一种面向软件变更的适应性弱点检测方法
本发明属于网络安全领域。
背景技术:
1、微服务架构是一种将应用程序构建为松耦合服务集合的架构风格,它凭借灵活的扩展能力和敏捷的开发过程在企业的生产实践中流行开来。采用微服务架构在创造更大价值的同时对服务的可靠性带来了威胁。作为分布式系统,微服务系统的正常运行更容易受到真实生产环境中随机事件的影响,如负载高峰、硬件故障、网络波动等无法预测的扰动事件(disruption)经常造成服务的中断。这些扰动事件导致服务中断的原因包括软件的错误配置、代码的不恰当实现等,这些瑕疵就是关联扰动事件的系统弱点(system weakness),也是降低可靠性的罪魁祸首。软件变更(software change)是引入系统弱点的重要原因,研究表明谷歌70%的云服务故障的直接或者间接原因就是软件变更。
2、现有技术中,analysis-tool需要工程师在混沌实验的过程中全程参与;gremlin和filibuster虽然通过断言检测实现了混沌实验的自动化分析,但是每个系统版本都需要工程师针对不同的扰动事件分别配置断言,自动化程度较低;对规模庞大、变更频繁的微服务系统应用上述三种方法会引起庞大的人力开销。
3、pystol和chaosduck使用统一的行为预期虽然极大地提高了自动化程度,却造成了检测精度的下降,因为指标的复杂模式无法通过阈值范围准确描述,对不同程度的扰动事件设置相同预期也并不合理。此外,上述五种检测方法都需要工程师在软件变更时根据领域知识给出或者更新系统在扰动事件下的行为预期,由于频繁的软件变更会引起领域知识的快速迭代,不同微服务相对独立的开发过程也造成工程师很难把握系统的整体特性,因此借助人力给出的预期容易出现错误和遗漏。
4、scwarn和kontrast可以使用变更场景中历史版本的数据构建混沌实验的系统预期,引入的复杂模型虽然保证了自动化程度和检测精度,但引起了新的问题。scwarn训练模型学习历史版本的特定数据模式,但是由于不同的扰动事件造成的影响各不相同,扰动下的数据模式存在差异,因此应用scwarn时必须针对不同的扰动事件分别训练模型,开销过大。kontrast使用自监督对比学习的方法构建了对不同数据模式具备适应性的模型,在实践中虽然可直接用于分析其他的扰动事件,但会导致检测精度的下降,kontrast没有对检测精度下降的问题做出进一步优化。
技术实现思路
1、本发明旨在至少在一定程度上解决相关技术中的技术问题之一。
2、为此,本发明的目的在于提出一种面向软件变更的适应性弱点检测方法,用于在软件变更时检测系统弱点。
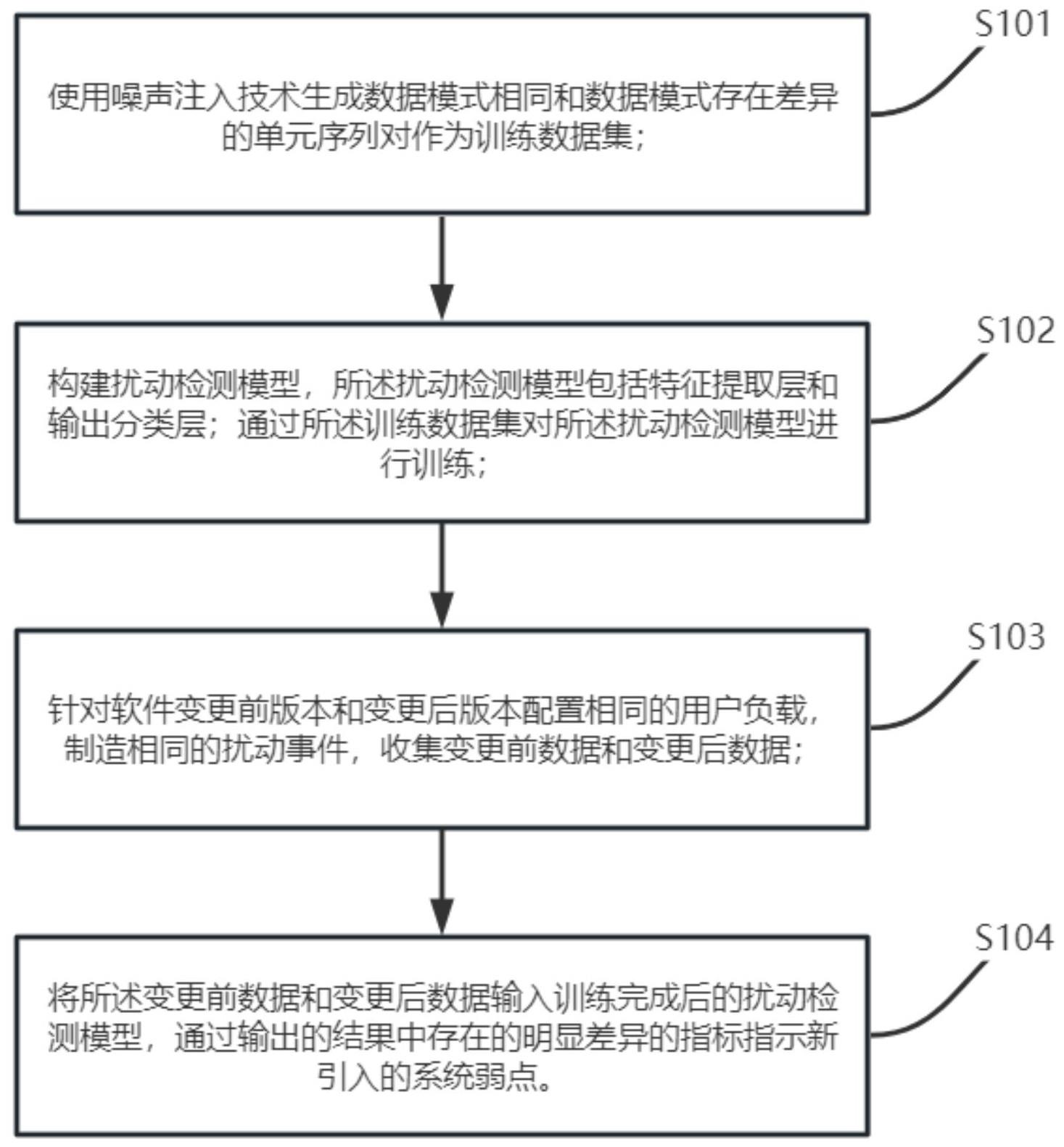
3、为达上述目的,本发明第一方面实施例提出了一种面向软件变更的适应性弱点检测方法,包括:
4、使用噪声注入技术生成数据模式相同和数据模式存在差异的单元序列对作为训练数据集;
5、构建扰动检测模型,所述扰动检测模型包括特征提取层和输出分类层;通过所述训练数据集对所述扰动检测模型进行训练;
6、针对软件变更前版本和变更后版本配置相同的用户负载,制造相同的扰动事件,收集变更前数据和变更后数据;
7、将所述变更前数据和变更后数据输入训练完成后的扰动检测模型,通过输出的结果中存在的明显差异的指标指示新引入的系统弱点。
8、另外,根据本发明上述实施例的一种面向软件变更的适应性弱点检测方法还可以具有以下附加的技术特征:
9、进一步地,在本发明的一个实施例中,所述使用噪声注入技术生成数据模式相同和数据模式存在差异的单元序列对作为训练数据集,包括:
10、用噪声强度定量描述噪声模式,时间序列的噪声强度定义为时间序列不同周期的同一个时间点的数值标准差的均值,具体计算过程为:
11、 ,
12、 ,
13、 ,
14、其中,表示时间序列包含的周期数,表示时间序列周期的长度,表示单个时间点在不同周期的均值,表示单个时间点在不同周期的标准差,对应单个时间点的噪声强度;一个周期内所有时间点噪声强度的均值就是时间序列的噪声强度;
15、设置统一的噪声强度,对于具体的时间序列,放缩的计算定义为:
16、,
17、将放缩后的时间序列作为训练数据集。
18、进一步地,在本发明的一个实施例中,所述通过所述训练数据集对所述扰动检测模型进行训练,包括:
19、使用交叉熵函数计算损失,使用0标签指示二元序列对应的序列对模式无差异,1标签指示有差异,交叉熵损失的计算方法为:
20、,
21、其中,对应时间序列对的真实标签,对应分类模型输出的标签概率。
22、进一步地,在本发明的一个实施例中,所述通过所述训练数据集对所述扰动检测模型进行训练,还包括引入批归一化的技术处理输入的二元时间序列,包括:
23、对输入的每个维度计算批次的经验均值和方差;
24、使用所述经验均值和方差重新给出新的输入。
25、进一步地,在本发明的一个实施例中,在将所述变更前数据和变更后数据输入训练完成后的扰动检测模型,通过输出的结果中存在的明显差异的指标指示新引入的系统弱点之后,还包括通过量化比较执行进一步的判断,包括:
26、对扰动检测模型输入三个序列对:变更前版本的扰动序列和变更后版本的扰动序列、变更前版本的正常序列和变更前版本的扰动序列、变更前版本的正常序列和变更后版本的扰动序列;
27、通过所述扰动检测模型输出的标签概率量化所述序列对的相似度:对应标签的概率越大,序列对的差异程度越大;
28、当所述变更前版本和所述变更后版本的扰动序列对存在差异时,进一步比较两个版本的扰动序列和所述变更前版本正常序列的相似度,如果所述变更后版本较所述变更前版本的扰动序列和所述更前版本的正常序列模式存在更大差异,则表明差异指标指示了一个新引入的系统弱点,否则表明软件可靠性通过变更得到增强。
29、进一步地,在本发明的一个实施例中,还包括:
30、在将训练好的扰动检测模型应用到其他扰动事件前,使用待检测扰动事件的数据集生成规模更小的训练数据微调分类层参数。
31、为达上述目的,本发明第二方面实施例提出了一种面向软件变更的适应性弱点检测装置,包括以下模块:
32、生成模块,用于使用噪声注入技术生成数据模式相同和数据模式存在差异的单元序列对作为训练数据集;
33、构建模块,用于构建扰动检测模型,所述扰动检测模型包括特征提取层和输出分类层;通过所述训练数据集对所述扰动检测模型进行训练;
34、获取模块,用于针对软件变更前版本和变更后版本配置相同的用户负载,制造相同的扰动事件,收集变更前数据和变更后数据;
35、指示模块,用于将所述变更前数据和变更后数据输入训练完成后的扰动检测模型,通过输出的结果中存在的明显差异的指标指示新引入的系统弱点。
36、为达上述目的,本发明第三方面实施例提出了一种计算机设备,其特征在于,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现如上所述的一种面向软件变更的适应性弱点检测方法。
37、为达上述目的,本发明第四方面实施例提出了一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如上所述的一种面向软件变更的适应性弱点检测方法。
38、本发明实施例提出的面向软件变更的适应性弱点检测方法,设计了面向软件变更的弱点检测自动化流程,解决了人工检测方法耗时且易错的问题,显著减少运维人员的工作负担,实现了软件变更时系统的可靠性保证;其次本方案构建的时间序列分类模型可以利用海量的指标数据快速准确地识别模式存在差异的时间序列;分类模型具备的量化相似度的能力可进一步指示系统弱点的存在;本方案设计的放缩方法、微调方法解决了引入复杂模型(scwarn、kontrast)时无法兼顾准确度和效率的问题,在保证检测精度的同时实现了模型的快速构建。
- 还没有人留言评论。精彩留言会获得点赞!