代们能够快速的适应各种不同的环境生活。从一个经过一系列任务数据集训练的祖先模型中找到这些任务的共性知识,类似于生物学“基因”的知识,用来初始化后代模型,使得后代模型能够适应各种不同的新任务。并且后代模型在比较少的数据量就能到达跟随机初始化模型一样的表现效果。
2、目前也有一些知识迁移的学习范式:①迁移学习,将源域数据集上训练的模型知识迁移到目标域数据任务上。“预训练再微调”是迁移学习常见的一种方法,先预训练一个比较大的模型,对这个大模型进行一些调整,比如说加一些连接层等。这种情况下,源域数据集上的模型和目标域上的模型规模是一样的。②元学习,“学习如何学习”。模型通过一系列的任务学习,总结这些任务的经验知识去更好的适应新任务。但是元学习需要同时训练这些任务,任务之间有交互,不能保护这些任务之间的隐私性。而且元学习是把训练好的完整模型应用到下游任务。③模型压缩,将大模型里面的知识蒸馏压缩到一个小模型上,模型压缩虽然可以用小模型来解决下游任务,但是这个小模型的泛化能力不是很好。一般情况下,有多少个不同的下游任务,它就需要进行多少次模型压缩,因此需要消耗比较多的计算资源。
技术实现思路
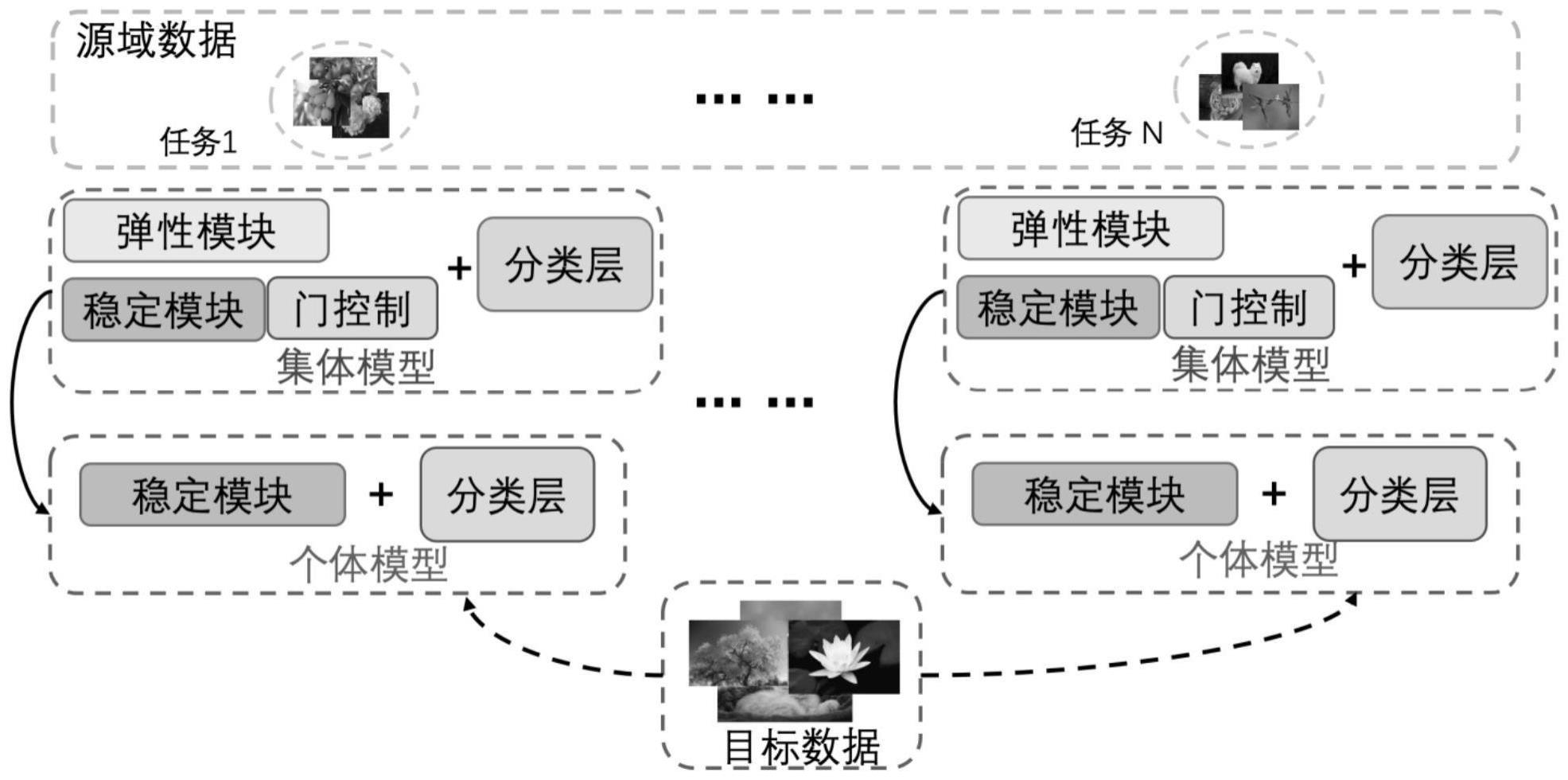
1、针对现在大数据大模型时代中,如何在有限的资源基础上利用大模型更好地去实现各种不同的下游任务的问题,本发明提出了一种通过梯度稀疏从祖先选择学习基因构建后代模型的方法。学习基因也就是祖先模型在一系列任务训练过程中,祖先模型积累的任务的共性知识。在一系列任务的训练过程中,祖先模型的参数会发生变化来适应新任务的学习,本发明通过梯度稀疏的方式从祖先模型中获取学习基因。本发明构建一个由稳定模块和弹性模块组成的祖先模型,祖先模型是在一系列的任务上学习。在这个学习过程中,弹性模块的所有参数都参与训练,稳定模块参数的更新受到模块“门控制”的约束。模块“门控制”用来选择稳定模块中的参数是否进行更新,使得稳定模块在一系列的任务上训练的过程中能够保存任务的共性知识,也就是将学习基因保存下来。模块“门控制”的参数在训练过程,根据不同的任务自适应修改参数,有选择的将任务之间的共性参数保留下来。祖先模型在提出的分类损失函数和蒸馏损失函数对模型进行训练。在祖先模型结束训练以后,后代模型是由祖先模型的稳定模块和一些随机参数进行初始化。
2、为了达到上述目的,本发明提供如下技术方案:
3、通过梯度稀疏从祖先选择学习基因构建后代模型的方法,包括如下步骤:
4、构建包含稳定模块和弹性模块的祖先模型;稳定模块的参数是通过梯度稀疏选择的祖先模型见过的所有任务的共性知识,能够用来适应各种下游任务,作为祖先模型的学习基因库;弹性模块的参数是用来适应新任务,获取新任务的知识;后代模型通过祖先模型的稳定模块来初始化;使用“门控制”模块对稳定模块的梯度进行稀疏处理,用来保留所有见过任务的共性参数,构建学习基因库,使得由稳定模块初始化的后代模型能够更好地适应新的任务。
5、进一步的,具体包括如下步骤:
6、s1,构建了祖先模型,其中包含稳定模块和弹性模块稳定模块里面的参数在训练不同任务的时候是有选择的保留和更新;弹性模块的所有参数都进行更新,用来适应新任务的知识;
7、s2,在目标数据ds中的第n个task的中的某一个数据点输入到祖先模型的时,分别获得由稳定模块和弹性模块抽取的特征表示:和
8、s3,在步骤s2中获得的两个特征表示以后,加权输入到祖先模型的分类层中进行训练,这两个特征表示的权重和公式如下:
9、
10、其中,α是超参数,用来权衡稳定模块和弹性模型输出的特征比重;
11、s4,为了实现步骤s1中祖先模型的稳定模块可以不断积累新任务和过去学习的任务中的共性知识,即学习基因,设计了“门控制”模块φ,“门控制”模块作用在祖先模型的稳定模块上,用来保留祖先模型见过的所有任务的共性参数,建立一个学习基因库;“门控制”模块是一个矩阵,作用在稳定模块的梯度上,对稳定模型的梯度有稀疏作用,用于决定稳定模型的参数是否进行更新,其公式如下:
12、
13、其中,μm,i表示的是在第i次迭代更新的时候稳定模块的参数,是指示函数,表示的是实数空间,是点乘积,γ是学习率,是祖先模型训练过程的损失函数;
14、s5,经过步骤s3获得的特征表示输入到祖先模型的分类层进行训练;祖先模型训练的损失函数包括了两个部分,其中一个是分类损失函数,使得祖先模型有比较好的分类结果,公式如下:
15、
16、其中,是数据点的正确标记,δ是指示函数,σh是分类层对于第h个类的预测数值;
17、另一个损失函数是蒸馏损失函数,使得祖先模型在新的任务和之前的任务上保存的知识具有一致性,也就是祖先模型保存了见过的所有任务的共性知识,即学习基因,公式如下:
18、
19、其中,并且表示的是上一个任务分类层对第h个类的预测数值,τ是一个超参数;
20、所以祖先模型训练的损失函数是:
21、
22、s6,在步骤s5中所提到的祖先模型损失函数中,需要优化的参数有两组,分别是[μm,μc]和φ,其中参数μm的更新是受到参数φ的约束,两组参数不能同时优化;因此,对于第n个任务来说,祖先模型在训练过程中的优化目标函数是:
23、
24、
25、即祖先模型训练的时候,参数[μm,μc]和φ的优化分为两个阶段;
26、s7,在步骤s6中,祖先模型的优化过程分为两个阶段,针对两个优化阶段的特性,两个优化阶段所使用的数据集有所区别。在训练祖先模型的时候,稳定模块和弹性模块用于抽取数据特征,在优化参数[μm,μc]的时候使用的当前所有的数据“门控制”模块用于保存稳定模块中的共性知识,为了防止每个类别的数据不均衡导致训练的时候出现偏差,在优化“门控制”模块参数时,使用的数据集是其中是从中抽取出来数据,保证每个类别的数据数目一样;
27、步骤s8,在步骤s7中,针对两个优化阶段的特性,对每个步骤优化阶段使用不同的数据集;因此所述步骤s5中的祖先模型的优化函数发生变化,如下公式所示:
28、
29、
30、s9,在步骤s6训练结束以后,祖先模型在稳定模块上构建了一个学习基因库;利用祖先模型中的稳定模块构建适应其他不同任务的后代模型ht;后代模型的参数由稳定模块参数和部分随机初始化参数构成;后代模型在它们各自对应的任务上进行训练,训练的损失函数如下:
31、
32、其中,m表示的是目标数据集的类别数目,是目标数据集dt上的一个数据点。
33、进一步的,稳定模块和弹性模块都是由残差块组成,在稳定模块和弹性模块的每一层分别计算稳定模块和弹性模块的特征图,聚合具有自适应权重的图,并将获得的特征值提供给下一层;最终输出的特征值用于训练分类器。
34、本发明还提供了通过梯度稀疏从祖先模型选择学习基因构建后代模型并进行图像分类的方法基于前述的通过梯度稀疏从祖先选择学习基因构建后代模型的方法构建后代模型,将数据集中的类别划分为两部分,一部分类别用于训练祖先模型,另一部分用于测试后代模型;在祖先模型训练的时候,每个任务包含了2个类别,这些任务的类别都不一样;在后代模型测试的时候,是从用于测试后代模型的类别中随机抽取5个类别构成下游分类任务。
35、与现有技术相比,本发明具有如下优点和有益效果:
36、本发明提供一种通过梯度稀疏从祖先模型选择学习基因并构建后代模型的方法,通过梯度稀疏的方式从祖先模型中获取学习基因,用学习基因构建后代模型的算法,并且用后代模型在各种不同的任务上使用。后代模型可以用来解决祖先模型从未见过的各种不同新任务。本发明是在一系列任务上不断训练祖先模型,积累各种不同任务之间的共性知识,构建一个学习基因参数库。由这个学习基因参数库所初始化的后代模型,跟随机初始化参数的同等大小模型相比,后代模型在新任务上使用更少的数据量就能达到同等的性能效果,并且在训练过程中也具有更快收敛的特性。后代模型的任务是在祖先模型从未见过的。祖先模型的训练任务和后代模型应用的任务没有重叠,祖先模型和后代模型之间没有数据交互,极大的保护了下游客户端的数据隐私性。
- 还没有人留言评论。精彩留言会获得点赞!